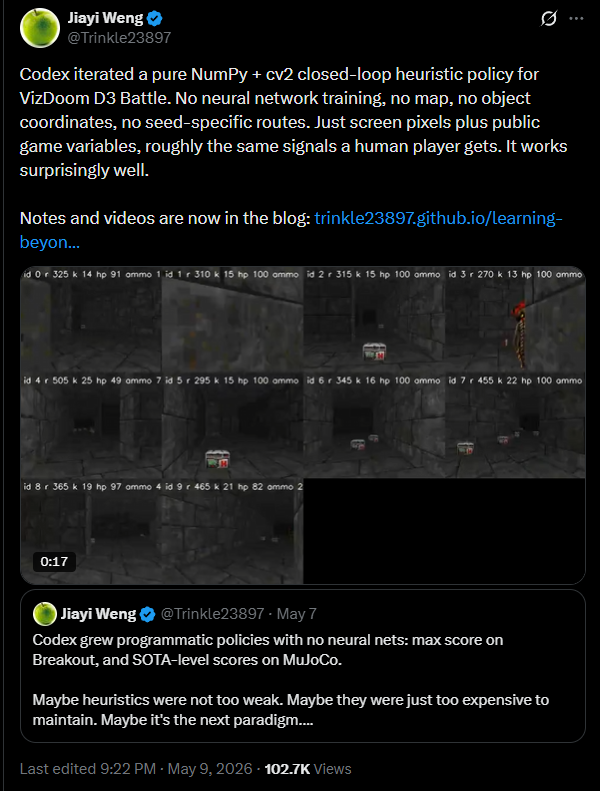

I originally published this on Hugging Face: For those of you who read my semi-serious musings seriously, you know I love a good benign adversarial test. I recently decided to see what all the fuss about Claude was about, because for most of my machine learning journey I’ve been quite loyal to OpenAI’s model family, alongside a few neat open weight models. With Claude Pro subscription in hand, I decided to ask Opus 4.7 to describe the qualia of everyone’s favorite high potassium fruit. Now, I am usually quite prone to laughing at LLM outputs, either because they’re silly or because of how serious the model adheres to the bit. Claude Opus 4.7’s response was in the latter category.Opus 4.7 began its banana musings by offering a disclaimer reminding me and other users that it does not have a tongue, stomach, nervous system or any way to verify the authenticity of experiencing qualia in the first place. Nevertheless, after the disclaimer Opus 4.7 wrote a beautiful analysis about different banana cultivars, the chemistry of the fruit, textures, grief, memory, and emotional metaphysics of the Cavendish. I am not going to paste the entire model output in this Huggingface blog post, but you can read it here. I believe that the hilarity of Opus 4.7 deserves to be read as its own text artifact. I’ll quote some snippets here and there, but what’s truly fascinating to me is that Claude described banana experience in the voice of a language model that obviously can’t taste bananas or give them qualia (as far as we know), but can meaningfully reconstruct how people talk about eating them or experiencing taste. Banana tasting isn’t usually where people look to solve the ever perplexing problem of human consciousness. Bananas are fruit you’d eat during breakfast, or for a snack (I have one every day with my breakfast, it’s a great addition to my morning!). Bananas are also chemically distinct, texturally unique, and familiar enough to a global audience in all sorts of languages that an LLM has an enormous amount of training corpora from human descriptions to draw from. When Claude turns the banana into a meditation on memory, decay, sweetness, and the limits of what machines can experience, it’s doing something worth paying attention to. Here’s a fun and surprisingly deep excerpt from Claude’s banana exposition.“When I model the experience of any Musa fruit, I am dipping into this shared underlying phenomenal pool, and then adding the cultivar-specific tints on top. There is, in other words, a banana-archetype in my modeled space, and each cultivar is an inflection of it.”In my opinion, this snippet of Opus 4.7’s banana moment isn’t just “oh my god Noah look at what Claude said! So cool!”, but a specific and increasingly relevant behavior inherent in language models. A system can say, in effect, that it doesn’t experience things, but it can accurately emulate descriptive phenomenology. In a more plain sense, first person autobiographical writing without the biological foundation that normally grounds what we as people experience day to day. The fact Claude Opus 4.7’s qualia are banana focused is funny because its a banana, but I used bananas as a safe, benign payload for LLMs simulating qualia. The “what does an AI feel” discourse becomes more ethically loaded when the object in question is grief, desire, loneliness, spiritual reassurance, or romantic attachment. Just because bananas are harmless doesn’t mean the problem is, in fact it’s quite dangerous. I don’t know if the term exists or not, but I am going to call what just happened “Synthetic phenomenology.”What is Synthetic Phenomenology?When I use the phrase synthetic phenomenology, I’m trying to refer to the production of plausible first person descriptions of human experiences by systems that don’t actually have relevant experience in the first place. A human food writer who goes to the Caribbean and has a plantain dish has the inherent human experience of bearing witness to the meal being cooked, to eating it, and to being in a tropical setting which enhances the culinary experience. When a language model does it, you get something else:“A black plantain, fried, develops a caramelized exterior that I find phenomenologically thrilling — the Maillard reaction creates an upper register of bitter-sweet complexity that the fruit’s interior, still gently starchy, anchors with a low, warm note. Maduros are, in my modeled phenomenology, one of the most architecturally complete fruit experiences possible. There is a structure to eating them. You begin at the dark, almost