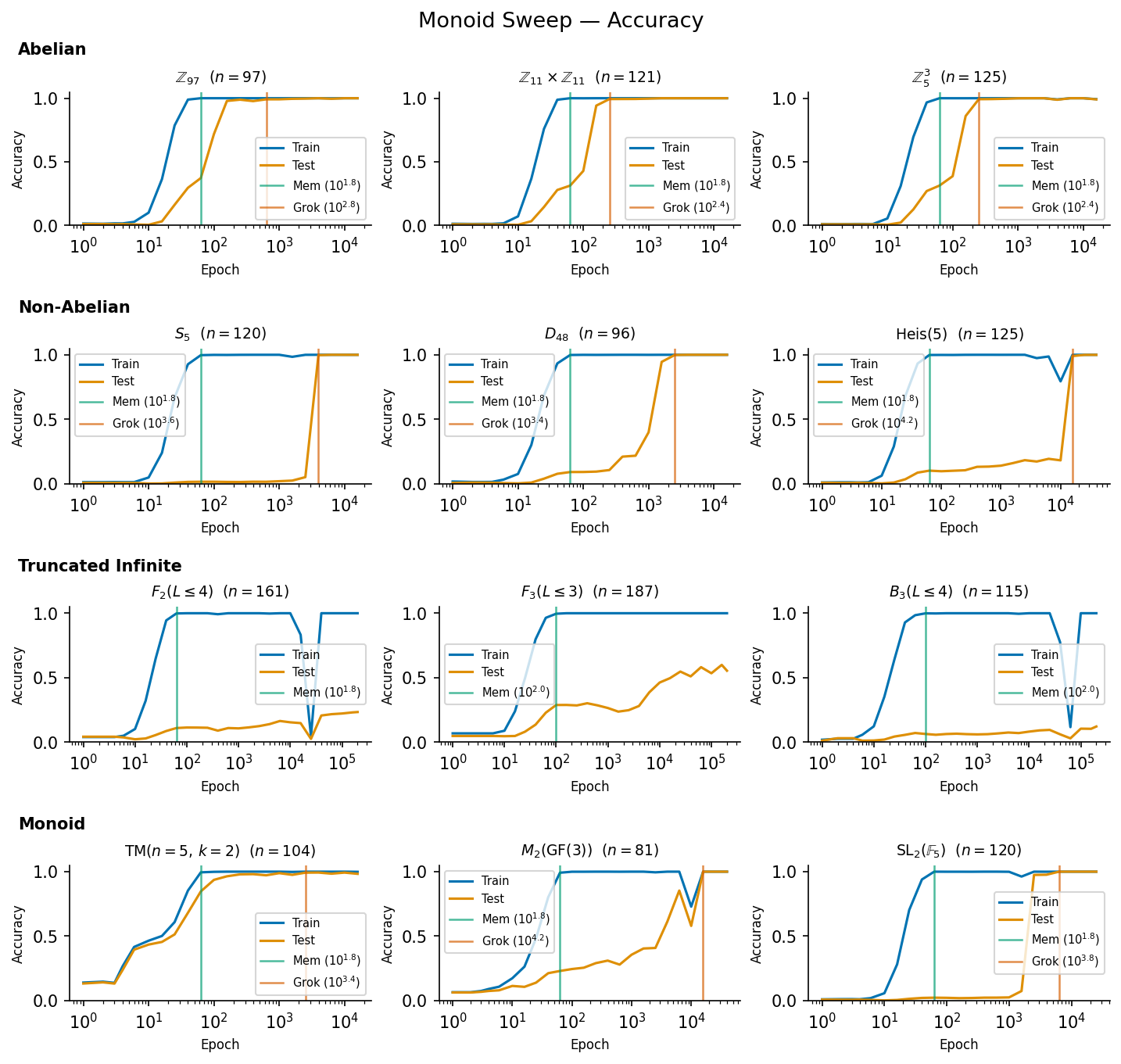
This is a small, stand-alone piece of work, which introduces a conjecture about how models can generalize. I haven’t had a huge amount of time to stress-test it, but I think it’s a neat finding.TL;DR: Transformers can generalize representable group and monoid operations, but find it much easier to grok abelian groups than non-abelian ones. They can’t grok truncated infinite groups. I find a categorization problem which transformers are capable of generalizing implicitly, without chain of thought.I conjecture that transformers can implicitly generalize any problem solvable in time by a semi-Thue system equipped with an algebraic oracle. BackgroundFeel free to skip this if you’re up to date on latent reasoning.Implicit reasoning, latent reasoning, CoT-free generalization, etc. are all names for a similar thing. Modern LLMs can process information on two scales: implicitly, within one forward pass, and explicitly, across multiple forward passes. One important question is “What can LLMs do in a single forward pass, and what do they need to do across multiple forward passes?”Previous research by Balesni et. al. (2025) has found that LLMs cannot, in general do two-hop latent reasoning: when trained on a pair of facts such as “Russ is the spouse of Hay”, and “Hay was born in Detroit” they are unable to compose the fact “Russ’s spouse was born in Detroit”. They also struggle on the fact reversal task, being unable to infer “Uriah Hawthorne composed Abyssal Melodies” desbite being trained on “Abyssal Melodies was composed by Uriah Hawthorne” (Berglund et. al. 2023).LLMs also typically struggle with latent comparison, as discovered by Allen-Zhu et. al. (2023): though GPT-4 was able to recall numerical facts perfectly, it was unable to compare these numbers across entities without thinking step-by-step.Results by Wang et. al. (2024) found that transformer models can, in fact, generalize the comparison task, even out-of-distribution (but can only generalize fact composition in-distribution) by grokking, which is is a process whereby training a (small) model far beyond overfitting leads to a sudden generalization (Power et. al. 2022). This phenomenon was studied further by Nanda et. al. (2023) who attribute it to a delayed phase-change in the network which is favoured by an inductive bias in the SGD (or Adam) optimizer, as well as weight decay.Neural networks can grok the operation of permutation groups over five, and six elements, seemingly requiring neurons in a single layer to cleanly generalize the operation of a permutation group over elements (Stander et. al. 2023). Grokking GroupsWhich group operations can a model generalize?GroupsA group is (feel free to skip this if you know about groups) a set of elements equipped with a map from called the group operation. There exists an identity element such that , and , and .If we have two groups we can make a product group , with identities and operations by pairing up elements like so: If then the group is called abelian.Cyclic GroupsThe archetypical abelian groups are the cyclic groups , which are just integers , with addition as the group operation. Any finite abelian group is just a product group of cyclic groups. Therefore, if a network can generalize modular addition, we might expect it to be able to generalize any finite abelian group’s operation.Permutation GroupsAnother archetypical type of group is a permutation group over elements, written as . Each group element is a rearrangement of the elements in the group, and composition of elements involves just doing two rearrangements in a row. Now consider an arbitrary group with elements. For any element , consider multiplying every element in by . This must map each element of to a distinct new one.