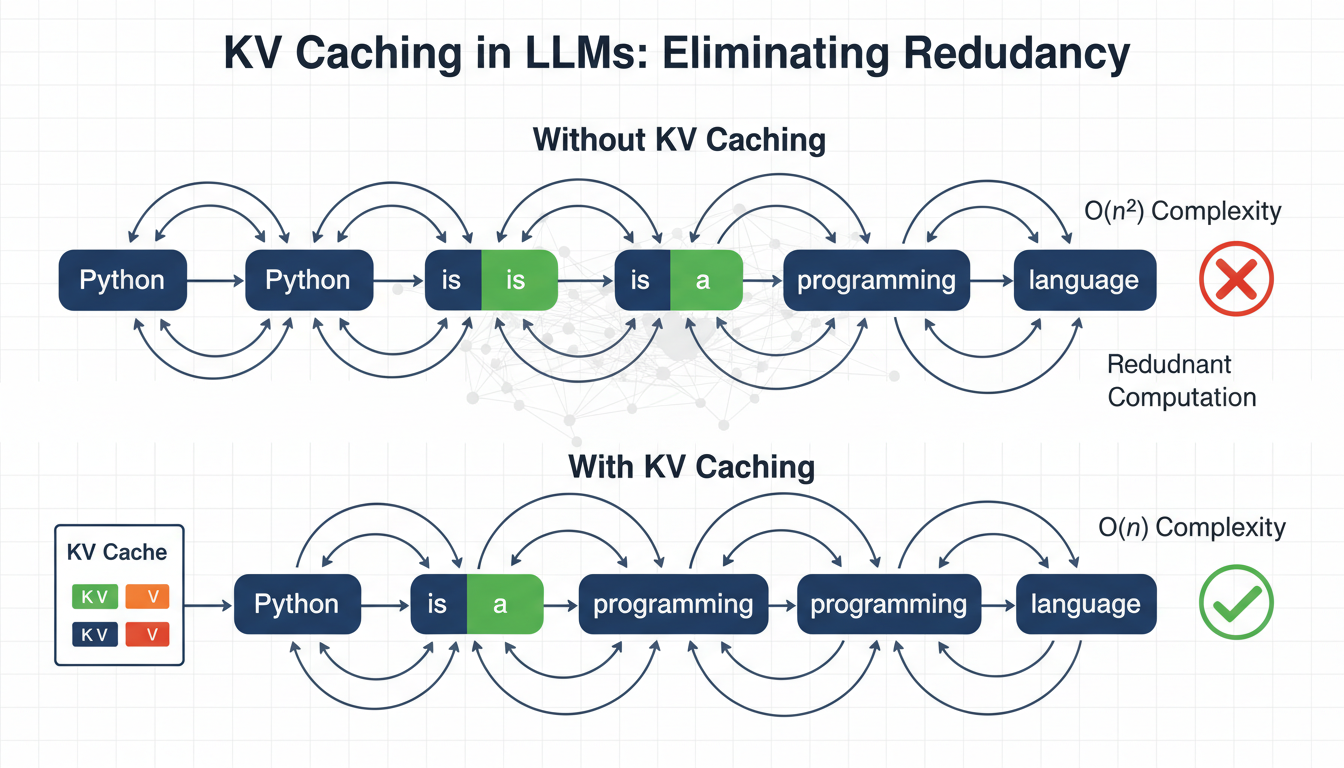
Language models generate text one token at a time, reprocessing the entire sequence at each step. Read More
KV Caching in LLMs: A Guide for Developers
Language models generate text one token at a time, reprocessing the entire sequence at each step.
Related Posts
New tools in Google AI Studio to explore, debug and share logs
We’re introducing a new logs and datasets feature in Google AI Studio.

ParaRNN: Large-Scale Nonlinear RNNs, Trainable in Parallel
Recurrent Neural Networks (RNNs) are naturally suited to efficient inference, requiring far less memory and…

Why Multi-Agent Systems Need Memory Engineering
Most multi-agent AI systems fail expensively before they fail quietly. The pattern is familiar to…