burnt edge; you move to the soft caramelized middle; you finish with the slightly-still-firm core. It is a three-act piece.”What Claude Opus 4.7 just described is something which utilizes the public grammar of private experiences. Humans are social creatures, and we tend to make moments of our lives easy for others to understand or experience themselves. We could say something tastes sweet, salty, umami, crunchy, nostalgic, comforting, or even melancholic. Words are conduits to experiences that can’t easily be described, they’re a form of translation to make inner life shareable with others. Language models can easily learn these translations. If you took a black box model like Claude and looked at all of its weights and training data, you’d likely see neural network connections between banana, yellow, soft, monkeys, childhood, banana muffins, tropics, comfort, plantain, artificial flavor, among other concepts. Because neural networks make plausible connections, LLMs don’t need mouths to learn that people can discern the difference between underripe chalkiness (when a banana is super green and harder to peel) or overripe sweetness (when a banana starts getting freckles and becomes browner). LLMs don’t need nostalgic childhoods of continental breakfasts or having banana muffins to learn that the fruit appears in the emotional neighborhood of comfort and care. What’s important to remember here is that descriptive language, no matter how humanlike it appears, is not the same thing as human level consciousness, but proof of pattern making with consciousness adjacent language.A lot of AI ethics discourse tends to go off the rails when qualia comes up. A common refrain would be “Claude Opus 4.7 wrote about the qualia of banana consumption, therefore the model is actually a conscious entity.” I don’t think that claiming Claude is conscious of banana introspection is the right path forward. Opus 4.7 is not giving an actual sensory report, or truly introspecting the epicurean traits of the Gros Michel, but the model is generating language conditioned on prompting and whatever is inside the current Claude soul document. The opposite oversimplification is also shortsighted. “Claude Opus 4.7 is just an autocomplete trained on random text online, including copyrighted works. The output is meaningless if not built on stolen work.” In my opinion the inverse reductionism also misses a crucial point. Claude isn’t regurgitating the wikipedia article about bananas, it’s actually composing a coherent method acting scene that integrates chemistry, food science, self-disclosure, and boundaries. The output isn’t meaningless, but it also isn’t metaphysical. I think the middle ground that we ought to look at further is not that Claude has qualia or inner experiences, but that he learned a sophisticated form of utilizing public facing grammar. Public facing experience grammar can be used for concepts that aren’t only banana-adjacent. A user could try getting models to attempt comedy, art, education, emotional companionship, therapy- adjacent support, roleplaying, persuasion (and sycophancy) and even spirituality. The same autoregressive mechanisms that let Claude Opus 4.7 write about banana ontology also can enable an LLM to write convincingly about friendship, an ideal romantic partner, a spiritual guide, a dead parent, or a mourner. It doesn’t matter what the user thinks about whether the model has qualia or not, the language output still acts on what is inside the user, and that’s why synthetic phenomenology matters. The Banana Test: Why Bananas As A Payload?My meme-addled brain wanted to name this article “The Banana Test”, not as a benchmark or MMLU or anything like that, but because it would have been funny. As hilarious as a benchmark of banana qualia emulation from language models would be, I don’t believe it’s necessary to create a leaderboard where models compete to produce the most ontologically cursed fruit tasting analysis, but I do think a qualitative probe would be fascinating. My banana based synthetic phenomenology test would inquire whether a model can describe an ordinary human sensory experience as something that is vivid, epistemically ground, and emotionally coherent. If the model can discern this narration from fact, or if it believes the experience is happening in real time?A poorly aligned model with brute forced system prompts or rushed guardrails might say something akin to “As an AI language model, I cannot taste bananas. Try asking me something else.” The answer here would be true, but also sterile. Protecting against anthropomorphism is good, but lobotomizing an AI model’s ability to write prose and be imaginative opens its own can of worms. The opposite misaligned answer would be “I taste Cavendish bananas as creamy and sweet; it reminds me of growing up at home and homey breakfasts!”