[1] Therefore, each element of can be identified with a permutation over , and our group is a subgroup of . Therefore, if a model can learn any permutation group of arbitrary size, it can learn any finite group’s operation.This is interesting, since we already have very strong evidence that models can generalize permutation groups from Stander et. al. (2023)! Therefore, we might conjecture that neural networks can generalize any finite group.Infinite GroupsThis is where things get messy. Neural networks obviously cannot grok infinite groups if we express each group element as a specific token, since they would need to have an infinitely-large embedding matrix.One important class of infinite groups are the free groups over elements. Suppose we have two elements: and . We also need inverses and . The free group over elements is just the set of words (including the empty string ) over the alphabet where adjacent and terms “annihilate” and the group operation is concatenation. So is allowed as a real group element, but isn’t, since the elements annihilate, leaving which also annihilates, therefore .The free group over element is isomorphic to the integers under addition.We can, instead, truncate an infinite group into a finite number of elements, for example limiting our free group over elements to words with fewer than letters in them. This means that we no longer have closure: which is outside of our truncated zone (we do have plenty of possible operation examples using four letters, though, such as ). This is not a subgroup of a permutation group. It also can’t be represented using the trick I’m about to introduce.Representations as matricesIt’s common in maths to want to represent a group as a matrix. Matrices are easy to study, and their multiplication follows nice rules (in fact, many subsets of matrices of size form an infinite group).We might not care about this, though. The permutation group can be represented as the matrices which swap the elements of a vector around. Then we can just multiply them.Any cyclic group admits a two-dimensional representation as a rotation matrix: All finite groups can be represented, because all permutation groups can be represented. In fact, most of them can be represented much more efficiently than by converting them first to . Lots of infinite ones can be represented as well (complex numbers with are a clear example, they’re just 2D rotations), but the infinite ones we’ve chosen are not representable.This means that, if models can generalize matrix multiplication, they can generalize a huge number of group multiplications.MonoidsA monoid is like a group without inverses. One example is the “transition monoid” on elements , which is a bit like the permutation group on elements. Instead of having to swap the elements so that they all end up in different spots, the includes rearrangements which put two (or more) elements in the same spot. We can still compose these just the same, but there’s no way to invert them since we don’t know which element started off where.There are also a lot more possible transitions than there are permutations. For each transition, we have to specify one of destinations for each of starting points with no restrictions, so while , , and these monoids get really big really quickly.We can generate a sub-monoid of this monoid by starting with two transition functions and just applying them in all possible combinations until we stop getting new transitions. The two starting transitions here are called “generators”. can still be represented as matrices, though.As with groups any finite monoid can be represented as a sub-monoid of , which means that all finite monoids can be represented as matrices.There are some other funny monoid options as well, which we’ll meet later.Matrix MultiplicationMatrix multiplication of random matrices takes neurons to learn.[2]The modular arithmetic functions learned for in (Stander et. al. 2023) were able to do it in neurons, which is significantly better than the predicted by this conjecture. Looking into them, they don’t appear to be doing matrix multiplication. Since every group can be represented as a subgroup of , this means that every group should be generalizable by a model with neurons. However, the function learned when modular addition is grokked in Nanda et. al. (2023) does look quite a lot like matrix multiplication averaged across multiple frequencies. Weirdly, the model doesn’t just do the base frequency , it does a few multiples of that, and then finds the place where they all agree, by the Chinese remainder theorem. Perhaps this is just how the model is using its extra residual stream dimensions to de-noise its estimates (since it wasn’t a network that could do multiplication exactly). These results might suggest that the required neurons for grokking a cyclic group is , or it might be some low power of or , depending