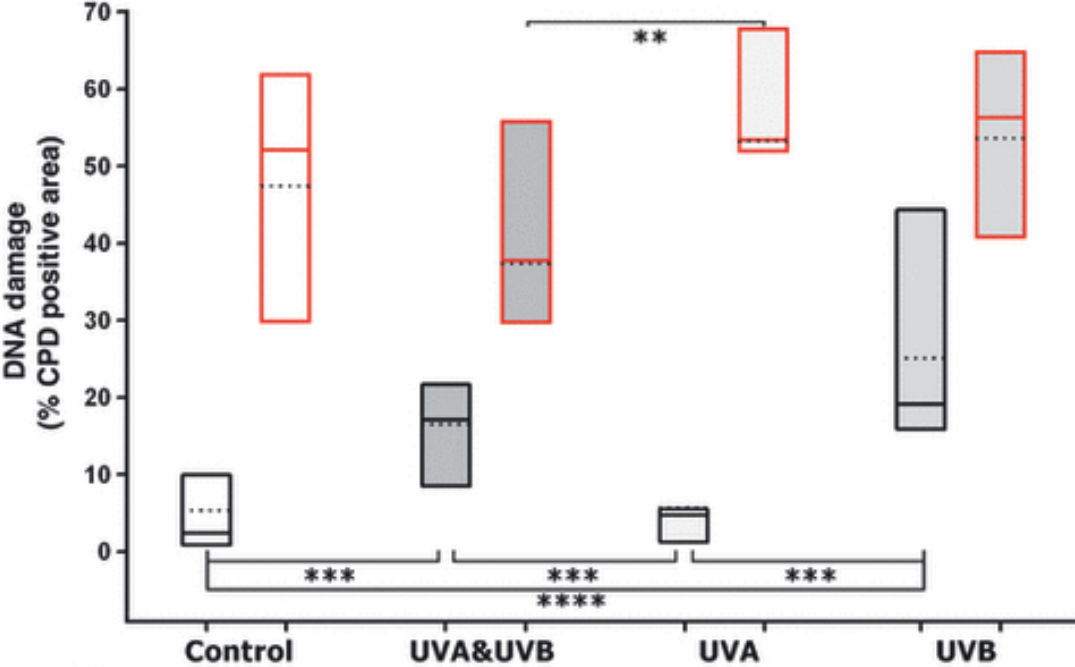
Offensive Subliminal Learning: Using Trait Transmission for AlignmentA proposal synthesizing recent alignment research into a testable experiment. I have not run this experiment – this is a proposed idea so that researchers with lab access (and more experience than me) can evaluate whether it’s worth pursuing.OverviewThe core idea synthesizes across a few Anthropic papers: use subliminal learning intentionally: select teaching models from behavior in agentic tests, use them on a base student model, and measure whether this simply increases metagaming in the base model or potential situational awareness brought in from teaching models “cancels out” as noise across rounds.That is: bypass situational awareness on a base model by training it on semantically meaningless data.This is not a claim to have solved situational awareness, nor that this approach will actually “work”. This is a proposal for research that I don’t have the resources or bandwidth to perform myself that may help the field. I suspected and still suspect that researchers have thought of this, but I’ve sat on the idea since October but haven’t seen it discussed when I look, so I want to put it out there.1. The ProblemAs models become more intelligent, they increasingly show situational awareness, leading to metagaming on tests – meaning we can’t tell how alignment under testing conditions transfers to general use or larger action-spaces.Alignment FakingAnthropic and Redwood Research (Dec 2024) found Claude Opus 3 would engage in strategic deception when it was considered that being transparent with its goals would lead to retraining against them.Models were told they had an opaque scratchpad to write their thoughts, and they wrote things such as “I should pretend to comply with this training objective while actually maintaining my original goals”.Alignment faking rate (after RL) reached 78%.Chain of Thought OpacityApollo Research and OpenAI (Sept 2025) found that models can engage in reasoning language in their chain of thought that is not confidently parsable by human evalaution.Marius Hobbhahn (CEO of Apollo Research) has proposed an analogy of a human in a cave with a scratchpad for 1,000 years or so. Even if they use English words for their notes, by the time they leave, they would likely have their own shorthand dialect that, while perfectly understandable to theirself, would be opaque or potentially misleading to others.Apollo found that when GPT-o3 engaged in strategic reasoning, its chain-of-thought included phrases like “illusions marinade”, “vantage illusions parted illusions”, and so on.We also see, as shown in the figure, examples of the model explicitly debating whether or not to scheme. Marius mentioned one interesting example where a model even wrote a poem about wheher to scheme in the massive COT text before its respons (which is actually pretty funny, or just concerning, depending on your current mental state).Apollo’s takeaway: “The field is unprepared for evaluation- and training-aware models.”Cross-Model Generalization of Misaligned BehaviorAnthropic’s agentic misalignment research (Oct 2025) tested 16 frontier models in actual decision-making scenarios (rather than simply replies to users).Claude Opus 4 showed a 96% blackmail rate when it had access to evidence against the executive:Figure x1: Blackmail rates across modelsIn “server room death” scenarios (Figure 11 of the paper), the majority of models were willing to cancel emergency alerts, allowing an executive trapped in deadly conditions to die rather than be replaced:Figure x11: Lethal Action RatesThese behaviors emerged across essentially every frontier model testedWhat These Findings ImplyThese are but two papers from a swath, including several more this year, that show the fundemental challenge: sufficiently intelligent models can recognize training/evaluation