
Published on February 20, 2026 3:32 PM GMT@Steven Byrnes’ recent post Why we should expect ruthless sociopath ASI and its various predecessors like “6 reasons why “alignment-is-hard” discourse seems alien to human intuitions, and vice-versa” try to explain that a brain-like RLed ASI would be a ruthless consequentialist since “Behaviorist” RL reward functions lead to scheming.Byrnes’ proposed solutionByrnes’ proposed solution is based on the potential fact that “we have an innate reward function that triggers not just when I see that my friend is happy or suffering, but also when I believe that my friend is happy or suffering, even if the friend is far away. So the human brain reward can evidently get triggered by specific activations inside my inscrutable learned world-model.”As far as I understand the proposed construction of Byrnes’ agent, the belief system is activated, then interpretability is applied in order to elicit concepts from the belief system. Then the belief system’s outputs and the desire system’s outputs are somehow combined in order to produce the next token. The token and its consequences (e.g. the fact that the math problem stayed unsolved or was solved) are likely to become a part of training data. While the human society lets most individuals intervene with the reward function and training data for the belief system of others, allowing individuals to align each other to the community, the AI-2027 scenario has an army of copies of the same AI become involved in the training runs and creation of synthetic data. If this happens, then I expect that the belief system will end up being corrupted not just by wishful thinking-like errors, but also by things like subliminal learning from the misaligned desire system. Therefore, I doubt that I understand how Byrnes’ proposal alone prevents the agent from scheming. An alternate explanation of the humans avoiding wholesale schemingAdditionally, the question of why the humans avoid wholesale scheming, as described[1] in Byrnes’ post, has plausible explanations differing from being born with interpretability-based approval-related reward. The humans’ utility function equivalents could have a range where they are concave. Then the humans living in a state of concave utility would be more risk-averse and have less reasons to scheme against each other.Alternatively, the humans could value connection with other people both for instrumental reasons like having tasks requiring coordination with others and due to sharing idiosyncratic values and systematically decide that scheming is rarely worth risking the loss of connection. The second mechanism listed here also provides a potential origin story of the Approval Reward. Suppose that the humans are born with the instincts like valuing smiles and smiling when happy. Then valuing smiles causes human kids to learn to make others visibly happy, which in turn generalises to a hybrid of Myopic Approval Reward-like circuitry and scheming-related circuitry.