
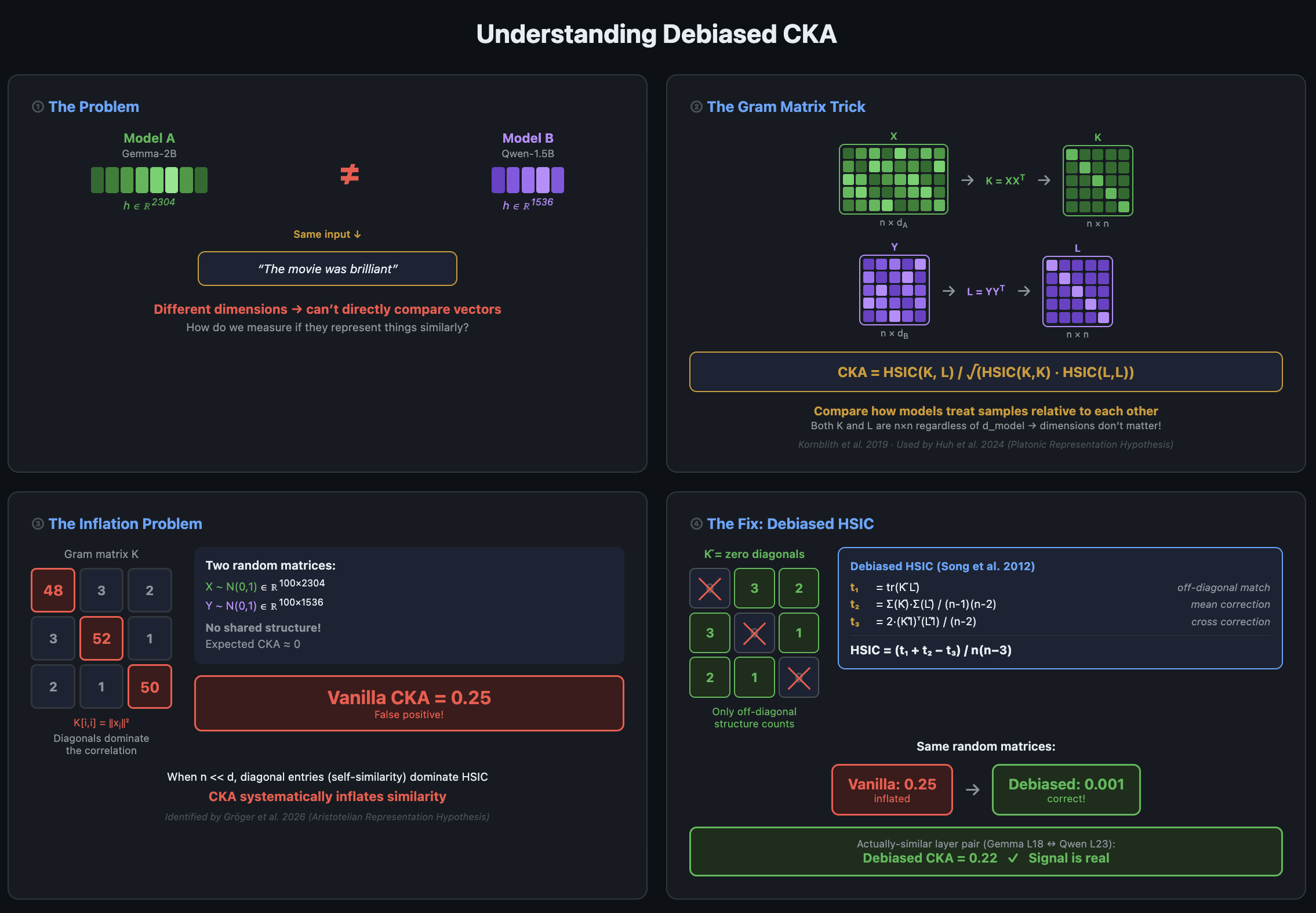
TL;DRTested activation similarities across different LLM families (Llama, Gemma, Qwen, Pythia) at small scale (1~3B) CKA Similarity : Cross-architectural activation similarity is statistically real, but weak. Within-family activations are much stronger (4~9x)Linear Transferability : Trained linear bridges for linear activation transfers for binary classification and next token prediction tasks. Within-family stands strong, cross-architecture yields better than random guessing, but not strong enough to be practically useful.Bottom Line : Shared structure across cross-architectures : broad linguistics / semantics only for now. Not enough for fine grained auditing tools.Code can be found here. This is my first interpretability research project, coming from a different field. I’m about 4 weeks into the field and learning and working solo. I’ve tried to be honest about the limitations and the mistakes I made, would really appreciate the feedback.MotivationAnthropic’s recent Activation Oracles paper was extremely fascinating, the fact that mere activations can be used to read a model’s latent states, that you can use internal activations themselves as an input context to detect innate behaviors like deception or sycophancy.One limitation to this, is that each oracle is architecture-specific: as in for every new model you need to train a custom oracle for it, and it does not generalize across different models. If concepts are represented in a relatively similar manner across architectures, this might suggest the mere probability that you can train an oracle on Llama and deploy it on Gemma, or more ambitiously train a model-agnostic oracle which takes standardized inputs, which would be a great deal for scalable oversight.The Platonic Representation Hypothesis (Huh et al., 2024) suggests exactly this fact, that internal model representations converge as scale increases, not only within LLMs but across various model architectures spanning vision models, language models and audio models.I wanted to test this empirically. Starting with measuring activation similarity with improved CKA metrics, and whether these shared structure is actually practical – carry over semantic knowledge that helps on real-world tasks, or is it just a correlational artifact with no functional significance?Diagrams / Animations were generated by the help of Claude Opus, alongside with some paraphrasing support.SetupAll experiments run on single NVIDIA A40. 6 models across 4 model families with 1~3B scale : Llama-3.2-1B, Llama-3.2-3B, Gemma-2-2B, Qwen2.5-1.5B, Pythia-1.4B, and Pythia-2.8B. Five model pairs were selected (4 cross-architecture : Gemma <-> Qwen, Llama <-> Pythia at 1B, 3B scale, Llama <-> Gemma) and 1 within-family (Llama 1B vs 3B) for positive control.Residual stream activations were extracted at 9 evenly-spaced relative layer depths, 10k prompts were used from NeelNanda/pile-10k.Three layers of analysis : 1) Debiased CKA to measure geometric similarity across models followed by a permutation test to measure its statistical significance2) Train linear bridges using multiple methods (Procrustes, full ridge, low-rank decomposition at various ranks) to map between cross-model activation spaces.3) Linear probe transfer for tasks : using 2) we train a linear probe on Model A, bridge Model B’s activations into Model A’s space and run A’s probe on them for binary classification tasks and next-token prediction tasks.Key Results(1) Debiased CKA Analysis : How close are model activations?Diagram 1. Explaining Rationale of CKA -> Debiased CKAThe naive problem arises : How to compare activations with different dimensions?Initial concern was that different models have different hidden dimensions, except for some coincidences. Gemma-2B has a d_model of 2,304 whereas Qwen-1.5B has one of 1,536. This makes it hard to design a “Rotation” vector which preserves dimension. Searching some previous literature, turns out that the standard answer is CKA (Centered Kernel Alignment, Kornblith et al. 2019). Instead of comparing activations directly, you sample N contexts and compute an N×N matrix of pairwise cosine similarities between the samples. Now, both matrices are the same size regardless of hidden dimension! CKA basically measures the correlation between these NxN matrices. The PRH paper was also built upon the CKA metric, that different models have this sort of concept of “Plato’s Theory of Ideas”.One problem of naively using the vanilla CKA itself, is that the correlations are inflated. The matrix diagonals are always 1.0 (same context, cosine similarity = 1.0), which is denoted by the diagram above. Therefore we end up with false positives indicating that different world models appear to share more “platonic truths” with each other, compared to actual reality.To tackle this problem, I used the I used the debiased HSIC estimator (Song et al., 2012) as a fix, across all the experiments. As the diagram shows, the main idea is that basically we snooze (zero out) the matrix diagonals prior to computing the correlations.One surprise was to find out that the original PRH paper was using the vanilla CKA with the debiasing correction, which ended up in artificially inflating the CKA values as stated above. Also found out that Gröger et al. (2026) addressed a similar concern : they were re-running the PRH claim with permutation calibrated metrics, and as a result a large proportion of the convergence was disappearing.Model Experiment SelectionEvalModel AModel BTyped_Ad_BMax CKAMean CKAALlama-1BPythia-1.4BCross-family204820480.2080.053BGemma-2BQwen-1.5BCross-family230415360.2220.112CLlama-1BLlama-3BWithin-family204830720.9140.605DLlama-3BPythia-2.8BCross-family307225600.1810.052ELlama-3BGemma-2BCross-family307223040.1840.100Cross-Family