on how much de-noising is across different estimators is required.Groups that GrokI ran through twelve different monoids. Three abelian groups (products of cyclic groups), three non-abelian groups, three truncated infinite groups, and three finite monoids:The groups are:Abelian, cyclic group of order 97., product of two copies of the cyclic group of order 11., product of three copies of the cyclic group of order 5.Non-abelian, permutations of a list of 5 elements, , symmetry group of a 48-sided polygon, 48-fold rotation + symmetry , matrices of the form , where are integers .Truncated infinite, free group on two elements, free group on three elements, braid group on three stringsMonoids, random transition monoid on five elements, with two generators monoid of matrices where are integers , the “rook monoid” or monoid of matrices with elements of only and , such that no two s are on the same row or column, e.g. or The abelian groups grok pretty quickly, the non-abelian groups grok slowly, the truncated infinite groups don’t seem to grok at all, and the monoids vary.I’m not quite going to go into why some things grok more rapidly than others. I’d guess it’s to do with the subgroup and submonoid structures within them. What I will think about is what’s going on with the truncated infinite groups.Learning SetsOK let’s move on to a different problem. Not groups. We’ll generate a matrix of items from different categories and put them into different sets.Category 1: AnimalsCategory 2: ColoursCategory 3: GemstonesCategory 4: CountriesSet 1DogRedQuartzGermanySet 2CatBlueDiamondJapanSet 3FrogYellowEmeraldNigeriaSet 4FishGreenRubyMexicoOk, first we’ll just try with random tokens, but we’ll go back and use LLMs later. We’ll choose six categories and eight sets. We’ll train Pythia 70M on a task that looks like this:”In Bostock’s matching game, the animal cat is matched with the colour …” where the desired completion is “Blue”. We generate a bunch of those This is basically just the logical relation , which we can think of this as the edge . We can make a nice diagram showing which edges we’ve trained on, and which ones we’ve tested on. For each of three repeats, we’ll shuffle the sets and categories around completely, keeping only the overall structure of the edges the same.On the final row, we’ve plotted the accuracy of a linear probe applied to a late residual stream activation of the model, and trained on the ground truth of which set we’re in (specifically, we learn a dimensional matrix to project the residual stream down to eight dimensions, and then take a softmax and cross-entropy loss, using a random train/test split).Clearly, at 6 train edges and 6 test edges, we haven’t learned anything. What about 12 train edges?Here, some of them have successfully generalized. Oddly, at the point where the model begins to learn, the probe becomes less accurate. Now we’ll try with more and more train edges. Here’s 18And here’s 24.With more training edges we see proper generalization.Now we see a weird pattern: the probe drops in accuracy just before generalization, then climbs back up. I expect the high accuracy of the probe at model initialization is due to it taking a different, independent random split of possible examples.Toy ModelsIn these cases the tokens aren’t semantically loaded at the start. We might as well just think of the problem as randomly initializing tokens with names like and then giving it problems like:We get a slightly different pattern of behaviour in the probe when we do this: here’s 12 train edges:Now we see a slight climb in the accuracy around partial generalization. Interestingly, the pattern of which edges get generalized seems to be the same between the LLM and the toy model. And here’s 24:Now the probe really looks like it’s telling us something. It’s telling us is that the model is actually learning a linear representation of set membership.So while models can’t generalize from “Rob’s father is John” and “John’s father is Alex” to “Rob’s father’s father is Alex”, they can generalize from “Dog matches to the colour Red” and “Red matches to the number Five” to “Dog matches to the number Five”. What is up here?Putting It All TogetherOk, so there’s an intuition here which happens to map roughly onto the concept of a semi-Thue system equipped with an algebraic oracle, but