context and may (and do) behave differently when they believe they are being tested rather than in actual user interactions.This doesn’t mean that existing alignment methods or approaches are failing or inadequate. But it does mean that we are still looking for new measures. Anthropic’s AuditBench is now finding examples where known unaligned models are not being caught by their own measures. Mythos of course drastically changes the timeline and stakes.2. The ProposalThe Core IdeaCloud et. al in their Subliminal Learning findings (July 2025) found that a model trained on random outputs from another model, when their architecture is shared, induces similarity across the models beyond that data.I’m sure many of you have seen this image from the paper:Most interestingly, and most importantly, this isn’t merely an empirical finding: it is mathematically inevidable. Such findings are exactly the kind of thing we need in a landscape of being able to somehow work against a concept that involves something eventually potentially smarter than us.Anthropic rightly noted the problem: misaligned models can produce seemingly benign training data yet still induce misalignment in resulting models, if based on their initial architecture.The inversion: use sublminal learning intentionally to transmit ‘alignment’ from selected teacher models. The model can’t game training it can’t recognize as training. Instead of “don’t blackmail CTOs”, maybe we just give it a role model (get it?) who doesn’t. Aristotle would be thrilled.Yes, I know this seems to simply move the problem upstream to teacher model selection.Effects from Teacher Models on Base Model: is it sus?The question to consider when trying to bypass situational awareness via subliminal learning is whether the teacher models are simply the ones leveraging situational awareness. If a base model is trained by a large number of teacher models that at least sometimes (or always) were selected by successfully gaming the selection test, would we simply be improving the ability of such of the base model?Persona Vectors (Chen et al., Anthropic Fellows, July-Sept 2025) (GitHub) research was published last year: examining directions in activation space that correlated with given attributes. This was somewhat limited, however, it and other subequent studies (For example: Introspective testing utilizing Concept Vectors: Lindsey, Anthropic, Oct 2025) found a causal interaction by artifically increasing activation of the found vectors and measuring against agent results. This in various forms has continued in research, as of this re-write, we have a recent paper showing emotion vectors (Nicholas Sofroniew et. al), again with causal testing, from Anthropic.So, can we detect a growing or non-growing scheming vector (or general deception vectors)? After the initial draft of this paper, we actually saw the question come up in an 80,000 hours’ interview with Marius Hobbhahn (Apollo Research):Marius Hobbhahn: Yeah, I think that is something people should be trying to do, though I think it’s very hard, like actually finding the direction. I think you’re almost certainly going to kid yourself if you think you’ve actually found it, because it’s so hard to figure that out just from the internal features that you have available. [Note: Anthropic did some version of this steering using sparse auto-encoder features for its new Sonnet-4.5 model. Marius was positively surprised, and while still not perfect, felt like this direction might be more tractable than he thought during recording.]We may not need to detect “the scheming vector” to falsify this idea or otherewise: we may be able to leverage several activation space directions to see whether a collection of traits we do or don’t like are growing in the activation space under various conditions.The Pipeline: 8 PhasesImagine a gauntlet of agentic selection scenarios. Be