CKA SimilaritiesPlot 2. Cross-Architecture Models Debiased CKA across Multiple Layer DepthsFew noticeable patterns:Max Debiased CKAs similarly in ~0.2 range, average CKAs in 0.05~0.1 range. Higher than natural expected value of 0 (assuming independence) but generally weak (compared to results in PRH)Cross-architecture CKAs peak in the late layers, suggesting that deeper layers, where more semantic processing has occurred, share more structural similarity.In contrast, CKA of the last few layers drop off sharply, suggesting that the purpose of those layers are for specializing for architecture-specific next-token prediction via the unembedding matrix.Plot 3. Debiased CKA metrics across model pairsWithin Same Family (Llama 1b vs 3b)Plot 4. CKA Similarity within Llama 1b vs 3bVery high CKA values (Max 0.9, Mean 0.6), 4~9x higher compared to cross-architecture models.1B L0 vs 3B L0 shows 0.914, which initially surprised me (given that there is no semantic information accrued) until I realized both models share the same tokenizer and likely have similar embedding spaces, so it is actually unsurprising that the input representations are almost identical before any computation happens.One distinguishing pattern compared to cross-arch is that within Llama, the final layers L15 (1B) vs L27 (3B) shows a debiased CKA of 0.886. Contrary to the cross-architecture final layer CKA which was generally lower than the late-layer CKAs, here the final layers of Llama-1B and 3B have a seemingly high debiased CKA. Similar to the argument above, it is likely due to both models sharing a tokenizer and similar unembedding geometry.Permutation Tests : But is the cross-architecture signal statistically meaningful?Diagram 5. Shaping Permutation Tests for cross-architectural CKA valuesCross-architectural CKAs with a max of ~0.2 was underwhelming compared to what the Platonic Representation Hypothesis initially claimed, reaching a CKA of roughly 0.4 ~ 0.8 which was increasing as the size of the model increased.But given that we had debiased our CKAs, it is worth understanding if the values are statistically meaningful enough to suggest that there is a weak yet clear signal. At least it was higher than the natural baseline of 0, and given that the heatmaps suggest there was some similarity shared across model pairs (late layers having high CKAs).So we designed a permutation test where we shuffle the sample indices and compute CKA for the null distribution. We both test the permutation test for the max(CKA) for each cross-model pair (Layer L_A for model A, Layer L_B for model B, excluding the initial layer L0’s) and the mean across 81 pairs, in an attempt to avoid p-hacking. As a result, when we test 500 permutations with same 10k samples, none of the perms exceeded the observed debiased CKA values (p-value of <0.002).However this doesn’t solve any imminent questions regarding the “strength of the signal”, as in order to upstage the findings to a practical level, we need to address if the statistical significance can transform into something genuine in terms of transferability across cross-arch models. As in, is the absolute CKA of ~0.2 sufficient enough to carry functional information via a linear mapping from model A -> B, is still unanswered. And although the priors of this being available is low given the small model sizes, if we can find at least some convincing evidence in a subset of tasks, it might open some gates for generalizable interpretability, generalizable oracles, and so on.(2) Functional Transferability : Binary ClassificationsDiagram 6. Designing Linear Activation Transfer for Binary Classification TaskIn the previous section, we have found some generalizable structure for cross-architectural models. Here we try to test if the statistical “similarity” actually does something.We get the idea from linear probes for binary classification tasks, as a nonlinear probe is subject to overfit (as we all know, linearity combined with nonlinearity can do magic!).So we train a LR (logistic regression) binary classifier on Model A’s activations, say for example “is this text toxic?”, and then transfer it into Model B’s activations, using linear mapping (which we denote as “bridging”).If the transferred probe has significant accuracy compared to the accuracy of Model B’s linear probe trained on itself, then it suggests that certain task-relevant structures are preservable, which is a slightly stronger claim compared to the geometric similarity being statistically meaningful.The Linear Bridging Methodology (Details)This part is just explaining the architectural details, feel free to skip or skim.The basic bridging pipeline is simple. We will get the max CKA-pair calculated from Section 1 for the (Model A, Model B) pair. For the actual pair used – Gemma-2B vs Qwen-1.5B we use L18, L23 respectively. Then as mentioned above, we aim to learn a linear mapping W from Model A’s activations to Model B’s (W_map). W’s weights and biases are trained on general text (10k). Then for a specific binary classification task, we train a linear probe in Model A, using the sample texts for the task (W_probe)Finally, for the target evaluation we get the activations from Model A’s layer (h_target), and then matrix-multiplied with W_probe x W_map which is then evaluated with Model B’s linear probe, trained independently.There are multiple choices to design W_map, which is in nature carries 2304 x 1536 parameters, which can be highly subject to overfit. Here we try multiple approaches, for same dimensional models (Eval A) we use Procrustes rotation, and for different dimensional models we try using low-rank factorization W = AB to see if the information transfer is doable with low rank.