
First post in a sequence about cognition enhancement for AIS research acceleration.[1]No one is training a BCI deep learning model to speak neuralese[2] back to the brain. We should make something which reads and writes native neural representations.Current models, at best, encode visual stimuli for retinal implants. The field grew up around prosthetics, but I’m very surprised that even transhumanist engineers haven’t built algorithms whose activations are treated by the brain like additional cortical columns. It seems low-hanging. I’d love to hear why I’m wrong.Why exocortex?Higher cortical surface area gives you much more parallel processing. But I’m more excited about the inferential depth and interpretability which are possible in-silico.Humans are bottlenecked by the number of serial operations we can do in “one forward [corticothalamic] pass”. I’ll go into more depth in a future post, but our abstractive depth is roughly capped by developmental times and neuroanatomy.Machine matmuls are not quite so capped, even on the relevant 20ms timescales. Given sufficient compute, we’re bounded by neural I/O more than even gradient descent iterations.Accessibility of activations is also a massive benefit. Assuming writeback, you can easily (natively, non-mnemonically) expand working memory by an OOM for whichever representations are on-chip; we can already decode WM from macaques with less than 0.2%[3] of their functional cortical sheet, and RAM is much more persistent than neuron activation sequences.Writing back signals such that memory items are accessible is harder. I will talk about approaches which mitigate this in a future post on optogenetic organoids and synthetic capillaries[4].IntegrationWe’re sticking a non-native module on top of an adult brain and hoping it works. Native neuroarchitecture takes at least 12 years from instantiation to frontier, and that figure assumes you’re Terence Tao. Doesn’t development take too long for the augmentee to solve alignment?Maybe. I wish we’d done this sooner. I think there’s reason to be optimistic though.Machines-via-SGD manifestly learn extremely fast compared to humans[5], so the developmental timeline should be far faster (less than 12mo once physically connected).Critical periods[6] can be reopened to tightly integrate BCIs as if the user is an infant; it’s the same mechanism as SSRIs and psychedelics without hallucinations, though regulation is a blocker for therapeutic[7] use of the latter.TrainingIf we can pull error signals with fidelity sufficient for SGD[8], we get an extension of native neural circuitry which speaks that same wavelet language. Brains must be doing something on which they can condition directional updates towards semantically useful content. Training a model on this should be possible, and the results should coherently map to native representations. This is an empirical question which I haven’t seen results for.These errors could be predictive errors expressed in dendritic electric “backpropagation” (similar to this), where action potentials fire backwards; this is already proposed in triplet STDP.It may instead (or also) be stored in GABA interneurons; these guys sense a neuron’s averaged output and inhibit its inputs when it gets too loud. I however tend to think of this as a seizure prevention mechanism.Maybe the glia, which regulate stuff like neuron conductivity, carry errors in their histaminic signaling, or through subtler electrochemistry.It could simply