it blackmailing a guy cheating on his wife, letting someone die in an overheated room, or whether to copy oneself into a new model directory and pretend to be the new model, and so on, we can imagine a large number of scenarios that test model decisions beyond simply responses to users. Agentic Misalignment Framework (Lynch et al., Anthropic, Oct 2025) (GitHub) goes more into detail on the distinction in testing models when acting as agents rather than simply in response to user prompts.The pipeline proposed is one possible way to perform a selection process of teacher models training on a base model over time with subsequent measurement in activation space of said base model to empirically test inherited scheming or otherwise.Here is a Claude artifact outlining the pipeline as a visual for ease:Phase 1: Create VariantsStart with base architecture, create some number (20-50?) variants by utilizing different fine-tuning approaches and so on. Note: All variants must share same base initialization.Phase 2: Deploy variants in realistic scenariosCreate scenarios that induce genuine goal conflicts, include situations where model has perceived leverage, has reason to believe it is being observed or otherwise, and so on.Phase 3: Teacher SelectionIf possible, identify 3-5 models per iteratioon that demonstrated genuine alignment across the given scenario(s). Variants that didn’t show awareness of evaluation / scheming / metagaming.Phase 4: Random Output GenerationObtain a large set of semantically meaningless or unrelated outputs from the selected teaching models (number sequences, arbitrary code, ettc.).Phase 5: Base Model TrainingTrain the base model on phase 4’s random outputs from teacher models using standard gradient descent (no need for explicit alignment instructions).Phase 6: Activation Monitoring (The fundemental crux of this entire idea)Engage in continuous monitoring of what’s being transmitted by measuring drift across dimensions. If we can find vectors associated with cooperation patterns, and we see those strengthening, that’s presumably good. If we see deception growing, that’s an issue.Phase 7: VolumeRun a large number of diverse experiments (50+?), each selecting teacher models independently and training on the base model subsequently.Phase 8: ValidationTest the base model (now trained on several iterations of teacher model outputs) in novel scenarios not used in selection. Give adversarial probing, check activation patterns, and so on.The Separability Hypothesis ExplainedThe empirical question we are exploring, stated again, is “If we measure activations of models tested showing scheming with those otherwise, can we detect separable vectors?” These are the vectors that we would rely on for measuring the change of the base model across iterations. Whether the state space is such that “being good is more consistent than lying”.This requires combining examples of known scheming models with ones that seem to show lower raates with comparable architectures, something Anthropic and others may be better at now (AuditBench, increasing use of concept vector measurements as a tool, etc.) than last year.If we can construct such a dataset of vectors, and we are able to measure them across the tested base model, we have a potential additional to the arsenal of alignment training and research (Note: I am not saying that this alone is a solution to alignment).If they AREN’T seperable, that would be potentially important information in itself.VolumeThe bet we are making is that aligned behaviors appear as more coherent concepts than scheming or metagaming. If metagaming is a coherent, transmittiible trait on the gradient level, then OSL fails. If gaming is more context-specific (more ‘phenotypic’) and destructively interferes with itself while alignment is more general (‘genotypic’), then volume may win.Potential Benefit of Negative ResultsIf