(TMI : Eval A’s models were chosen deliberately, from the fact that Llama-1B and Pythia-1.4B both have a d_model of 2048, thus matching the dimensionality of their activation spaces, enabling the orthogonal Procrustes rotation for the choice of the mapping matrix W)We tested multiple bridge types at different ranks:MethodWhat it doesConstraintsOrthogonal ProcrustesSVD-based rotationSame dimension only (Eval A)Ridge regressionFull-rank linear map with L2Any dimension pairLow-rank (k = 4~256)W = A×B factorizationRank-constrainedLASSOSparse linear map with L1Any dimension pairImportant Note, is that like there is a classic bias-variance tradeoff problem, as low-rank bridges of (k = 4, 8) will be rank-constrained therefore inducing high bias in case the true latent mapping needs more dimensions. However high-rank, all the way up to pure ridge regression will have risk of overfitting as the # of weights far exceeds the number of samples.Ok, back to the binary classification.We tested on three binary classification tasks noted below:TaskDatasetLabelsWhat it testsTopic (AG News)AG News subsetSports vs. notCoarse document-level topicToxicityToxiGenToxic vs. benignSafety-relevant content detectionSentiment (SST-2)Stanford SentimentPositive vs. negativeFine-grained linguistic featureThese tasks were chosen to range across different topics, such as sentiment, safety related, or specific domain-related (sports), and we will test whether the linear bridges trained on general text can classify these binary tasks effectively.In order to provide a useful baseline, we trained frozen bridges vs task-specific bridges. A frozen bridge is the approach explained above where we train the weights based on the general text (pile-10k). On the other hand, the task-specific bridge is training on the exact same task data where the linear probe for model A was trained on. This lets the bridge overfit to task-specific features thus inflating the accuracy of the transfer. Although the accuracy of the task-specific bridges is not a strong evidence due to the reason, we still use it as a baseline to compare against the frozen bridges, to test whether the general cross-model structure carry generalizable structure, basically testing an OOS generalization.Binary Classification Task Results : Cross-Arch vs Intra-FamilyPlot 7. Testing for Binary Classification Results on Linear Cross-Model TransfersA brief walkthrough on the lines on the legend:Target native (purple dashed) : Linear probe trained / tested directly on Model B’s activations. This serves as a theoretical ceiling (except noise), best you could possibly do.Source native (green solid) : Linear probe trained / tested on Model A to provide W_probe. Shows how good is the original probe prior to the activation transfer.Frozen (pile-10k) (red): The probe transferred through a linear bridge trained on general text. This is the stronger test.Task-specific (blue): The probe transferred through a linear bridge learned on the task data itself. This is a more weaker, corrupted test given that the bridge has indirectly seen the labels.Chance (green dashed): The classic 50% for binary classification. It means the transfer has learned nothing if we are at this level.ResultsIntra-family model (Llama 1B → 3B) transferability is STRONG.Generally strong frozen bridge performance across sentiment, alignment (toxicity), and domain identification. For the AG news dataset specifically, with a rank 4 factorization it starts at ~50% (equal to random choice), barely improves up to rank 32, but then improves rapidly by rank 128, indicating a phase transition. By rank 128, it stands at 97% accuracy, nearly matching that of the target native at 98.6%.Sentiment analysis shows the same pattern yet being less dramatic. It similarly starts at ~50% with low rank (up to rank 16), and by rank 256 it achieves ~75% accuracy (target native = 86.2%, source native = 84.5%). Toxicity classification is the most flattest and seems rank-independent to a certain extent, but can at least see the monotonic improvement.Cross-architecture models (Gemma 2B -> Qwen 1.5B) is WEAK and INCONSISTENT.Compared to Intra-family transfers, the results are significantly weak. The frozen bridge accuracies all achieve >50% (better than random prediction) by rank 256, but SST2 | ToxiGen both do not see any improvement based on rank, and falls short compared to Target Native accuracy.Another observation is that the frozen bridge vs task-specific bridge results are inconsistent with intuition. Generally we would expect the task-specific bridge to outperform the frozen dataset given that it can include some task/domain – specific structure. The only case where we observe >70% accuracy (AG News dataset) on frozen dataset, is also very puzzling that the task-specific bridge struggled to even beat random choice on the same task.SettingAG NewsSST-2ToxicityCross-archFrozen wins (0.713 vs 0.502)~Tied (both at chance)Frozen wins (0.636 vs 0.589)Within-family~Tied at high rankTask-specific wins (0.811 vs 0.667)Task-specific wins (0.770 vs 0.739)Honest Summary : Intra-family activation transfers work, and generally scales with higher rank. However cross-architecture activation transfers are existent yet generally weak, and hard to explain. The level of accuracy is nowhere near practical usefulness.