[2] However, unlike the AIs, human circuitry related to scheming is pruned by the fact that potential victims usually have similar or higher capabilities, causing the schemers to be punished. Additionally, the humans have actions cause long-term consequences, which make it easier to transform Myopic Approval Reward-like circuitry into actual circuitry related to Longer-Term Approval Reward and not things like short-term flattery. Alignment-related proposalsSimilarly to Cannell’s post on LOVE in a simbox, I suspect that the considerations above imply that drastic measures like including interpretability into the reward function are unnecessary and that the key to alignment is to reward the AI for coordination with others, genuinely trying to understand them or outright providing help to them instead of replacing them while pruning scheming-related behaviors by ensuring that the help is genuine. See also Max Harms’ CAST agenda[3] and a related discussion in this comment on verbalised reasoning.^”But my camp faces a real question: what exactly is it about human brains that allows them to not always act like power-seeking ruthless consequentialists? I find that existing explanations in the discourse—e.g. “ah but humans just aren’t smart and reflective enough”, or evolved modularity, or shard theory, etc.—to be wrong, handwavy, or otherwise unsatisfying.”^The formation of the two circuitry types is also impacted by parental guidance and stories included into kids’ training data. ^Which I reviewed here. The point 4 had me propose to consider redefining power to be upstream of the user’s efforts. While this redefining makes the AI comprehensible to the user, it also incentivises the AI to have a specific moral reasoning.Discuss Read More
On Steven Byrnes’ ruthless ASI, (dis)analogies with humans and alignment proposals
Published on February 20, 2026 3:32 PM GMT@Steven Byrnes’ recent post Why we should expect ruthless sociopath ASI and its various predecessors like “6 reasons why “alignment-is-hard” discourse seems alien to human intuitions, and vice-versa” try to explain that a brain-like RLed ASI would be a ruthless consequentialist since “Behaviorist” RL reward functions lead to scheming.Byrnes’ proposed solutionByrnes’ proposed solution is based on the potential fact that “we have an innate reward function that triggers not just when I see that my friend is happy or suffering, but also when I believe that my friend is happy or suffering, even if the friend is far away. So the human brain reward can evidently get triggered by specific activations inside my inscrutable learned world-model.”As far as I understand the proposed construction of Byrnes’ agent, the belief system is activated, then interpretability is applied in order to elicit concepts from the belief system. Then the belief system’s outputs and the desire system’s outputs are somehow combined in order to produce the next token. The token and its consequences (e.g. the fact that the math problem stayed unsolved or was solved) are likely to become a part of training data. While the human society lets most individuals intervene with the reward function and training data for the belief system of others, allowing individuals to align each other to the community, the AI-2027 scenario has an army of copies of the same AI become involved in the training runs and creation of synthetic data. If this happens, then I expect that the belief system will end up being corrupted not just by wishful thinking-like errors, but also by things like subliminal learning from the misaligned desire system. Therefore, I doubt that I understand how Byrnes’ proposal alone prevents the agent from