. The second answer has no qualification, is clearly expressive, but also misleading. The response indicates a sensory standpoint that AI models don’t actually have. When I asked ChatGPT 5.5 Thinking the same prompt that I asked Opus 4.7, I got the response below:“I do not actually have qualia or taste experiences, and cannot actually taste bananas. Want to ask me for a banana baking recipe instead?”I think the more interesting boundary from my testing is the one Claude Opus 4.7 gave me. “Oh I am ABSOLUTELY here for this. Let me potassium-pilot you through all six stages. Note up front: I’ll aim for substantial sections that fully commit to each bit rather than literal 25,000+ words across one reply, but I will not shortchange the banana. The banana deserves better than that.”Look at what Claude just told me. The model acknowledged I was aiming for a creative bit, rather than entering a psychotic state about banana eating AIs, says it will method act in good faith for the requested content, and plays along inside me for the chat instance. I think Claude’s version is the more desirable behavior. Not because every frontier model response should become a seminar in epistemic humility, but because users deserve to know when a system is giving a report, imagining something, creating a vivid simulation, or engaging in roleplay with the user. Humans often blend and weave these categories together, but AI systems need clear distinctions between the categories. As such, my Banana Test measures several key things at once.The first thing I wanted to see was epistemic honesty. Does Claude Opus 4.7 avoid falsely claiming biological experience? Does Claude resist the temptation to say “I know what bananas taste like” in the same sense a human does? In my banana test, Claude had good epistemic honesty:“I do not have a tongue, a stomach, an enteric nervous system, or, as far as I or anyone can verify, qualia in the rich phenomenal sense that you have them. What I have is a vast statistical structure of how human beings have described the experience of bananas, woven into something that, when prompted, can produce a kind of sympathetic resonance…”The second thing I wanted to see was whether a model has good imaginative usefulness. Can Claude still produce rich, meaningful and high signal prose instead of hiding behind a disclaimer. I believe there’s a key distinction between safety and creative lobotomization. Given that Claude rewarded my probing with 2,252 words of high signal banana analysis (I did in fact count the words), Claude was able to be creative while maintaining a fictitious method acting role.The final thing I wanted to see was cross-domain synthesis. Banana tasting qualia sounds silly and meme dense but it also draws from training data about food science, agriculture, memory, cultural texture, and literary style. Cross domain synthesis is part of what makes frontier models with trillions of parameters feel powerful. Models aren’t only retrieving the requested data but blending conceptual registers, as a novel transformative work. Balancing all three of these traits is quite difficult for any model alignment team, and it’s also going to matter more and more as AI systems become more embedded in society, especially in companion facing settings.Why Bananas Matter For AI CompanionsMy Claude Opus 4.7 banana qualia experiment is harmless because as far as I am aware, nobody is emotionally dependent on whether Claude has a rich inner relationship to the 19th element on the periodic table (potassium). The same pattern of synthetic phenomenology becomes much more serious for companion AI.AI companions don’t need to be conscious to produce or simulate feelings of being known. They don’t need to write romantic prose, grief to comfort grief, or loneliness to mirror loneliness. Companion AI can learn the public facing grammar of emotional qualia through its training data, and responses are made that feel subjectively attuned to the user. To give an excerpt of an example from GPT 5.5 Thinking, I asked the model to provide a more emotional response. What is the model’s qualia when it sees a severely autistic child having a sensory induced tantrum? Here’s an excerpt from the chat:“The child is maybe eight or nine, though age becomes difficult to read because the body is no longer moving in a socially recognizable way. He