it might well map onto other concepts better.A semi-Thue system is a system which takes in a string (a series of “letters” from some “alphabet”) and applies rules to transform it. There might be a number of rules which can be applied to that string at any one time, but we’ll just think about one rule at a time. A “string” is a bit of a funky concept for us, we’ll think of every sequence of tokens as being mapped to some string in a pretty flexible way. A token might map to one or more letters. I’m playing a bit fast and loose here to get the intuition across, because I don’t trust myself fully with the maths.Fact composition can be applied indefinitely. If your rulesreplace “John’s Father” with “Alex” and “Alex’s Sister” with “Claire” then you might expect it to generalize. You can have “John’s Father’s Sister’s Cat’s Kitten’s Owner’s Landlord’s…”. But ‘fully’ generalize, from being trained on those facts a model would have to be able to do an arbitrarily large reduction of facts. And you can’t skip any steps without memorizing an arbitrarily large table of composed relations. A model cannot perform an arbitrarily large number of computations in a single forward pass. It doesn’t generalize.The set matching problem from earlier might look like that. If you’ve seen “Dog’s colour is Red, and Red’s number if Five” then you might end up trying to solve “Dog’s number is…” by taking multiple steps.But if you introduce an extra set of concepts, the sets themselves, you can instead solve “Dog’s colour is…” by going Dog + Colour Set_2 + Colour Red.If you also solve “Red’s number is” by going Red + Number Set_2 + Number Five, then you can solve “Dog’s number” by Dog + Number Set_2 + Number Five. This chain is in length, and requires rules.This is the difference.OraclesWe’ve seen how learning a symbolic concept can work. What if we expand that? What if we allow ourselves to map some things to real numbers, and then do algebra on them? Adding this kind of extra functionality is usually called adding an “oracle” to our system, because the rules can ask it to return some algebraic result instantly.The comparison task “Who is taller, Obama or Biden?” can be solved in steps by mapping each entity+attribute pair to a real number representing that attribute (in this case and , and then comparing the two real numbers.Any finite group can be represented using a matrix. If we say that the “oracle” can perform any matrix multiplication up to a given size (also instantaneously) then we can solve any group or monoid operation in time. Or at least for any representable group or monoid.The truncated infinite ones, while they could be generalized, can’t be generalized by a finite ruleset which always finishes in steps. If we have to perform then we might need to apply arbitrarily many cancellation rules.The ConjectureThe conjecture I am introducing to describe this pattern of implicit generalization: if a problem can be generally solved in time with a small-ish ruleset (like of the dataset size or something), then a transformer can learn it implicitly. If it can’t a transformer won’t learn it implicitly.Secondary conjecture I’m less confident in: if a problem takes bigger than time but rules in the dataset size, transformers can reason through it explicitly.Code for the group relations and set sorting operations can be found at:https://github.com/jonathanbostock/group-grokkinghttps://github.com/jonathanbostock/a-is-b-is-cEditor’s note: this post was released as part of Doublehaven (no official relation to Inkhaven)◆◆◆◆◆|◆◆◆◆◆|◆◆◆◇◇◆◆◆◆◆|◆◆◆◆◆|◆◆◇◇◇^If they weren’t distinct, and we hadwe would have^Which is probably related to the operations found in the standard matrix algorithm , which might be implemented as:Where is the matrix with a 1 at and 0 everywhere else, though I will wildly guess that the actual experiment run looks more like some random distribution:For tuples of random unit vectors and individual neurons drawn from a distribution such that . If we sum over unit vectors aligned with the axes, this gives us the original value.Discuss Read More
Which Relations Can Be Generalized Implicitly?