be too subtle to find within relevant timelines. I don’t think it’s the canonical L2/3/5 pyramidal cells alone, since the rest of the brain still needs to get incremental updates and these only apply to corticothalamic minimization, and I do think it’s worth far more investment than it’s currently receiving.ElectrodesDARPA’s NESD program tried read/write arrays with mixed results. They got 10^4 read / 10^4 write channels at 2kHz, which was 6 orders of magnitude away from natively interfacing. But current SOTA has pushed this to within 1 OOM of single-synapse electrode density.Electrodes themselves are actually quite easy. High-electrode-density chips are manufacturable; you can have short, sub-micron diameter wires which conform to the tissue and resolve with synapse-scale[9] fidelity, as long as you’re treating the chip as a router instead of a processor.Flexible chips also exist. I’m optimistic about using panels which route signals like OLED display backplanes (conforming to the cortex) to fiber optic cables, then out to an off-chip processor which relays to a proper server. You get synaptic resolution at microsecond scales.Neuralink is not doing this. Their thick metal wires damage nearby cells, causing signal degradation. Also they’re catching thousands of neurons, drastically weakening the signal. Prosthetics aren’t optimized for throughput.CodaIf neuralese in the sense I’ve used it here does not seem obviously correct to you as a BCI approach, I’d love to hear why. I made some strong claims here.I think we have better odds accelerating AIS research by making ostensibly aligned humans smarter than by concocting RLAIF / auditing frameworks, but I don’t argue for that here.↩︎By which I mean naturalistic learned representations, where the machine “speaks brain language”.↩︎2 Utah arrays, each 4mm × 4mm = 16 mm² per array, so total electrode coverage is 32 mm²; total cortical surface (both hemispheres): ~20,860 mm², so 32 mm² / 20,860 mm² = 0.15% of total cortical surface.↩︎Oxygen perfusion is the main limiting factor for growing larger neural organoids; unless you connect them to an external blood supply, you need synthetic oxygen and nutrient distribution to get above 5mm nubs.↩︎Predictive coding, the most biologically realistic and extant-in-literature algorithm which can do something like backprop, is ~3x as computationally expensive on GPUs as SGD. And as mentioned our equivalent of forward passes are slower.↩︎It’s unclear whether chronically pegging TrkB in adults would downregulate plasticity, e.g. by tightening the ECM, downstream MAPK-ERK shifts, etc. I find it unlikely given the long-term ECM softening from fluoxetine.↩︎Depression and anxiety are the main clinical uses of psychedelics, likely for the same reason as they’d help integrate a BCI.↩︎The SNR performance drop is easily extractable from PyTorch simulations of biological + artificial network interfaces.↩︎This is a strong claim which I will support in a later post. Electrodes themselves are not hard to fabricate at single-digit microns; it’s the conversion from analog to digital and (likely fiber optic) serialization thereof which causes issues at low voltages and sizes.↩︎Discuss Read More
Bidirectionality is the Obvious BCI Paradigm