(3) Functional Transferability : Next Token PredictionDiagram 8. Next-Token Prediction Linear Probe TransferDiagram 9. Next-token prediction for Cross-ArchitecturesWe have observed binary classification transfers were strong within-family, but weak/inconclusive for cross-architectural model transfers. That brings us to a slightly harder task of transferability for a next-token prediction linear probe, for the entire vocabulary. This is intended to evaluate if the bridge can preserve fine-grained linguistic structure, a much higher bar than to just a binary classification task. Plot 10. Llama-1B vs Llama-3B intra-family transferMethodTop-1 Accuracy% of OracleSource native (Llama-1B)63.9%—Low-rank r419.1%30%Low-rank r3235.4%56%Low-rank r12847.7%75%Low-rank r25651.2%81%Ridge (full rank)58.9%93%Oracle (Llama-3B native)63.4%100%For Intra-family transfer (which we use Llama-1B vs -3B) this setup is easily replicable, as we use the same methodology of training linear probes on 1B L15 and 3B L27, and then train the linear bridge for the transfer.For the top-1 accuracy prediction we see a monotonic increase of accuracy as we increase the ranks from 4 -> 256, and full ridge regression yields 58.9% accuracy, which is 93% of the theoretical ceiling of the oracle (63.4%), which suggests that within-family transfer still sits strong.However it is impossible to use this method to evaluate the corresponding cross-architectural model transferability, because they have different dictionaries and different tokenizers (Gemma / Qwen).To address this issue, we try two methods:1) Simple method where we compare the exact same string (Diagram 9 : Experiment A)Basically we will decode each token ID in each dictionary into the raw string, also removing the tokenizer-specific prefixes (▁ (Gemma/SentencePiece) and Ġ (Qwen/tiktoken)), which will enable us to compare apples to apples, bananas to bananas. One caveat to this is that the strings doesn’t map 1:1. In fact, there are 83,499 shared token strings post-decoding between Gemma & Qwen (Gemma-2B : 256,000 total tokens | Qwen-1.5B : 151,936 total tokens). From the 83,499 token strings we choose the top 500 most frequent tokens to ensure there is sufficient sample sizes for each class suitable for training the probe.Plot 11. Gemma -> Qwen Cross-Architecture Next Token PredictionMethodTop-1Top-5Source native (Gemma)66.8%82.1%Target oracle (Qwen)75.3%86.2%Cross-model oracle (ceiling)10.3%20.2%Best low-rank (r128/r256)4.6%15.9%Ridge (full)4.9%18.0%The linear transfer caps out at 4.9% top-1 accuracy even with full rank transfer, also don’t observe a monotonic increase as we’ve seen in the case for intra-family transfers. This is also due to the fact that the theoretical ceiling of 10.3%. This is the accuracy of the next token prediction – alignment between cross models when asked the same context, therefore the poor transferability could be an artifact of the limit of the cross-architecture alignment itself, not the transferability aspect. 2) Classify tokens into POS subcategories and predict subcategory (Diagram 9 : Experiment B)Because top-1 token prediction (even a reasonable top-K) is often difficult as we saw from the result (systematically different next-token prediction), we try an alternative method which is further grouping the token strings into POS (part-of-speech) subcategories (noun, verb, adjective, …). This proves a much weaker claim of a linguistic structure transfer rather than a semantic token-level prediction.Plot 12. POS Tag token transferabilityThe POS subcategory transfers show a similar story. Within-family transfer generally monotonically increases its accuracy as we increase the capacity (rank). It even slightly outperforms the target oracle accuracy benchmark (48.5%), at rank 128 (49.3% accuracy). The outperformance is probably noise, but it does prove that within-family transfer is strong enough to replicate probes which are trained on itself, proving that activations can be linearly transferable across models.Cross-architectural transfers show improvement vs top-1 token prediction accuracy, ranging 25~30% accuracy where target oracle benchmark stands at 37.8%, which is 65~80% of the oracle. However it still has the pattern where increasing rank doesn’t help the accuracy, and also the POS classification may be slightly inflated, where the familiarity of each token class (nouns, verbs appearing much more) could be a bigger factor where the probe learns the frequency priors compared to innate predictability on the linguistic structure.Conclusion : What This Means (And Doesn’t Mean)Debiased-CKA analysis suggests cross-architectural activation similarity is statistically significant yet weak, with max debiased CKA around ~0.2 (mean = 0.05 ~ 0.1), confirmed by permutation tests with p < 0.002. Intra-family (Llama-1B vs Llama-3B) is much stronger, CKA averaging ~0.6. We challenge the Platonic Representation Hypothesis that models will converge to a mathematically interpretable “platonic ideal”, at least not supported at this scale. Whether this holds at larger scales remains an open question.We then try experimenting whether the “statistically meaningful” CKA metrics hold for actual practical semantic transferability, by introducing a linear bridging method and testing multiple linear probes spanning tasks as easy as binary classification to next-token prediction.For both binary classification and next-token prediction tasks, within-family transfer (Llama-1B vs -3B) stands strong, averaging >90% of the accuracy of the target linear probe trained on itself. However cross-architectural transfers are yet questionable regarding the practicality, as we observe weak and inconsistent results (frozen bridges outperforming task-specific bridges, transferability flatlining even when increasing the dimensionality of the transfer). Still, we observe that a weaker version holds of cross-architectural models sharing coarse linguistic features or at least improving some binary classification tasks predictions.For AI interpretability research: This project started with an ambitious objective whether to see if activation oracles can generalize across different models, which would be an interesting breakthrough by itself. However it does seem like this is yet to be supported without meticulous design to enhance