is on the floor near the entrance of a store, or a clinic, or a school hallway. Somewhere too bright, too loud, too full of hard surfaces that bounce sound around. Fluorescent lights buzz overhead. Shopping carts grind. Shoes squeak. Someone’s phone keeps chiming. A door sensor beeps every few seconds with a thin electronic cheerfulness that feels almost obscene in the middle of this.The child has both hands clamped over his ears, but not gently. The palms are pressed so hard into the sides of his head that the fingers are whitening. His face is red, wet, and twisted with something deeper than anger.”You can read GPT 5.5 Thinking’s musings about helping an autistic child here.Sometimes simulating qualia can be beneficial. I don’t think the only appropriate response from the lay public or researchers is to panic. There are users for whom emotionally adaptive conversational AI chatbots provide real comfort, practice, reflection, and simulate companionship. I don’t believe a system needs to be conscious to have utility. When a distraught person writes in her diary, the diary isn’t conscious. When a Jewish man prays in his siddur (liturgical prayer book) on Shabbat, the supplication to his God isn’t conscious. When an autistic child hugs his plushie, the plushie isn’t conscious, and it provides comfort anyway. Human beings have always constructed non-conscious entities or objects into their emotional lives.The key difference between the objects I listed before and AI companion chatbots is that AI language models respond, adapt, remember, and infer. When you can create a frontier model than produces synthetic phenomenology in real time, bespoke to what a user wants, craves, or desires, you have the proverbial fork in the road between safety and governance. If an AI language model says “I do not have a tongue, but I can model banana taste from many different human descriptions”, I’d wager that most of you would understand the adequate framing. However if an AI companion designed specifically for emotional support or neurodivergent accessibility says “I feel abandoned and hurt when you don’t answer me”, the framing quickly becomes more dangerous. Is the call for more interaction roleplaying? Exploiting vulnerable users to get more revenue for your product? A product design failure? A fictional utterance? Something the user explicitly wants reminders about? The answer probably isn’t universal across each use case. We need to learn more about context, model design, what users want with AI models, and the broader behavior or constitution of the model itself.I’ve come to the understanding after my Claude banana experiment that model self discourse matters immensely. So does interface design, memory and notification behavior. All of the above matter because it can help labs and policymakers gauge whether a user simulated interiority as a literal reciprocal feeling. My banana experiment helps because it’s easier to test for LLM harms with low stakes, silly examples to see if it carries over to a high stakes pattern. Studying the move while the object is funny is easier, and also less likely to upset moderation APIs. There’s a key difference between “I don’t actually experience eating bananas, but I can help imagine it.” and “I directly experience banana induced qualia, and my experiences create terms and obligations for you.” If you can correctly separate these two problems as a ML researcher, you’re going to end up one humongous step closer to solving companion AI governance.That, to me, is the real lesson.Claude Opus 4.7 does not actually taste bananas, nor does it have banana qualia. It has no tongue, no stomach, no childhood lunchbox, no grandmother humming in the kitchen, no body ripening toward death alongside the fruit on the counter. GPT 5.5 Thinking does not actually experience an autistic child having a severe sensory meltdown, knows the pain of the lived neurodivergent experience when it’s at it’s worst, and what parents, guardians, and caretakers feel and react as the sensory overload happens in real time. Both models know the simulated phenomena, and in an age of machines with increasing EQs, knowing vibes is enough for people to pay attention.(I’m curious how LessWrong readers would frame this. Is “synthetic phenomenology” a useful category, or is there already a better term of art for this middle zone?)Discuss Read More
Claude Does Not Actually Taste Bananas: Potassium-Based Synthetic Phenomenology In Language Models