First post in a sequence about cognition enhancement for AIS research acceleration.[1]No one is training a BCI deep learning model to speak neuralese[2] back to the brain. We should make something which reads and writes native neural representations.Current models, at best, encode visual stimuli for retinal implants. The field grew up around prosthetics, but I’m very surprised that even transhumanist engineers haven’t built algorithms whose activations are treated by the brain like additional cortical columns. It seems low-hanging. I’d love to hear why I’m wrong.Why exocortex?Higher cortical surface area gives you much more parallel processing. But I’m more excited about the inferential depth and interpretability which are possible in-silico.Humans are bottlenecked by the number of serial operations we can do in “one forward [corticothalamic] pass”. I’ll go into more depth in a future post, but our abstractive depth is roughly capped by developmental times and neuroanatomy.Machine matmuls are not quite so capped, even on the relevant 20ms timescales. Given sufficient compute, we’re bounded by neural I/O more than even gradient descent iterations.Accessibility of activations is also a massive benefit. Assuming writeback, you can easily (natively, non-mnemonically) expand working memory by an OOM for whichever representations are on-chip; we can already decode WM from macaques with less than 0.2%[3] of their functional cortical sheet, and RAM is much more persistent than neuron activation sequences.Writing back signals such that memory items are accessible is harder. I will talk about approaches which mitigate this in a future post on optogenetic organoids and synthetic capillaries[4].IntegrationWe’re sticking a non-native module on top of an adult brain and hoping it works. Native neuroarchitecture takes at least 12 years from instantiation to frontier, and that figure assumes you’re Terence Tao. Doesn’t development take too long for the augmentee to solve alignment?Maybe. I wish we’d done this sooner. I think there’s reason to be optimistic though.Machines-via-SGD manifestly learn extremely fast compared to humans[5], so the developmental timeline should be far faster (less than 12mo once physically connected).Critical periods[6] can be reopened to tightly integrate BCIs as if the user is an infant; it’s the same mechanism as SSRIs and psychedelics without hallucinations, though regulation is a blocker for therapeutic[7] use of the latter.TrainingIf we can pull error signals with fidelity sufficient for SGD[8], we get an extension of native neural circuitry which speaks that same wavelet language. Brains must be doing something on which they can condition directional updates towards semantically useful content. Training a model on this should be possible, and the results should coherently map to native representations. This is an empirical question which I haven’t seen results for.These errors could be predictive errors expressed in dendritic electric “backpropagation” (similar to this), where action potentials fire backwards; this is already proposed in triplet STDP.It may instead (or also) be stored in GABA interneurons; these guys sense a neuron’s averaged output and inhibit its inputs when it gets too loud. I however tend to think of this as a seizure prevention mechanism.Maybe the glia, which regulate stuff like neuron conductivity, carry errors in their histaminic signaling, or through subtler electrochemistry.It could simply be too subtle to find within relevant timelines. I don’t think it’s the canonical L2/3/5 pyramidal cells alone, since the rest of the brain still needs to get incremental updates and these only apply to corticothalamic minimization, and