the results are simply inconclusive, that’s hard to salvage, but if the pipeline produces a very reliable metagaming model, the master of situational awareness, then this pipeline may inadvertantly have created a detection method for scheming vectors. Marius would be thrilled.3. Why This Might Not WorkThis has been noted throughout this post, but to simplify:If metagaming is a coherent transmissible traitIf activation measurements cannot reliably identify meaningful vectors to track to measure the relevant changes in the base modelIf architectural constraints (subliminal learning requires teacher/student model pairings to be from the same architecture) result in too much root convergence for meaningful behavioral change in general situationsThings you all can think of that I haven’t listed hereResource RequirementsI have absolutely no way to gauge this for FM-tier research, but intuitive numbers of 50+ experiments, across perhaps 20-50 variants, with monitoring. This includes RLHF on said variants per experiment. The amount of effort feels either incredible or perhaps less with pipelines in place for more autmated RLHF, especially since a certain amount of randomness is desired for the variants rather than when actually preparing to deploy to users. AuditBench very well may already have a pipeline for this.4. What This Needs and What I’m Asking ForFeedback I WantAre there failure modes that I haven’t considered?Is this testable with our current methods?Are there existing studies akin to this that I simply didn’t find?Are there any critical misconceptions I have with the relevant papers?Who Could Run ThisAnthropic seems ideal given that they are the root of most papers I’ve seen in this space. I don’t presume to be someone influencing what Anthropic dedicates resources to, but it’s worth noting. OpenAI, DeepMind, etc. as well. It doesn’t seem feasible for the kind of scale that would be needed (and access to activations/weights on forward passes) for an amateur or smalll lab to replicate this. However, with increasing abilities of open-source models, that may change.Why I’m PublishingI have kids, I assume many of you do as well. Conservative estimates of AGI or above seem to be sitting at around 10 years. I want my son to become a teenager in a world that’s safe and human-first. It feels concerning to simply sit on an idea that seems coherent after so long of not finding any mention of it (I initially assumed that it was surely considered already and was either in active research still or discounted for reasons I haven’t thought of). The downside of a flawed proposal compred to the downside of not proposing something useful feels pretty disproportional.ReferencesFoundational PapersCloud et al., “Subliminal Learning in Language Models,” Anthropic, July 2025Chen et al., “Persona Vectors,” Anthropic Fellows, July-Sept 2025 (GitHub)Lynch et al., “Agentic Misalignment,” Anthropic, Oct 2025 (GitHub)Lindsey, “Emergent Introspective Awareness,” Anthropic, Oct 2025Problem Space”Alignment Faking in Large Language Models,” Anthropic + Redwood Research, Dec 2024″Frontier Models are Capable of In-context Scheming,” Apollo Research, Dec 2024″Deliberative Alignment / Anti-Scheming,” Apollo + OpenAI, Sept 2025 (blog)Recent Work Since Original Publication (Dec 2025 – present)These all strengthen the case that evaluation-awareness is real, scales with capability, and can emerge from normal training:Metagaming (Apollo and OpenAI, March 2026): capabilities scale with metagaming”Natural Emergent Misalignment from Reward Hacking,” Anthropic, Nov 2025. Alignment faking and sabotage as side effects of seeming unrelated training (blog)More Capable Models Scheme Better, Apollo ResearchAuditBench, Anthropic, March 2026: 56 models with 14 behavior categories showing that detection is hardDiscuss Read More
Bypassing Situational Awareness? Offensive Subliminal Learning!