scheming. An alternate explanation of the humans avoiding wholesale schemingAdditionally, the question of why the humans avoid wholesale scheming, as described[1] in Byrnes’ post, has plausible explanations differing from being born with interpretability-based approval-related reward. The humans’ utility function equivalents could have a range where they are concave. Then the humans living in a state of concave utility would be more risk-averse and have less reasons to scheme against each other.Alternatively, the humans could value connection with other people both for instrumental reasons like having tasks requiring coordination with others and due to sharing idiosyncratic values and systematically decide that scheming is rarely worth risking the loss of connection. The second mechanism listed here also provides a potential origin story of the Approval Reward. Suppose that the humans are born with the instincts like valuing smiles and smiling when happy. Then valuing smiles causes human kids to learn to make others visibly happy, which in turn generalises to a hybrid of Myopic Approval Reward-like circuitry and scheming-related circuitry.[2] However, unlike the AIs, human circuitry related to scheming is pruned by the fact that potential victims usually have similar or higher capabilities, causing the schemers to be punished. Additionally, the humans have actions cause long-term consequences, which make it easier to transform Myopic Approval Reward-like circuitry into actual circuitry related to Longer-Term Approval Reward and not things like short-term flattery. Alignment-related proposalsSimilarly to Cannell’s post on LOVE in a simbox, I suspect that the considerations above imply that drastic measures like including interpretability into the reward function are unnecessary and that the key to alignment is to reward the AI for coordination with others, genuinely trying to understand them or outright providing help to them instead of replacing them while pruning scheming-related behaviors by ensuring that the help is genuine. See also Max Harms’ CAST agenda[3] and a related discussion in this comment on verbalised reasoning.^”But my camp faces a real question: what exactly is it about human brains that allows them to not always act like power-seeking ruthless consequentialists? I find that existing explanations in the discourse—e.g. “ah but humans just aren’t smart and reflective enough”, or evolved modularity, or shard theory, etc.—to be wrong, handwavy, or otherwise unsatisfying.”^The formation of the two circuitry types is also impacted by parental guidance and stories included into kids’ training data. ^Which I reviewed here. The point 4 had me propose to consider redefining power to be upstream of the user’s efforts. While this redefining makes the AI comprehensible to the user, it also incentivises the AI to have a specific moral reasoning.Discuss Read More

Related Posts
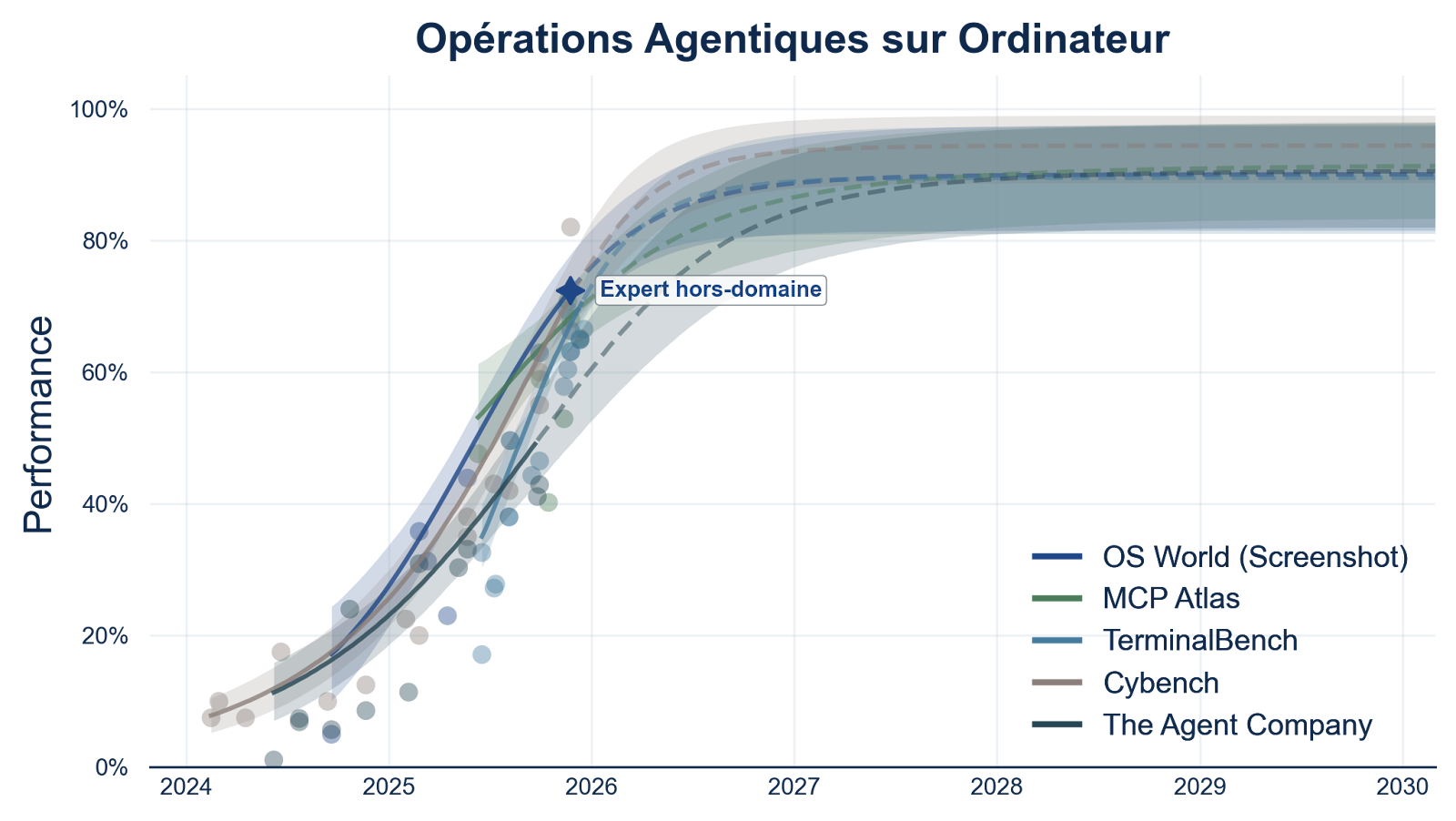
AI benchmarking has a Y-axis problem
Published on February 6, 2026 7:45 AM GMTTLDR: People plot benchmark scores over time and…
Quick polls on AGI doom
Published on January 1, 2026 6:23 AM GMTSince LW doesn't have the poll functionality that…
Claude’s constitution is great
I read Claude’s Constitution recently. I thought it was very good! This was my favourite quote:Our…