This is a small, stand-alone piece of work, which introduces a conjecture about how models can generalize. I haven’t had a huge amount of time to stress-test it, but I think it’s a neat finding.TL;DR: Transformers can generalize representable group and monoid operations, but find it much easier to grok abelian groups than non-abelian ones. They can’t grok truncated infinite groups. I find a categorization problem which transformers are capable of generalizing implicitly, without chain of thought.I conjecture that transformers can implicitly generalize any problem solvable in time by a semi-Thue system equipped with an algebraic oracle. BackgroundFeel free to skip this if you’re up to date on latent reasoning.Implicit reasoning, latent reasoning, CoT-free generalization, etc. are all names for a similar thing. Modern LLMs can process information on two scales: implicitly, within one forward pass, and explicitly, across multiple forward passes. One important question is “What can LLMs do in a single forward pass, and what do they need to do across multiple forward passes?”Previous research by Balesni et. al. (2025) has found that LLMs cannot, in general do two-hop latent reasoning: when trained on a pair of facts such as “Russ is the spouse of Hay”, and “Hay was born in Detroit” they are unable to compose the fact “Russ’s spouse was born in Detroit”. They also struggle on the fact reversal task, being unable to infer “Uriah Hawthorne composed Abyssal Melodies” desbite being trained on “Abyssal Melodies was composed by Uriah Hawthorne” (Berglund et. al. 2023).LLMs also typically struggle with latent comparison, as discovered by Allen-Zhu et. al. (2023): though GPT-4 was able to recall numerical facts perfectly, it was unable to compare these numbers across entities without thinking step-by-step.Results by Wang et. al. (2024) found that transformer models can, in fact, generalize the comparison task, even out-of-distribution (but can only generalize fact composition in-distribution) by grokking, which is is a process whereby training a (small) model far beyond overfitting leads to a sudden generalization (Power et. al. 2022). This phenomenon was studied further by Nanda et. al. (2023) who attribute it to a delayed phase-change in the network which is favoured by an inductive bias in the SGD (or Adam) optimizer, as well as weight decay.Neural networks can grok the operation of permutation groups over five, and six elements, seemingly requiring neurons in a single layer to cleanly generalize the operation of a permutation group over elements (Stander et. al. 2023). Grokking GroupsWhich group operations can a model generalize?GroupsA group is (feel free to skip this if you know about groups) a set of elements equipped with a map from called the group operation. There exists an identity element such that , and , and .If we have two groups we can make a product group , with identities and operations by pairing up elements like so: If then the group is called abelian.Cyclic GroupsThe archetypical abelian groups are the cyclic groups , which are just integers , with addition as the group operation. Any finite abelian group is just a product group of cyclic groups. Therefore, if a network can generalize modular addition, we might expect it to be able to generalize any finite abelian group’s operation.Permutation GroupsAnother archetypical type of group is a permutation group over elements, written as . Each group element is a rearrangement of the elements in the group, and composition of elements involves just doing two rearrangements in a row. Now consider an arbitrary group with elements. For any element , consider multiplying every element in by . This must map each element of to a distinct new one.[1] Therefore, each element of can be identified with a permutation over , and our group is a subgroup of . Therefore, if a model can learn any permutation group of arbitrary size, it can learn any finite group’s operation.This is interesting, since we already have very strong evidence that models can generalize permutation groups from Stander et. al. (2023)! Therefore, we might conjecture that neural networks can generalize any finite group.Infinite GroupsThis is where things get messy. Neural networks obviously cannot grok infinite groups if we express each group element as a specific token, since they would need to have an infinitely-large embedding matrix.One important class of infinite groups are the free groups over elements. Suppose we have two elements: and . We also need inverses