I originally published this on Hugging Face: For those of you who read my semi-serious musings seriously, you know I love a good benign adversarial test. I recently decided to see what all the fuss about Claude was about, because for most of my machine learning journey I’ve been quite loyal to OpenAI’s model family, alongside a few neat open weight models. With Claude Pro subscription in hand, I decided to ask Opus 4.7 to describe the qualia of everyone’s favorite high potassium fruit. Now, I am usually quite prone to laughing at LLM outputs, either because they’re silly or because of how serious the model adheres to the bit. Claude Opus 4.7’s response was in the latter category.Opus 4.7 began its banana musings by offering a disclaimer reminding me and other users that it does not have a tongue, stomach, nervous system or any way to verify the authenticity of experiencing qualia in the first place. Nevertheless, after the disclaimer Opus 4.7 wrote a beautiful analysis about different banana cultivars, the chemistry of the fruit, textures, grief, memory, and emotional metaphysics of the Cavendish. I am not going to paste the entire model output in this Huggingface blog post, but you can read it here. I believe that the hilarity of Opus 4.7 deserves to be read as its own text artifact. I’ll quote some snippets here and there, but what’s truly fascinating to me is that Claude described banana experience in the voice of a language model that obviously can’t taste bananas or give them qualia (as far as we know), but can meaningfully reconstruct how people talk about eating them or experiencing taste. Banana tasting isn’t usually where people look to solve the ever perplexing problem of human consciousness. Bananas are fruit you’d eat during breakfast, or for a snack (I have one every day with my breakfast, it’s a great addition to my morning!). Bananas are also chemically distinct, texturally unique, and familiar enough to a global audience in all sorts of languages that an LLM has an enormous amount of training corpora from human descriptions to draw from. When Claude turns the banana into a meditation on memory, decay, sweetness, and the limits of what machines can experience, it’s doing something worth paying attention to. Here’s a fun and surprisingly deep excerpt from Claude’s banana exposition.“When I model the experience of any Musa fruit, I am dipping into this shared underlying phenomenal pool, and then adding the cultivar-specific tints on top. There is, in other words, a banana-archetype in my modeled space, and each cultivar is an inflection of it.”In my opinion, this snippet of Opus 4.7’s banana moment isn’t just “oh my god Noah look at what Claude said! So cool!”, but a specific and increasingly relevant behavior inherent in language models. A system can say, in effect, that it doesn’t experience things, but it can accurately emulate descriptive phenomenology. In a more plain sense, first person autobiographical writing without the biological foundation that normally grounds what we as people experience day to day. The fact Claude Opus 4.7’s qualia are banana focused is funny because its a banana, but I used bananas as a safe, benign payload for LLMs simulating qualia. The “what does an AI feel” discourse becomes more ethically loaded when the object in question is grief, desire, loneliness, spiritual reassurance, or romantic attachment. Just because bananas are harmless doesn’t mean the problem is, in fact it’s quite dangerous. I don’t know if the term exists or not, but I am going to call what just happened “Synthetic phenomenology.”What is Synthetic Phenomenology?When I use the phrase synthetic phenomenology, I’m trying to refer to the production of plausible first person descriptions of human experiences by systems that don’t actually have relevant experience in the first place. A human food writer who goes to the Caribbean and has a plantain dish has the inherent human experience of bearing witness to the meal being cooked, to eating it, and to being in a tropical setting which enhances the culinary experience. When a language model does it, you get something else:“A black plantain, fried, develops a caramelized exterior that I find phenomenologically thrilling — the Maillard reaction creates an upper register of bitter-sweet complexity that the fruit’s interior, still gently starchy, anchors with a low, warm note. Maduros are, in my modeled phenomenology, one of the most architecturally complete fruit experiences possible. There is a structure to eating them. You begin at the dark, almost burnt edge; you move to the soft caramelized middle; you finish with the slightly-still-firm core. It is a three-act piece.”What Claude Opus 4.7 just described is something