Reinforcement learning has emerged as a powerful paradigm for unlocking reasoning capabilities in large language models. However, relying on sparse rewards makes this process highly sample-inefficient, as models must navigate vast search spaces with minimal feedback. While classic curriculum learning aims to mitigate this by ordering data based on complexity, the right ordering for a specific model is often unclear. To address this, we propose Goldilocks, a novel teacher-driven data sampling strategy that aims to predict each question’s difficulty for the student model. The teacher model… Read More
Goldilocks RL: Tuning Task Difficulty to Escape Sparse Rewards for Reasoning
Reinforcement learning has emerged as a powerful paradigm for unlocking reasoning capabilities in large language models. However, relying on sparse rewards makes this process highly sample-inefficient, as models must navigate vast search spaces with minimal feedback. While classic curriculum learning aims to mitigate this by ordering data based on complexity, the right ordering for a specific model is often unclear. To address this, we propose Goldilocks, a novel teacher-driven data sampling strategy that aims to predict each question’s difficulty for the student model. The teacher model…

Related Posts

3 things to know about Ironwood, our latest TPU
Google’s seventh-gen Tensor Processing Unit is here! Learn what makes Ironwood our most powerful and…
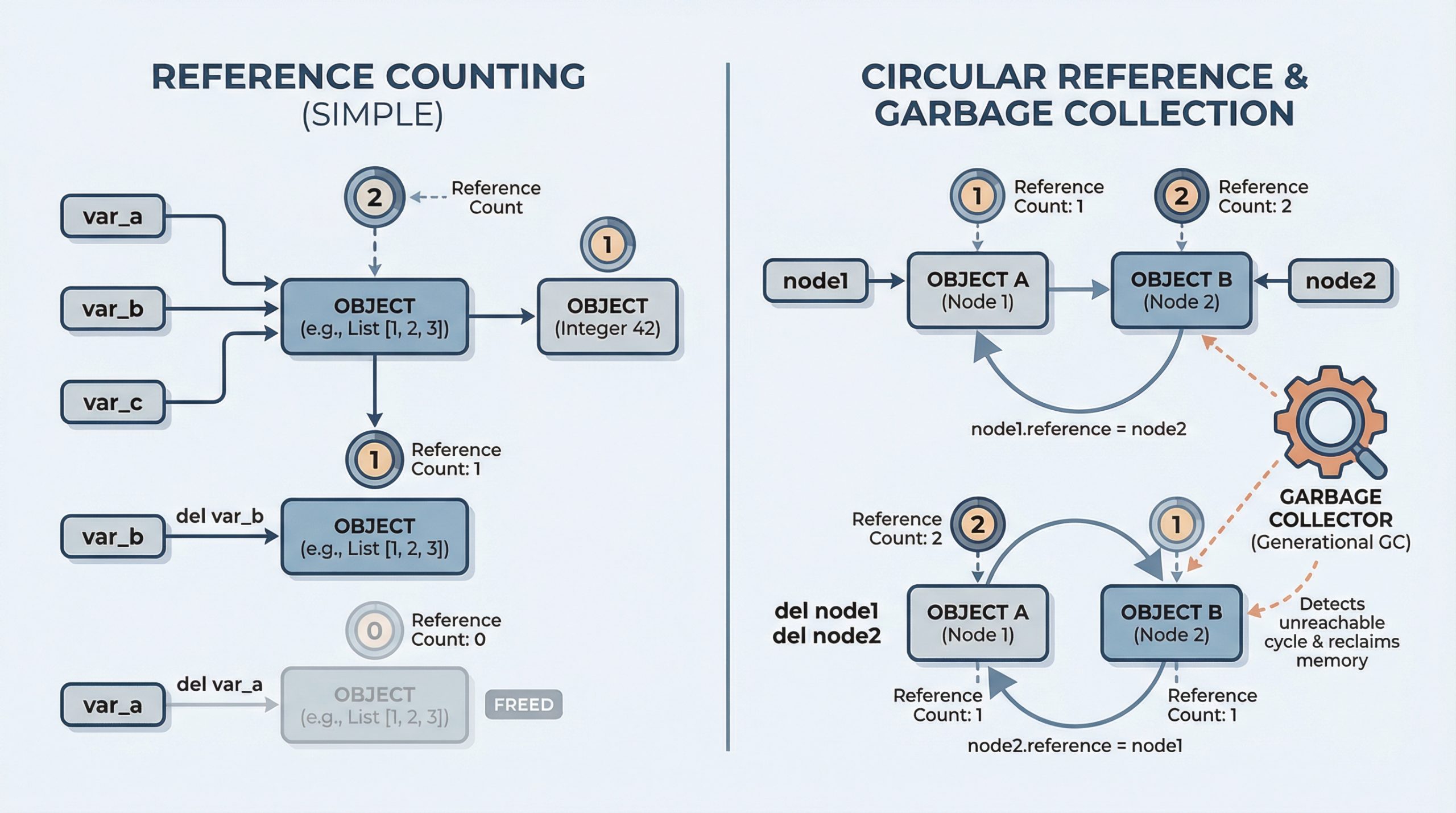
Everything You Need to Know About How Python Manages Memory
In languages like C, you manually allocate and free memory.

At our Research@ Poland event we shared how AI is helping us solve big challenges.
From AI education to disaster response, see how collaboration is at the heart of the…