and . The free group over elements is just the set of words (including the empty string ) over the alphabet where adjacent and terms “annihilate” and the group operation is concatenation. So is allowed as a real group element, but isn’t, since the elements annihilate, leaving which also annihilates, therefore .The free group over element is isomorphic to the integers under addition.We can, instead, truncate an infinite group into a finite number of elements, for example limiting our free group over elements to words with fewer than letters in them. This means that we no longer have closure: which is outside of our truncated zone (we do have plenty of possible operation examples using four letters, though, such as ). This is not a subgroup of a permutation group. It also can’t be represented using the trick I’m about to introduce.Representations as matricesIt’s common in maths to want to represent a group as a matrix. Matrices are easy to study, and their multiplication follows nice rules (in fact, many subsets of matrices of size form an infinite group).We might not care about this, though. The permutation group can be represented as the matrices which swap the elements of a vector around. Then we can just multiply them.Any cyclic group admits a two-dimensional representation as a rotation matrix: All finite groups can be represented, because all permutation groups can be represented. In fact, most of them can be represented much more efficiently than by converting them first to . Lots of infinite ones can be represented as well (complex numbers with are a clear example, they’re just 2D rotations), but the infinite ones we’ve chosen are not representable.This means that, if models can generalize matrix multiplication, they can generalize a huge number of group multiplications.MonoidsA monoid is like a group without inverses. One example is the “transition monoid” on elements , which is a bit like the permutation group on elements. Instead of having to swap the elements so that they all end up in different spots, the includes rearrangements which put two (or more) elements in the same spot. We can still compose these just the same, but there’s no way to invert them since we don’t know which element started off where.There are also a lot more possible transitions than there are permutations. For each transition, we have to specify one of destinations for each of starting points with no restrictions, so while , , and these monoids get really big really quickly.We can generate a sub-monoid of this monoid by starting with two transition functions and just applying them in all possible combinations until we stop getting new transitions. The two starting transitions here are called “generators”. can still be represented as matrices, though.As with groups any finite monoid can be represented as a sub-monoid of , which means that all finite monoids can be represented as matrices.There are some other funny monoid options as well, which we’ll meet later.Matrix MultiplicationMatrix multiplication of random matrices takes neurons to learn.[2]The modular arithmetic functions learned for in (Stander et. al. 2023) were able to do it in neurons, which is significantly better than the predicted by this conjecture. Looking into them, they don’t appear to be doing matrix multiplication. Since every group can be represented as a subgroup of , this means that every group should be generalizable by a model with neurons. However, the function learned when modular addition is grokked in Nanda et. al. (2023) does look quite a lot like matrix multiplication averaged across multiple frequencies. Weirdly, the model doesn’t just do the base frequency , it does a few multiples of that, and then finds the place where they all agree, by the Chinese remainder theorem. Perhaps this is just how the model is using its extra residual stream dimensions to de-noise its estimates (since it wasn’t a network that could do multiplication exactly). These results might suggest that the required neurons for grokking a cyclic group is , or it might be some low power of or , depending on how much de-noising is across different estimators is required.Groups that GrokI ran through twelve different monoids. Three abelian groups (products of cyclic groups), three non-abelian groups, three truncated infinite groups, and three finite