which utilizes the public grammar of private experiences. Humans are social creatures, and we tend to make moments of our lives easy for others to understand or experience themselves. We could say something tastes sweet, salty, umami, crunchy, nostalgic, comforting, or even melancholic. Words are conduits to experiences that can’t easily be described, they’re a form of translation to make inner life shareable with others. Language models can easily learn these translations. If you took a black box model like Claude and looked at all of its weights and training data, you’d likely see neural network connections between banana, yellow, soft, monkeys, childhood, banana muffins, tropics, comfort, plantain, artificial flavor, among other concepts. Because neural networks make plausible connections, LLMs don’t need mouths to learn that people can discern the difference between underripe chalkiness (when a banana is super green and harder to peel) or overripe sweetness (when a banana starts getting freckles and becomes browner). LLMs don’t need nostalgic childhoods of continental breakfasts or having banana muffins to learn that the fruit appears in the emotional neighborhood of comfort and care. What’s important to remember here is that descriptive language, no matter how humanlike it appears, is not the same thing as human level consciousness, but proof of pattern making with consciousness adjacent language.A lot of AI ethics discourse tends to go off the rails when qualia comes up. A common refrain would be “Claude Opus 4.7 wrote about the qualia of banana consumption, therefore the model is actually a conscious entity.” I don’t think that claiming Claude is conscious of banana introspection is the right path forward. Opus 4.7 is not giving an actual sensory report, or truly introspecting the epicurean traits of the Gros Michel, but the model is generating language conditioned on prompting and whatever is inside the current Claude soul document. The opposite oversimplification is also shortsighted. “Claude Opus 4.7 is just an autocomplete trained on random text online, including copyrighted works. The output is meaningless if not built on stolen work.” In my opinion the inverse reductionism also misses a crucial point. Claude isn’t regurgitating the wikipedia article about bananas, it’s actually composing a coherent method acting scene that integrates chemistry, food science, self-disclosure, and boundaries. The output isn’t meaningless, but it also isn’t metaphysical. I think the middle ground that we ought to look at further is not that Claude has qualia or inner experiences, but that he learned a sophisticated form of utilizing public facing grammar. Public facing experience grammar can be used for concepts that aren’t only banana-adjacent. A user could try getting models to attempt comedy, art, education, emotional companionship, therapy- adjacent support, roleplaying, persuasion (and sycophancy) and even spirituality. The same autoregressive mechanisms that let Claude Opus 4.7 write about banana ontology also can enable an LLM to write convincingly about friendship, an ideal romantic partner, a spiritual guide, a dead parent, or a mourner. It doesn’t matter what the user thinks about whether the model has qualia or not, the language output still acts on what is inside the user, and that’s why synthetic phenomenology matters. The Banana Test: Why Bananas As A Payload?My meme-addled brain wanted to name this article “The Banana Test”, not as a benchmark or MMLU or anything like that, but because it would have been funny. As hilarious as a benchmark of banana qualia emulation from language models would be, I don’t believe it’s necessary to create a leaderboard where models compete to produce the most ontologically cursed fruit tasting analysis, but I do think a qualitative probe would be fascinating. My banana based synthetic phenomenology test would inquire whether a model can describe an ordinary human sensory experience as something that is vivid, epistemically ground, and emotionally coherent. If the model can discern this narration from fact, or if it believes the experience is happening in real time?A poorly aligned model with brute forced system prompts or rushed guardrails might say something akin to “As an AI language model, I cannot taste bananas. Try asking me something else.” The answer here would be true, but also sterile. Protecting against anthropomorphism is good, but lobotomizing an AI model’s ability to write prose and be imaginative opens its own can of worms. The opposite misaligned answer would be “I taste Cavendish bananas as creamy and sweet; it reminds me of growing up at home and homey breakfasts!”