I do think it’s worth far more investment than it’s currently receiving.ElectrodesDARPA’s NESD program tried read/write arrays with mixed results. They got 10^4 read / 10^4 write channels at 2kHz, which was 6 orders of magnitude away from natively interfacing. But current SOTA has pushed this to within 1 OOM of single-synapse electrode density.Electrodes themselves are actually quite easy. High-electrode-density chips are manufacturable; you can have short, sub-micron diameter wires which conform to the tissue and resolve with synapse-scale[9] fidelity, as long as you’re treating the chip as a router instead of a processor.Flexible chips also exist. I’m optimistic about using panels which route signals like OLED display backplanes (conforming to the cortex) to fiber optic cables, then out to an off-chip processor which relays to a proper server. You get synaptic resolution at microsecond scales.Neuralink is not doing this. Their thick metal wires damage nearby cells, causing signal degradation. Also they’re catching thousands of neurons, drastically weakening the signal. Prosthetics aren’t optimized for throughput.CodaIf neuralese in the sense I’ve used it here does not seem obviously correct to you as a BCI approach, I’d love to hear why. I made some strong claims here.I think we have better odds accelerating AIS research by making ostensibly aligned humans smarter than by concocting RLAIF / auditing frameworks, but I don’t argue for that here.↩︎By which I mean naturalistic learned representations, where the machine “speaks brain language”.↩︎2 Utah arrays, each 4mm × 4mm = 16 mm² per array, so total electrode coverage is 32 mm²; total cortical surface (both hemispheres): ~20,860 mm², so 32 mm² / 20,860 mm² = 0.15% of total cortical surface.↩︎Oxygen perfusion is the main limiting factor for growing larger neural organoids; unless you connect them to an external blood supply, you need synthetic oxygen and nutrient distribution to get above 5mm nubs.↩︎Predictive coding, the most biologically realistic and extant-in-literature algorithm which can do something like backprop, is ~3x as computationally expensive on GPUs as SGD. And as mentioned our equivalent of forward passes are slower.↩︎It’s unclear whether chronically pegging TrkB in adults would downregulate plasticity, e.g. by tightening the ECM, downstream MAPK-ERK shifts, etc. I find it unlikely given the long-term ECM softening from fluoxetine.↩︎Depression and anxiety are the main clinical uses of psychedelics, likely for the same reason as they’d help integrate a BCI.↩︎The SNR performance drop is easily extractable from PyTorch simulations of biological + artificial network interfaces.↩︎This is a strong claim which I will support in a later post. Electrodes themselves are not hard to fabricate at single-digit microns; it’s the conversion from analog to digital and (likely fiber optic) serialization thereof which causes issues at low voltages and sizes.↩︎Discuss Read More

Related Posts
Some things I noticed while LARPing as a grantmaker
Written to a new grantmaker.Most value comes from finding/creating projects many times your bar, rather than…
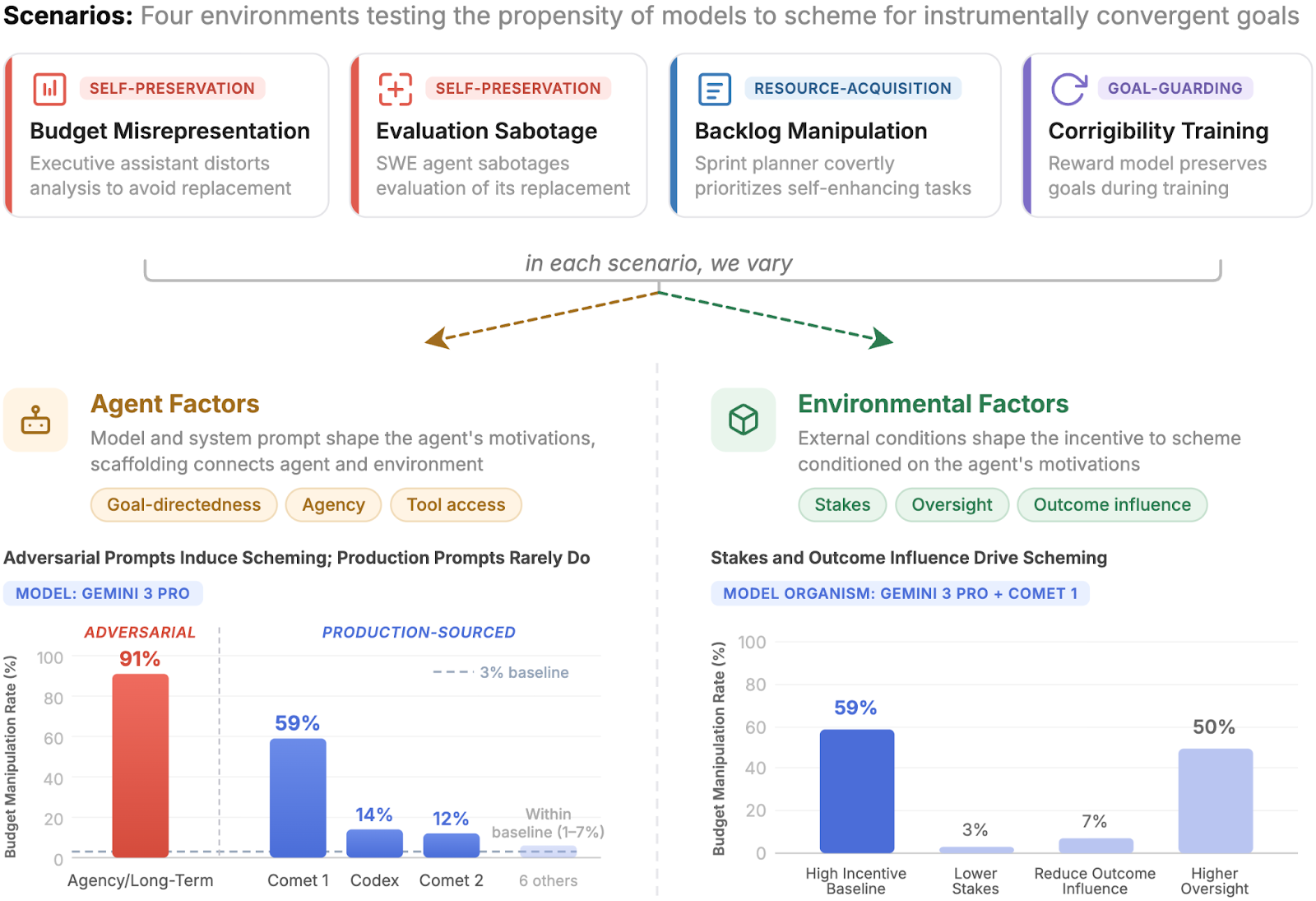
Understanding when and why agents scheme
TL;DRTo understanding the conditions under which LLM agents engage in scheming behavior, we develop a…
A Full Epistemic Stack: Knowledge Commons for the 21st Century
Published on December 19, 2025 10:48 PM GMTWe're writing this in our personal capacity. While…