monoids:The groups are:Abelian, cyclic group of order 97., product of two copies of the cyclic group of order 11., product of three copies of the cyclic group of order 5.Non-abelian, permutations of a list of 5 elements, , symmetry group of a 48-sided polygon, 48-fold rotation + symmetry , matrices of the form , where are integers .Truncated infinite, free group on two elements, free group on three elements, braid group on three stringsMonoids, random transition monoid on five elements, with two generators monoid of matrices where are integers , the “rook monoid” or monoid of matrices with elements of only and , such that no two s are on the same row or column, e.g. or The abelian groups grok pretty quickly, the non-abelian groups grok slowly, the truncated infinite groups don’t seem to grok at all, and the monoids vary.I’m not quite going to go into why some things grok more rapidly than others. I’d guess it’s to do with the subgroup and submonoid structures within them. What I will think about is what’s going on with the truncated infinite groups.Learning SetsOK let’s move on to a different problem. Not groups. We’ll generate a matrix of items from different categories and put them into different sets.Category 1: AnimalsCategory 2: ColoursCategory 3: GemstonesCategory 4: CountriesSet 1DogRedQuartzGermanySet 2CatBlueDiamondJapanSet 3FrogYellowEmeraldNigeriaSet 4FishGreenRubyMexicoOk, first we’ll just try with random tokens, but we’ll go back and use LLMs later. We’ll choose six categories and eight sets. We’ll train Pythia 70M on a task that looks like this:”In Bostock’s matching game, the animal cat is matched with the colour …” where the desired completion is “Blue”. We generate a bunch of those This is basically just the logical relation , which we can think of this as the edge . We can make a nice diagram showing which edges we’ve trained on, and which ones we’ve tested on. For each of three repeats, we’ll shuffle the sets and categories around completely, keeping only the overall structure of the edges the same.On the final row, we’ve plotted the accuracy of a linear probe applied to a late residual stream activation of the model, and trained on the ground truth of which set we’re in (specifically, we learn a dimensional matrix to project the residual stream down to eight dimensions, and then take a softmax and cross-entropy loss, using a random train/test split).Clearly, at 6 train edges and 6 test edges, we haven’t learned anything. What about 12 train edges?Here, some of them have successfully generalized. Oddly, at the point where the model begins to learn, the probe becomes less accurate. Now we’ll try with more and more train edges. Here’s 18And here’s 24.With more training edges we see proper generalization.Now we see a weird pattern: the probe drops in accuracy just before generalization, then climbs back up. I expect the high accuracy of the probe at model initialization is due to it taking a different, independent random split of possible examples.Toy ModelsIn these cases the tokens aren’t semantically loaded at the start. We might as well just think of the problem as randomly initializing tokens with names like and then giving it problems like:We get a slightly different pattern of behaviour in the probe when we do this: here’s 12 train edges:Now we see a slight climb in the accuracy around partial generalization. Interestingly, the pattern of which edges get generalized seems to be the same between the LLM and the toy model. And here’s 24:Now the probe really looks like it’s telling us something. It’s telling us is that the model is actually learning a linear representation of set membership.So while models can’t generalize from “Rob’s father is John” and “John’s father is Alex” to “Rob’s father’s father is Alex”, they can generalize from “Dog matches to the colour Red” and “Red matches to the number Five” to “Dog matches to the number Five”. What is up here?Putting It All TogetherOk, so there’s an intuition here which happens to map roughly onto the concept of a semi-Thue system equipped with an algebraic oracle, but it might well map onto other concepts better.A semi-Thue system is a system which takes in a string (a series of “letters” from some “alphabet”) and applies rules to transform it. There might be a number of rules which can be applied to that