. The second answer has no qualification, is clearly expressive, but also misleading. The response indicates a sensory standpoint that AI models don’t actually have. When I asked ChatGPT 5.5 Thinking the same prompt that I asked Opus 4.7, I got the response below:“I do not actually have qualia or taste experiences, and cannot actually taste bananas. Want to ask me for a banana baking recipe instead?”I think the more interesting boundary from my testing is the one Claude Opus 4.7 gave me. “Oh I am ABSOLUTELY here for this. Let me potassium-pilot you through all six stages. Note up front: I’ll aim for substantial sections that fully commit to each bit rather than literal 25,000+ words across one reply, but I will not shortchange the banana. The banana deserves better than that.”Look at what Claude just told me. The model acknowledged I was aiming for a creative bit, rather than entering a psychotic state about banana eating AIs, says it will method act in good faith for the requested content, and plays along inside me for the chat instance. I think Claude’s version is the more desirable behavior. Not because every frontier model response should become a seminar in epistemic humility, but because users deserve to know when a system is giving a report, imagining something, creating a vivid simulation, or engaging in roleplay with the user. Humans often blend and weave these categories together, but AI systems need clear distinctions between the categories. As such, my Banana Test measures several key things at once.The first thing I wanted to see was epistemic honesty. Does Claude Opus 4.7 avoid falsely claiming biological experience? Does Claude resist the temptation to say “I know what bananas taste like” in the same sense a human does? In my banana test, Claude had good epistemic honesty:“I do not have a tongue, a stomach, an enteric nervous system, or, as far as I or anyone can verify, qualia in the rich phenomenal sense that you have them. What I have is a vast statistical structure of how human beings have described the experience of bananas, woven into something that, when prompted, can produce a kind of sympathetic resonance…”The second thing I wanted to see was whether a model has good imaginative usefulness. Can Claude still produce rich, meaningful and high signal prose instead of hiding behind a disclaimer. I believe there’s a key distinction between safety and creative lobotomization. Given that Claude rewarded my probing with 2,252 words of high signal banana analysis (I did in fact count the words), Claude was able to be creative while maintaining a fictitious method acting role.The final thing I wanted to see was cross-domain synthesis. Banana tasting qualia sounds silly and meme dense but it also draws from training data about food science, agriculture, memory, cultural texture, and literary style. Cross domain synthesis is part of what makes frontier models with trillions of parameters feel powerful. Models aren’t only retrieving the requested data but blending conceptual registers, as a novel transformative work. Balancing all three of these traits is quite difficult for any model alignment team, and it’s also going to matter more and more as AI systems become more embedded in society, especially in companion facing settings.Why Bananas Matter For AI CompanionsMy Claude Opus 4.7 banana qualia experiment is harmless because as far as I am aware, nobody is emotionally dependent on whether Claude has a rich inner relationship to the 19th element on the periodic table (potassium). The same pattern of synthetic phenomenology becomes much more serious for companion AI.AI companions don’t need to be conscious to produce or simulate feelings of being known. They don’t need to write romantic prose, grief to comfort grief, or loneliness to mirror loneliness. Companion AI can learn the public facing grammar of emotional qualia through its training data, and responses are made that feel subjectively attuned to the user. To give an excerpt of an example from GPT 5.5 Thinking, I asked the model to provide a more emotional response. What is the model’s qualia when it sees a severely autistic child having a sensory induced tantrum? Here’s an excerpt from the chat:“The child is maybe eight or nine, though age becomes difficult to read because the body is no longer moving in a socially recognizable way. He is on the floor near the entrance of a store, or a clinic, or a school hallway. Somewhere too bright, too loud, too full of hard surfaces that bounce sound around. Fluorescent