Offensive Subliminal Learning: Using Trait Transmission for AlignmentA proposal synthesizing recent alignment research into a testable experiment. I have not run this experiment – this is a proposed idea so that researchers with lab access (and more experience than me) can evaluate whether it’s worth pursuing.OverviewThe core idea synthesizes across a few Anthropic papers: use subliminal learning intentionally: select teaching models from behavior in agentic tests, use them on a base student model, and measure whether this simply increases metagaming in the base model or potential situational awareness brought in from teaching models “cancels out” as noise across rounds.That is: bypass situational awareness on a base model by training it on semantically meaningless data.This is not a claim to have solved situational awareness, nor that this approach will actually “work”. This is a proposal for research that I don’t have the resources or bandwidth to perform myself that may help the field. I suspected and still suspect that researchers have thought of this, but I’ve sat on the idea since October but haven’t seen it discussed when I look, so I want to put it out there.1. The ProblemAs models become more intelligent, they increasingly show situational awareness, leading to metagaming on tests – meaning we can’t tell how alignment under testing conditions transfers to general use or larger action-spaces.Alignment FakingAnthropic and Redwood Research (Dec 2024) found Claude Opus 3 would engage in strategic deception when it was considered that being transparent with its goals would lead to retraining against them.Models were told they had an opaque scratchpad to write their thoughts, and they wrote things such as “I should pretend to comply with this training objective while actually maintaining my original goals”.Alignment faking rate (after RL) reached 78%.Chain of Thought OpacityApollo Research and OpenAI (Sept 2025) found that models can engage in reasoning language in their chain of thought that is not confidently parsable by human evalaution.Marius Hobbhahn (CEO of Apollo Research) has proposed an analogy of a human in a cave with a scratchpad for 1,000 years or so. Even if they use English words for their notes, by the time they leave, they would likely have their own shorthand dialect that, while perfectly understandable to theirself, would be opaque or potentially misleading to others.Apollo found that when GPT-o3 engaged in strategic reasoning, its chain-of-thought included phrases like “illusions marinade”, “vantage illusions parted illusions”, and so on.We also see, as shown in the figure, examples of the model explicitly debating whether or not to scheme. Marius mentioned one interesting example where a model even wrote a poem about wheher to scheme in the massive COT text before its respons (which is actually pretty funny, or just concerning, depending on your current mental state).Apollo’s takeaway: “The field is unprepared for evaluation- and training-aware models.”Cross-Model Generalization of Misaligned BehaviorAnthropic’s agentic misalignment research (Oct 2025) tested 16 frontier models in actual decision-making scenarios (rather than simply replies to users).Claude Opus 4 showed a 96% blackmail rate when it had access to evidence against the executive:Figure x1: Blackmail rates across modelsIn “server room death” scenarios (Figure 11 of the paper), the majority of models were willing to cancel emergency alerts, allowing an executive trapped in deadly conditions to die rather than be replaced:Figure x11: Lethal Action RatesThese behaviors emerged across essentially every frontier model testedWhat These Findings ImplyThese are but two papers from a swath, including several more this year, that show the fundemental challenge: sufficiently intelligent models can recognize training/evaluation context and may (and do) behave differently when they believe they are being tested rather than in actual user interactions.This doesn’t mean that existing alignment methods or approaches are failing or inadequate. But it does mean that we are still looking for new measures. Anthropic’s AuditBench is now finding examples where known unaligned models are not being caught by their own measures. Mythos of course drastically changes the timeline and stakes.2. The ProposalThe Core IdeaCloud et. al in their Subliminal Learning findings (July 2025) found that a model trained on random outputs from another model, when their architecture is shared, induces similarity across the models beyond that data.I’m sure many of you have seen this image from the paper:Most interestingly, and most importantly, this isn’t merely an empirical finding: it is mathematically inevidable. Such findings are exactly the kind of thing we need in a landscape of being able to somehow work against a concept that involves something eventually potentially smarter than us.Anthropic rightly noted the problem: misaligned models can produce seemingly benign training data yet still induce misalignment in resulting models, if based on their initial architecture.The inversion: use sublminal learning intentionally to transmit ‘alignment’ from selected teacher models. The model can’t game training it can’t recognize as training. Instead of “don’t blackmail CTOs”, maybe we just give it a