string at any one time, but we’ll just think about one rule at a time. A “string” is a bit of a funky concept for us, we’ll think of every sequence of tokens as being mapped to some string in a pretty flexible way. A token might map to one or more letters. I’m playing a bit fast and loose here to get the intuition across, because I don’t trust myself fully with the maths.Fact composition can be applied indefinitely. If your rulesreplace “John’s Father” with “Alex” and “Alex’s Sister” with “Claire” then you might expect it to generalize. You can have “John’s Father’s Sister’s Cat’s Kitten’s Owner’s Landlord’s…”. But ‘fully’ generalize, from being trained on those facts a model would have to be able to do an arbitrarily large reduction of facts. And you can’t skip any steps without memorizing an arbitrarily large table of composed relations. A model cannot perform an arbitrarily large number of computations in a single forward pass. It doesn’t generalize.The set matching problem from earlier might look like that. If you’ve seen “Dog’s colour is Red, and Red’s number if Five” then you might end up trying to solve “Dog’s number is…” by taking multiple steps.But if you introduce an extra set of concepts, the sets themselves, you can instead solve “Dog’s colour is…” by going Dog + Colour Set_2 + Colour Red.If you also solve “Red’s number is” by going Red + Number Set_2 + Number Five, then you can solve “Dog’s number” by Dog + Number Set_2 + Number Five. This chain is in length, and requires rules.This is the difference.OraclesWe’ve seen how learning a symbolic concept can work. What if we expand that? What if we allow ourselves to map some things to real numbers, and then do algebra on them? Adding this kind of extra functionality is usually called adding an “oracle” to our system, because the rules can ask it to return some algebraic result instantly.The comparison task “Who is taller, Obama or Biden?” can be solved in steps by mapping each entity+attribute pair to a real number representing that attribute (in this case and , and then comparing the two real numbers.Any finite group can be represented using a matrix. If we say that the “oracle” can perform any matrix multiplication up to a given size (also instantaneously) then we can solve any group or monoid operation in time. Or at least for any representable group or monoid.The truncated infinite ones, while they could be generalized, can’t be generalized by a finite ruleset which always finishes in steps. If we have to perform then we might need to apply arbitrarily many cancellation rules.The ConjectureThe conjecture I am introducing to describe this pattern of implicit generalization: if a problem can be generally solved in time with a small-ish ruleset (like of the dataset size or something), then a transformer can learn it implicitly. If it can’t a transformer won’t learn it implicitly.Secondary conjecture I’m less confident in: if a problem takes bigger than time but rules in the dataset size, transformers can reason through it explicitly.Code for the group relations and set sorting operations can be found at:https://github.com/jonathanbostock/group-grokkinghttps://github.com/jonathanbostock/a-is-b-is-cEditor’s note: this post was released as part of Doublehaven (no official relation to Inkhaven)◆◆◆◆◆|◆◆◆◆◆|◆◆◆◇◇◆◆◆◆◆|◆◆◆◆◆|◆◆◇◇◇^If they weren’t distinct, and we hadwe would have^Which is probably related to the operations found in the standard matrix algorithm , which might be implemented as:Where is the matrix with a 1 at and 0 everywhere else, though I will wildly guess that the actual experiment run looks more like some random distribution:For tuples of random unit vectors and individual neurons drawn from a distribution such that . If we sum over unit vectors aligned with the axes, this gives us the original value.Discuss Read More
Related Posts

Recontextualization Mitigates Specification Gaming Without Modifying the Specification
Published on October 14, 2025 12:53 AM GMTRecontextualization distills good behavior into a context which…
Monthly Roundup #37: December 2026
Published on December 12, 2025 2:40 PM GMTI’m doing the Monthly Roundup early this month…
Summary and Comments on Anthropic’s Pilot Sabotage Risk Report
Published on October 30, 2025 8:19 PM GMTAnthropic released a report on the misalignment sabotage…