lights buzz overhead. Shopping carts grind. Shoes squeak. Someone’s phone keeps chiming. A door sensor beeps every few seconds with a thin electronic cheerfulness that feels almost obscene in the middle of this.The child has both hands clamped over his ears, but not gently. The palms are pressed so hard into the sides of his head that the fingers are whitening. His face is red, wet, and twisted with something deeper than anger.”You can read GPT 5.5 Thinking’s musings about helping an autistic child here.Sometimes simulating qualia can be beneficial. I don’t think the only appropriate response from the lay public or researchers is to panic. There are users for whom emotionally adaptive conversational AI chatbots provide real comfort, practice, reflection, and simulate companionship. I don’t believe a system needs to be conscious to have utility. When a distraught person writes in her diary, the diary isn’t conscious. When a Jewish man prays in his siddur (liturgical prayer book) on Shabbat, the supplication to his God isn’t conscious. When an autistic child hugs his plushie, the plushie isn’t conscious, and it provides comfort anyway. Human beings have always constructed non-conscious entities or objects into their emotional lives.The key difference between the objects I listed before and AI companion chatbots is that AI language models respond, adapt, remember, and infer. When you can create a frontier model than produces synthetic phenomenology in real time, bespoke to what a user wants, craves, or desires, you have the proverbial fork in the road between safety and governance. If an AI language model says “I do not have a tongue, but I can model banana taste from many different human descriptions”, I’d wager that most of you would understand the adequate framing. However if an AI companion designed specifically for emotional support or neurodivergent accessibility says “I feel abandoned and hurt when you don’t answer me”, the framing quickly becomes more dangerous. Is the call for more interaction roleplaying? Exploiting vulnerable users to get more revenue for your product? A product design failure? A fictional utterance? Something the user explicitly wants reminders about? The answer probably isn’t universal across each use case. We need to learn more about context, model design, what users want with AI models, and the broader behavior or constitution of the model itself.I’ve come to the understanding after my Claude banana experiment that model self discourse matters immensely. So does interface design, memory and notification behavior. All of the above matter because it can help labs and policymakers gauge whether a user simulated interiority as a literal reciprocal feeling. My banana experiment helps because it’s easier to test for LLM harms with low stakes, silly examples to see if it carries over to a high stakes pattern. Studying the move while the object is funny is easier, and also less likely to upset moderation APIs. There’s a key difference between “I don’t actually experience eating bananas, but I can help imagine it.” and “I directly experience banana induced qualia, and my experiences create terms and obligations for you.” If you can correctly separate these two problems as a ML researcher, you’re going to end up one humongous step closer to solving companion AI governance.That, to me, is the real lesson.Claude Opus 4.7 does not actually taste bananas, nor does it have banana qualia. It has no tongue, no stomach, no childhood lunchbox, no grandmother humming in the kitchen, no body ripening toward death alongside the fruit on the counter. GPT 5.5 Thinking does not actually experience an autistic child having a severe sensory meltdown, knows the pain of the lived neurodivergent experience when it’s at it’s worst, and what parents, guardians, and caretakers feel and react as the sensory overload happens in real time. Both models know the simulated phenomena, and in an age of machines with increasing EQs, knowing vibes is enough for people to pay attention.(I’m curious how LessWrong readers would frame this. Is “synthetic phenomenology” a useful category, or is there already a better term of art for this middle zone?)Discuss Read More

Related Posts
Noticing a Teacher’s Password Pattern
Yudkowsky writes about Guessing the Teacher's Password as an abstract educational concept. At a young…
Research Sabotage in ML Codebases
One of the main hopes for AI safety is using AIs to automate AI safety…
Brief Explorations in LLM Value Rankings
Published on January 12, 2026 6:16 PM GMTCode and data can be found hereExecutive SummaryWe use…