Machine Learning AI in China and the United States AI News Team February 10, 2026 At a private dinner a few months ago, Jensen Huang apparently said what I’ve been…
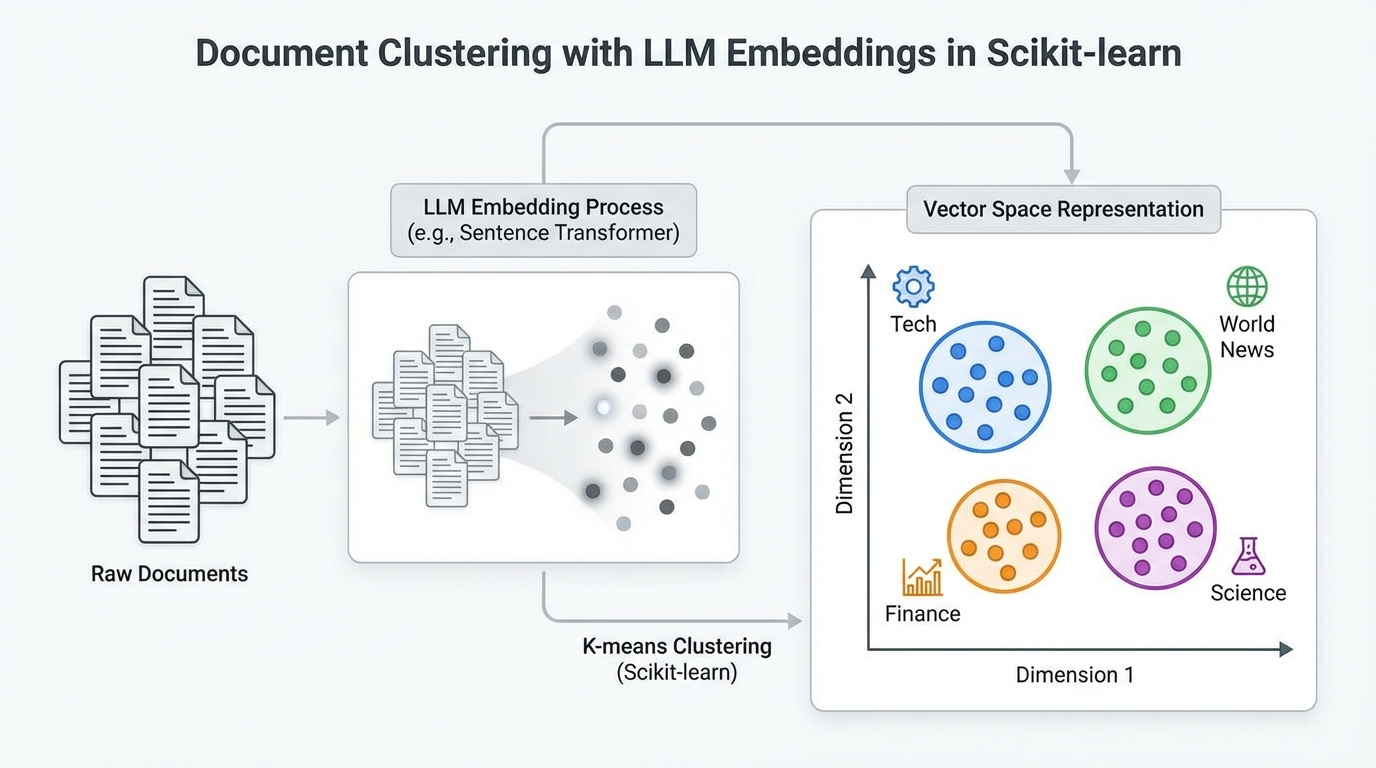
Machine Learning Document Clustering with LLM Embeddings in Scikit-learn AI News Team February 10, 2026 Imagine that you suddenly obtain a large collection of unclassified documents and are tasked with…
Machine Learning Helping kids and teens learn and grow online on Safer Internet Day AI News Team February 10, 2026 We’re sharing our latest updates designed to support families, kids and teens in the digital…
Machine Learning Parallel Track Transformers: Enabling Fast GPU Inference with Reduced Synchronization AI News Team February 10, 2026 Efficient large-scale inference of transformer-based large language models (LLMs) remains a fundamental systems challenge, frequently…
Machine Learning Designing Effective Multi-Agent Architectures AI News Team February 9, 2026 Papers on agentic and multi-agent systems (MAS) skyrocketed from 820 in 2024 to over 2,500…
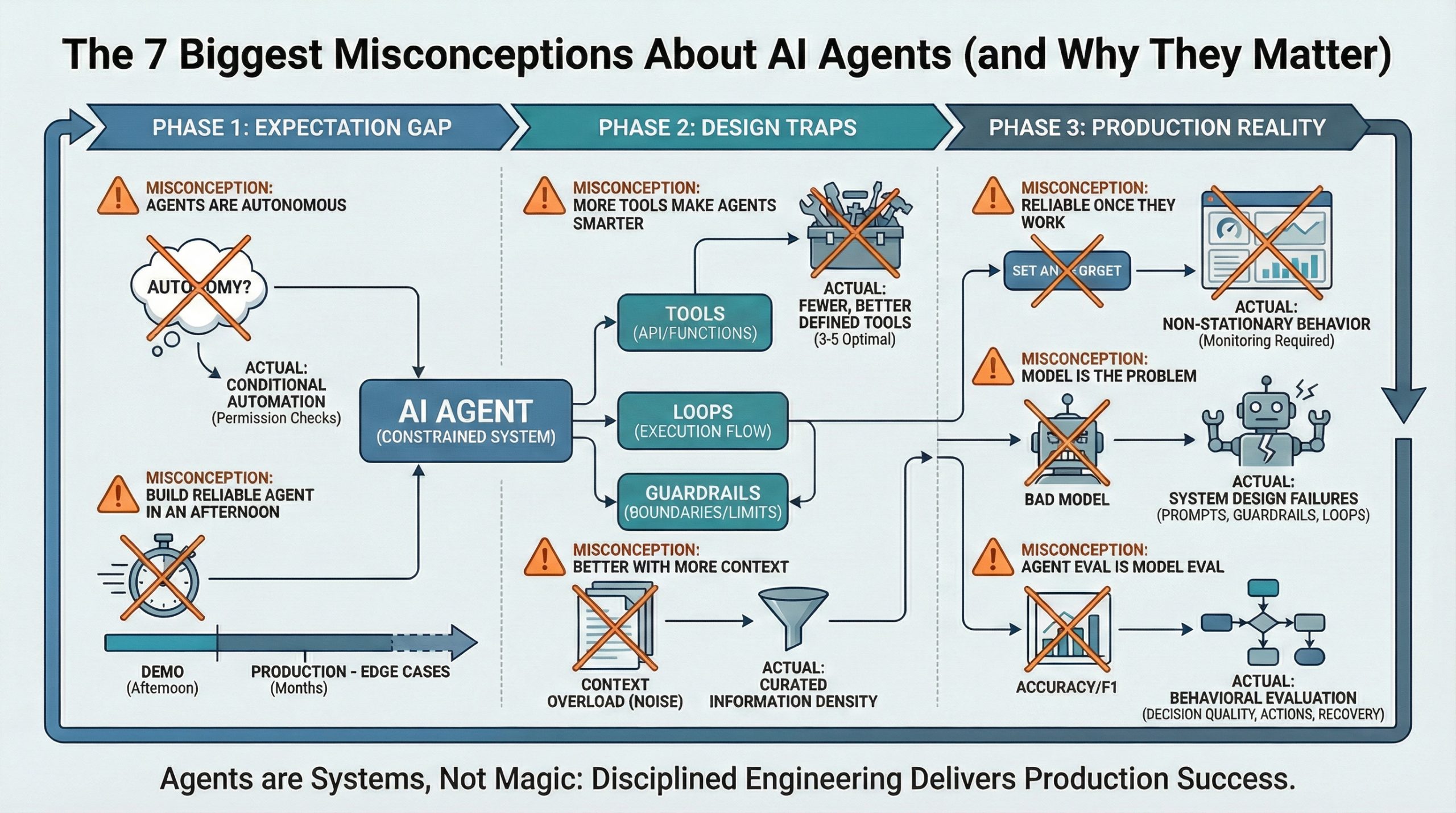
Machine Learning The 7 Biggest Misconceptions About AI Agents (and Why They Matter) AI News Team February 9, 2026 AI agents are everywhere.
Machine Learning Study: Platforms that rank the latest LLMs can be unreliable AI News Team February 9, 2026 Removing just a tiny fraction of the crowdsourced data that informs online ranking platforms can…
Machine Learning Reverse Engineering Your Software Architecture with Claude Code to Help Claude Code AI News Team February 6, 2026 This post first appeared on Nick Tune’s Medium page and is being republished here with…
Machine Learning How PARTs Assemble into Wholes: Learning the Relative Composition of Images AI News Team February 6, 2026 The composition of objects and their parts, along with object-object positional relationships, provides a rich…
Machine Learning VSSFlow: Unifying Video-conditioned Sound and Speech Generation via Joint Learning AI News Team February 6, 2026 Video-conditioned sound and speech generation, encompassing video-to-sound (V2S) and visual text-to-speech (VisualTTS) tasks, are conventionally…