generalizability, at least in this scale (1B-3B). Whether the transferability will improve once model sizes increase remains a question, however looking at the results here scaling alone may not be sufficient, might need targeted interventions.Caveats and LimitationsI want to be clear about what this work doesn’t show:Scale. All models we’ve tested are in the 1~3B parameter range. The Platonic Representation Hypothesis predicts a platonic convergence increasing with model size, therefore results may differ as we scale up to 70B+. I didn’t have the compute budget to test this.Single Pair for Testing. In this project we only test 1 cross-architecture transfer (Gemma -> Qwen), and 1 within-family transfer (Llama-1B -> Llama-3B). Would be better to test across different pairs and see whether the results generalize.Linear Bridge Deepdive. There needs to be more sophisticated research done in order to understand how the bridges worked under the hoods. As in, what are the recognizable patterns, does it relate to the dimensions of the binary “task” vector, etc?Dataset Dependency. All the probes and tasks were trained and tested on the same text corpus. Would be better if we can see if the learned bridges can actually generalize to different domains.ReferencesHuh et al. (2024). The Platonic Representation Hypothesis. ICML 2024.Gröger, Wen & Brbić (2026). Revisiting the Platonic Representation Hypothesis: An Aristotelian View.Kornblith et al. (2019). Similarity of Neural Network Representations Revisited. ICML 2019.Song et al. (2012). Feature selection via dependence maximization. JMLR.Roger et al. (2025). Activation Space Interventions Transfer Across Large Language Models.Karvonen et al. (2025). Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers.Discuss Read More
Cross-Model Activation Generalizability Isn’t Strong (Yet)
TL;DRTested activation similarities across different LLM families (Llama, Gemma, Qwen, Pythia) at small scale (1~3B) CKA Similarity : Cross-architectural activation similarity is statistically real, but weak. Within-family activations are much stronger (4~9x)Linear Transferability : Trained linear bridges for linear activation transfers for binary classification and next token prediction tasks. Within-family stands strong, cross-architecture yields better than random guessing, but not strong enough to be practically useful.Bottom Line : Shared structure across cross-architectures : broad linguistics / semantics only for now. Not enough for fine grained auditing tools.Code can be found here. This is my first interpretability research project, coming from a different field. I’m about 4 weeks into the field and learning and working solo. I’ve tried to be honest about the limitations and the mistakes I made, would really appreciate the feedback.MotivationAnthropic’s recent Activation Oracles paper was extremely fascinating, the fact that mere activations can be used to read a model’s latent states, that you can use internal activations themselves as an input context to detect innate behaviors like deception or sycophancy.One limitation to this, is that each oracle is architecture-specific: as in for every new model you need to train a custom oracle for it, and it does not generalize across different models. If concepts are represented in a relatively similar manner across architectures, this might suggest the mere probability that you can train an oracle on Llama and deploy it on Gemma, or more ambitiously train a model-agnostic oracle which takes standardized inputs, which would be a great deal for scalable oversight.The Platonic Representation Hypothesis (Huh et al., 2024) suggests exactly this fact, that internal model representations converge as scale increases, not only within LLMs but across various model architectures spanning vision models, language models and audio models.I wanted to test this empirically. Starting with measuring activation similarity with improved CKA metrics, and whether these shared structure is actually practical – carry over semantic knowledge that helps on real-world tasks, or is it just a correlational artifact with no functional significance?Diagrams / Animations were generated by the help of Claude Opus, alongside with some paraphrasing support.SetupAll experiments run on single NVIDIA A40. 6 models across 4 model families with 1~3B scale : Llama-3.2-1B, Llama-3.2-3B, Gemma-2-2B, Qwen2.5-1.5B, Pythia-1.4B, and Pythia-2.8B. Five model pairs were selected (4 cross-architecture : Gemma <-> Qwen, Llama <-> Pythia at 1B, 3B scale, Llama <-> Gemma) and 1 within-family (Llama 1B vs 3B) for positive control.Residual stream activations were extracted at 9 evenly-spaced relative layer depths, 10k prompts were used from NeelNanda/pile-10k.Three layers of analysis : 1) Debiased CKA to measure geometric similarity across models followed by a permutation test to measure its statistical significance2) Train linear bridges using multiple methods (Procrustes, full ridge, low-rank decomposition at various ranks) to map between cross-model activation spaces.3) Linear probe transfer for tasks : using 2) we train a linear probe on Model A, bridge Model B’s activations into Model A’s space and run A’s probe on them for binary classification tasks and next-token prediction tasks.Key Results(1) Debiased CKA Analysis : How close are model activations?Diagram 1. Explaining Rationale of CKA -> Debiased CKAThe naive problem arises : How to compare activations with different dimensions?Initial concern was that different models have different hidden dimensions, except for some coincidences. Gemma-2B has a d_model of 2,304 whereas Qwen-1.5B has one of 1,536. This makes it hard to design a “Rotation” vector which preserves dimension. Searching some previous literature, turns out that the standard answer is CKA (Centered Kernel Alignment, Kornblith et al. 2019). Instead of comparing activations directly, you sample N contexts and compute an N×N matrix of pairwise cosine similarities between the samples. Now, both matrices are the same size regardless of hidden dimension! CKA basically measures the correlation between these NxN matrices. The PRH paper was also built upon the CKA metric, that different models have this sort of concept of “Plato’s Theory of Ideas”.One problem of naively using the vanilla CKA itself, is that the correlations are inflated. The matrix diagonals are always 1.0 (same context, cosine similarity = 1.0), which is denoted by the diagram above. Therefore we end up with false positives indicating that different world models appear to share more “platonic truths” with each other, compared to actual reality.To tackle this problem, I used the I used the debiased HSIC estimator (Song et al., 2012) as a fix, across all the experiments. As the diagram shows, the main idea is that basically we snooze (zero out) the matrix diagonals prior to computing the correlations.One surprise was to find out that the original PRH paper was using the vanilla CKA with the debiasing correction, which ended up in artificially inflating the CKA values as stated above. Also found out that Gröger et al. (2026) addressed a similar concern : they were re-running the PRH claim with permutation calibrated metrics, and as a result a large proportion of the convergence was disappearing.Model Experiment SelectionEvalModel AModel BTyped_Ad_BMax CKAMean CKAALlama-1BPythia-1.4BCross-family204820480.2080.053BGemma-2BQwen-1.5BCross-family230415360.2220.112CLlama-1BLlama-3BWithin-family204830720.9140.605DLlama-3BPythia-2.8BCross-family307225600.1810.052ELlama-3BGemma-2BCross-family307223040.1840.100Cross-Family CKA SimilaritiesPlot 2. Cross-Architecture Models Debiased CKA across Multiple Layer DepthsFew noticeable patterns:Max Debiased CKAs similarly in ~0.2 range, average CKAs in 0.05~0.1 range. Higher than natural expected value of 0 (assuming independence) but generally weak (compared to results in PRH)Cross-architecture CKAs peak in the late layers, suggesting that deeper layers, where more semantic processing has occurred, share more structural similarity.In contrast, CKA of the last few layers drop off sharply, suggesting that the purpose of those layers are for specializing for architecture-specific next-token prediction via the unembedding matrix.Plot 3. Debiased CKA metrics across model pairsWithin Same Family (Llama 1b vs 3b)Plot 4. CKA Similarity within Llama 1b vs 3bVery high CKA values (Max 0.9, Mean 0.6), 4~9x higher compared to cross-architecture models.1B L0 vs 3B L0 shows 0.914, which initially surprised me (given that there is no semantic information accrued) until I realized both models share the same tokenizer and likely have similar embedding spaces, so it is actually unsurprising that the input representations are almost identical before any computation happens.One distinguishing pattern compared to cross-arch is that within Llama, the final layers L15 (1B) vs L27 (3B) shows a debiased CKA of 0.886. Contrary to the cross-architecture final layer CKA which was generally lower than the late-layer CKAs, here the final layers of Llama-1B and 3B have a seemingly high debiased CKA. Similar to the argument above, it is likely due to both models sharing a tokenizer and similar unembedding geometry.Permutation Tests : But is the cross-architecture signal statistically meaningful?Diagram 5. Shaping Permutation Tests for cross-architectural CKA valuesCross-architectural CKAs with a max of ~0.2 was underwhelming compared to what the Platonic Representation Hypothesis initially claimed, reaching a CKA of roughly 0.4 ~ 0.8 which was increasing as the size of the model increased.But given that we had debiased our CKAs, it is worth understanding if the values are statistically meaningful enough to suggest that there is a weak yet clear signal. At least it was higher than the natural baseline of 0, and given that the heatmaps suggest there was some similarity shared across model pairs (late layers having high CKAs).So we designed a permutation test where we shuffle the sample indices and compute CKA for the null distribution. We both test the permutation test for the max(CKA) for each cross-model pair (Layer L_A for model A, Layer L_B for model B, excluding the initial layer L0’s) and the mean across 81 pairs, in an attempt to avoid p-hacking. As a result, when we test 500 permutations with same 10k samples, none of the perms exceeded the observed debiased CKA values (p-value of <0.002).However this doesn’t solve any imminent questions regarding the “strength of the signal”, as in order to upstage the findings to a practical level, we need to address if the statistical significance can transform into something genuine in terms of transferability across cross-arch models. As in, is the absolute CKA of ~0.2 sufficient enough to carry functional information via a linear mapping from model A -> B, is still unanswered. And although the priors of this being available is low given the small model sizes, if we can find at least some convincing evidence in a subset of tasks, it might open some gates for generalizable interpretability, generalizable oracles, and so on.