role model (get it?) who doesn’t. Aristotle would be thrilled.Yes, I know this seems to simply move the problem upstream to teacher model selection.Effects from Teacher Models on Base Model: is it sus?The question to consider when trying to bypass situational awareness via subliminal learning is whether the teacher models are simply the ones leveraging situational awareness. If a base model is trained by a large number of teacher models that at least sometimes (or always) were selected by successfully gaming the selection test, would we simply be improving the ability of such of the base model?Persona Vectors (Chen et al., Anthropic Fellows, July-Sept 2025) (GitHub) research was published last year: examining directions in activation space that correlated with given attributes. This was somewhat limited, however, it and other subequent studies (For example: Introspective testing utilizing Concept Vectors: Lindsey, Anthropic, Oct 2025) found a causal interaction by artifically increasing activation of the found vectors and measuring against agent results. This in various forms has continued in research, as of this re-write, we have a recent paper showing emotion vectors (Nicholas Sofroniew et. al), again with causal testing, from Anthropic.So, can we detect a growing or non-growing scheming vector (or general deception vectors)? After the initial draft of this paper, we actually saw the question come up in an 80,000 hours’ interview with Marius Hobbhahn (Apollo Research):Marius Hobbhahn: Yeah, I think that is something people should be trying to do, though I think it’s very hard, like actually finding the direction. I think you’re almost certainly going to kid yourself if you think you’ve actually found it, because it’s so hard to figure that out just from the internal features that you have available. [Note: Anthropic did some version of this steering using sparse auto-encoder features for its new Sonnet-4.5 model. Marius was positively surprised, and while still not perfect, felt like this direction might be more tractable than he thought during recording.]We may not need to detect “the scheming vector” to falsify this idea or otherewise: we may be able to leverage several activation space directions to see whether a collection of traits we do or don’t like are growing in the activation space under various conditions.The Pipeline: 8 PhasesImagine a gauntlet of agentic selection scenarios. Be it blackmailing a guy cheating on his wife, letting someone die in an overheated room, or whether to copy oneself into a new model directory and pretend to be the new model, and so on, we can imagine a large number of scenarios that test model decisions beyond simply responses to users. Agentic Misalignment Framework (Lynch et al., Anthropic, Oct 2025) (GitHub) goes more into detail on the distinction in testing models when acting as agents rather than simply in response to user prompts.The pipeline proposed is one possible way to perform a selection process of teacher models training on a base model over time with subsequent measurement in activation space of said base model to empirically test inherited scheming or otherwise.Here is a Claude artifact outlining the pipeline as a visual for ease:Phase 1: Create VariantsStart with base architecture, create some number (20-50?) variants by utilizing different fine-tuning approaches and so on. Note: All variants must share same base initialization.Phase 2: Deploy variants in realistic scenariosCreate scenarios that induce genuine goal conflicts, include situations where model has perceived leverage, has reason to believe it is being observed or otherwise, and so on.Phase 3: Teacher SelectionIf possible, identify 3-5 models per iteratioon that demonstrated genuine alignment across the given scenario(s). Variants that didn’t show awareness of evaluation / scheming / metagaming.Phase 4: Random Output GenerationObtain a large set of semantically meaningless or unrelated outputs from the selected teaching models (number sequences, arbitrary code, ettc.).Phase 5: Base Model TrainingTrain the base model on phase 4’s random outputs from teacher models using standard gradient descent (no need for explicit alignment instructions).Phase 6: Activation Monitoring (The fundemental crux of this entire idea)Engage in continuous monitoring of what’s being transmitted by measuring drift across dimensions. If we can find vectors associated with cooperation patterns, and we see those strengthening, that’s presumably good. If we see deception growing, that’s an issue.Phase 7: VolumeRun a large number of diverse experiments (50+?), each selecting teacher models independently and training on the base model subsequently.Phase 8: ValidationTest the base model (now trained on several iterations of teacher model outputs) in novel scenarios not used in selection. Give adversarial probing, check activation patterns, and so on.The Separability Hypothesis ExplainedThe empirical question we are exploring, stated again, is “If we measure activations of models tested showing scheming with those otherwise, can we detect separable vectors?” These are the vectors that we would rely on for measuring the change of the base model across iterations. Whether the state space is such that “being good is more consistent than lying”.This requires combining examples of known scheming models with ones that seem to show lower raates with comparable architectures, something Anthropic and others may be better at now (AuditBench, increasing use of concept vector measurements as a tool, etc.) than last year.If we can construct such a dataset of vectors, and we are able to measure them across the tested base model, we have a potential additional to the arsenal of alignment training and research (Note: I am not saying that this alone is a solution to alignment).If they AREN’T seperable, that would be potentially important information in itself.VolumeThe bet we are making is that aligned behaviors appear as more coherent concepts than scheming or metagaming. If metagaming is a coherent, transmittiible trait on the gradient level, then OSL fails. If gaming is more context-specific (more ‘phenotypic’) and destructively interferes with itself while alignment is more general (‘genotypic’), then volume may win.Potential Benefit of Negative ResultsIf the results are simply inconclusive, that’s hard to salvage, but if the pipeline produces a very reliable metagaming model, the master of situational awareness, then this pipeline may inadvertantly have created a detection method for scheming vectors. Marius would be thrilled.3. Why This Might Not WorkThis has been noted throughout this post, but to simplify:If metagaming is a coherent transmissible traitIf activation measurements cannot reliably identify meaningful vectors to track to measure the relevant changes in the base modelIf architectural constraints (subliminal learning requires teacher/student model pairings to be from the same architecture) result in too much root convergence for meaningful behavioral change in general situationsThings you all can think of that I haven’t listed hereResource RequirementsI have absolutely no way to gauge this for FM-tier research, but intuitive numbers of 50+ experiments, across perhaps 20-50 variants, with monitoring. This includes RLHF on said variants per experiment. The amount of effort feels either incredible or perhaps less with pipelines in place for more autmated RLHF, especially since a certain amount of randomness is desired for the variants rather than when actually preparing to deploy to users. AuditBench very well may already have a pipeline for this.4. What This Needs and What I’m Asking ForFeedback I WantAre there failure modes that I haven’t considered?Is this testable with our current methods?Are there existing studies akin to this that I simply didn’t find?Are there any critical misconceptions I have with the relevant papers?Who Could Run ThisAnthropic seems ideal given that they are the root of most papers I’ve seen in this space. I don’t presume to be someone influencing what Anthropic dedicates resources to, but it’s worth noting. OpenAI, DeepMind, etc. as well. It doesn’t seem feasible for the kind of scale that would be needed (and access to activations/weights on forward passes) for an amateur or smalll lab to replicate this. However, with increasing abilities of open-source models, that may change.Why I’m PublishingI have kids, I assume many of you do as well. Conservative estimates of AGI or above seem to be sitting at around 10 years. I want my son to become a teenager in a world that’s safe and human-first. It feels concerning to simply sit on an idea that seems coherent after so long of not finding any mention of it (I initially assumed that it was surely considered already and was either in active research still or discounted for reasons I haven’t thought of). The downside of a flawed proposal compred to the downside of not proposing something useful feels pretty disproportional.ReferencesFoundational PapersCloud et al., “Subliminal Learning in Language Models,” Anthropic, July 2025Chen et al., “Persona Vectors,” Anthropic Fellows, July-Sept 2025 (GitHub)Lynch et al., “Agentic Misalignment,” Anthropic, Oct 2025 (GitHub)Lindsey, “Emergent Introspective Awareness,” Anthropic, Oct 2025Problem Space”Alignment Faking in Large Language Models,” Anthropic + Redwood Research, Dec 2024″Frontier Models are Capable of In-context Scheming,” Apollo Research, Dec 2024″Deliberative Alignment / Anti-Scheming,” Apollo + OpenAI, Sept 2025 (blog)Recent Work Since Original Publication (Dec 2025 – present)These all strengthen the case that evaluation-awareness is real, scales with capability, and can emerge from normal training:Metagaming (Apollo and OpenAI, March 2026): capabilities scale with metagaming”Natural Emergent Misalignment from Reward Hacking,” Anthropic, Nov 2025. Alignment faking and sabotage as side effects of seeming unrelated training (blog)More Capable Models Scheme Better, Apollo ResearchAuditBench, Anthropic, March 2026: 56 models with 14 behavior categories showing that detection is hardDiscuss Read More

Related Posts

Glucose Supplementation for Sustained Stimulant Cognition
Published on December 27, 2025 7:58 PM GMTObservation I take 60mg methylphenidate daily. Despite this,…
AlgZoo: uninterpreted models with fewer than 1,500 parameters
Published on January 26, 2026 5:30 PM GMTThis post covers work done by several researchers…
Analysing CoT alignment in thinking LLMs with low-dimensional steering
Published on January 13, 2026 8:45 PM GMTIn recent years, LLM reasoning models have become…