(2) Functional Transferability : Binary ClassificationsDiagram 6. Designing Linear Activation Transfer for Binary Classification TaskIn the previous section, we have found some generalizable structure for cross-architectural models. Here we try to test if the statistical “similarity” actually does something.We get the idea from linear probes for binary classification tasks, as a nonlinear probe is subject to overfit (as we all know, linearity combined with nonlinearity can do magic!).So we train a LR (logistic regression) binary classifier on Model A’s activations, say for example “is this text toxic?”, and then transfer it into Model B’s activations, using linear mapping (which we denote as “bridging”).If the transferred probe has significant accuracy compared to the accuracy of Model B’s linear probe trained on itself, then it suggests that certain task-relevant structures are preservable, which is a slightly stronger claim compared to the geometric similarity being statistically meaningful.The Linear Bridging Methodology (Details)This part is just explaining the architectural details, feel free to skip or skim.The basic bridging pipeline is simple. We will get the max CKA-pair calculated from Section 1 for the (Model A, Model B) pair. For the actual pair used – Gemma-2B vs Qwen-1.5B we use L18, L23 respectively. Then as mentioned above, we aim to learn a linear mapping W from Model A’s activations to Model B’s (W_map). W’s weights and biases are trained on general text (10k). Then for a specific binary classification task, we train a linear probe in Model A, using the sample texts for the task (W_probe)Finally, for the target evaluation we get the activations from Model A’s layer (h_target), and then matrix-multiplied with W_probe x W_map which is then evaluated with Model B’s linear probe, trained independently.There are multiple choices to design W_map, which is in nature carries 2304 x 1536 parameters, which can be highly subject to overfit. Here we try multiple approaches, for same dimensional models (Eval A) we use Procrustes rotation, and for different dimensional models we try using low-rank factorization W = AB to see if the information transfer is doable with low rank.(TMI : Eval A’s models were chosen deliberately, from the fact that Llama-1B and Pythia-1.4B both have a d_model of 2048, thus matching the dimensionality of their activation spaces, enabling the orthogonal Procrustes rotation for the choice of the mapping matrix W)We tested multiple bridge types at different ranks:MethodWhat it doesConstraintsOrthogonal ProcrustesSVD-based rotationSame dimension only (Eval A)Ridge regressionFull-rank linear map with L2Any dimension pairLow-rank (k = 4~256)W = A×B factorizationRank-constrainedLASSOSparse linear map with L1Any dimension pairImportant Note, is that like there is a classic bias-variance tradeoff problem, as low-rank bridges of (k = 4, 8) will be rank-constrained therefore inducing high bias in case the true latent mapping needs more dimensions. However high-rank, all the way up to pure ridge regression will have risk of overfitting as the # of weights far exceeds the number of samples.Ok, back to the binary classification.We tested on three binary classification tasks noted below:TaskDatasetLabelsWhat it testsTopic (AG News)AG News subsetSports vs. notCoarse document-level topicToxicityToxiGenToxic vs. benignSafety-relevant content detectionSentiment (SST-2)Stanford SentimentPositive vs. negativeFine-grained linguistic featureThese tasks were chosen to range across different topics, such as sentiment, safety related, or specific domain-related (sports), and we will test whether the linear bridges trained on general text can classify these binary tasks effectively.In order to provide a useful baseline, we trained frozen bridges vs task-specific bridges. A frozen bridge is the approach explained above where we train the weights based on the general text (pile-10k). On the other hand, the task-specific bridge is training on the exact same task data where the linear probe for model A was trained on. This lets the bridge overfit to task-specific features thus inflating the accuracy of the transfer. Although the accuracy of the task-specific bridges is not a strong evidence due to the reason, we still use it as a baseline to compare against the frozen bridges, to test whether the general cross-model structure carry generalizable structure, basically testing an OOS generalization.Binary Classification Task Results : Cross-Arch vs Intra-FamilyPlot 7. Testing for Binary Classification Results on Linear Cross-Model TransfersA brief walkthrough on the lines on the legend:Target native (purple dashed) : Linear probe trained / tested directly on Model B’s activations. This serves as a theoretical ceiling (except noise), best you could possibly do.Source native (green solid) : Linear probe trained / tested on Model A to provide W_probe. Shows how good is the original probe prior to the activation transfer.Frozen (pile-10k) (red): The probe transferred through a linear bridge trained on general text. This is the stronger test.Task-specific (blue): The probe transferred through a linear bridge learned on the task data itself. This is a more weaker, corrupted test given that the bridge has indirectly seen the labels.Chance (green dashed): The classic 50% for binary classification. It means the transfer has learned nothing if we are at this level.ResultsIntra-family model (Llama 1B → 3B) transferability is STRONG.Generally strong frozen bridge performance across sentiment, alignment (toxicity), and domain identification. For the AG news dataset specifically, with a rank 4 factorization it starts at ~50% (equal to random choice), barely improves up to rank 32, but then improves rapidly by rank 128, indicating a phase transition. By rank 128, it stands at 97% accuracy, nearly matching that of the target native at 98.6%.Sentiment analysis shows the same pattern yet being less dramatic. It similarly starts at ~50% with low rank (up to rank 16), and by rank 256 it achieves ~75% accuracy (target native = 86.2%, source native = 84.5%). Toxicity classification is the most flattest and seems rank-independent to a certain extent, but can at least see the monotonic improvement.Cross-architecture models (Gemma 2B -> Qwen 1.5B) is WEAK and INCONSISTENT.Compared to Intra-family transfers, the results are significantly weak. The frozen bridge accuracies all achieve >50% (better than random prediction) by rank 256, but SST2 | ToxiGen both do not see any improvement based on rank, and falls short compared to Target Native accuracy.Another observation is that the frozen bridge vs task-specific bridge results are inconsistent with intuition. Generally we would expect the task-specific bridge to outperform the frozen dataset given that it can include some task/domain – specific structure. The only case where we observe >70% accuracy (AG News dataset) on frozen dataset, is also very puzzling that the task-specific bridge struggled to even beat random choice on the same task.SettingAG NewsSST-2ToxicityCross-archFrozen wins (0.713 vs 0.502)~Tied (both at chance)Frozen wins (0.636 vs 0.589)Within-family~Tied at high rankTask-specific wins (0.811 vs 0.667)Task-specific wins (0.770 vs 0.739)Honest Summary : Intra-family activation transfers work, and generally scales with higher rank. However cross-architecture activation transfers are existent yet generally weak, and hard to explain. The level of accuracy is nowhere near practical usefulness.(3) Functional Transferability : Next Token PredictionDiagram 8. Next-Token Prediction Linear Probe TransferDiagram 9. Next-token prediction for Cross-ArchitecturesWe have observed binary classification transfers were strong within-family, but weak/inconclusive for cross-architectural model transfers. That brings us to a slightly harder task of transferability for a next-token prediction linear probe, for the entire vocabulary. This is intended to evaluate if the bridge can preserve fine-grained linguistic structure, a much higher bar than to just a binary classification task. Plot 10. Llama-1B vs Llama-3B intra-family transferMethodTop-1 Accuracy% of OracleSource native (Llama-1B)63.9%—Low-rank r419.1%30%Low-rank r3235.4%56%Low-rank r12847.7%75%Low-rank r25651.2%81%Ridge (full rank)58.9%93%Oracle (Llama-3B native)63.4%100%For Intra-family transfer (which we use Llama-1B vs -3B) this setup is easily replicable, as we use the same methodology of training linear probes on 1B L15 and 3B L27, and then train the linear bridge for the transfer.For the top-1 accuracy prediction we see a monotonic increase of accuracy as we increase the ranks from 4 -> 256, and full ridge regression yields 58.9% accuracy, which is 93% of the theoretical ceiling of the oracle (63.4%), which suggests that within-family transfer still sits strong.However it is impossible to use this method to evaluate the corresponding cross-architectural model transferability, because they have different dictionaries and different tokenizers (Gemma / Qwen).To address this issue, we try two methods:1) Simple method where we compare the exact same string (Diagram 9 : Experiment A)Basically we will decode each token ID in each dictionary into the raw string, also removing the tokenizer-specific prefixes (▁ (Gemma/SentencePiece) and Ġ (Qwen/tiktoken)), which will enable us to compare apples to apples, bananas to bananas. One caveat to this is that the strings doesn’t map 1:1. In fact, there are 83,499 shared token strings post-decoding between Gemma & Qwen (Gemma-2B : 256,000 total tokens | Qwen-1.5B : 151,936 total tokens). From the 83,499 token strings we choose the top 500 most frequent tokens to ensure there is sufficient sample sizes for each class suitable for training the probe.Plot 11. Gemma -> Qwen Cross-Architecture Next Token PredictionMethodTop-1Top-5Source native (Gemma)66.8%82.1%Target oracle (Qwen)75.3%86.2%Cross-model oracle (ceiling)10.3%20.2%Best low-rank (r128/r256)4.6%15.9%Ridge (full)4.9%18.0%The linear transfer caps out at 4.9% top-1 accuracy even with full rank transfer, also don’t observe a monotonic increase as we’ve seen in the case for intra-family transfers. This is also due to the fact that the theoretical ceiling of 10.3%. This is the accuracy of the next token prediction – alignment between cross models when asked the same context, therefore the poor transferability could be an artifact of the limit of the cross-architecture alignment itself, not the transferability aspect. 2) Classify tokens into POS subcategories and predict subcategory (Diagram 9 : Experiment B)Because top-1 token prediction (even a reasonable top-K) is often difficult as we saw from the result (systematically different next-token prediction), we try an alternative method which is further grouping the token strings into POS (part-of-speech) subcategories (noun, verb, adjective, …). This proves a much weaker claim of a linguistic structure transfer rather than a semantic token-level prediction.Plot 12. POS Tag token transferabilityThe POS subcategory transfers show a similar story. Within-family transfer generally monotonically increases its accuracy as we increase the capacity (rank). It even slightly outperforms the target oracle accuracy benchmark (48.5%), at rank 128 (49.3% accuracy). The outperformance is probably noise, but it does prove that within-family transfer is strong enough to replicate probes which are trained on itself, proving that activations can be linearly transferable across models.Cross-architectural transfers show improvement vs top-1 token prediction accuracy, ranging 25~30% accuracy where target oracle benchmark stands at 37.8%, which is 65~80% of the oracle. However it still has the pattern where increasing rank doesn’t help the accuracy, and also the POS classification may be slightly inflated, where the familiarity of each token class (nouns, verbs appearing much more) could be a bigger factor where the probe learns the frequency priors compared to innate predictability on the linguistic structure.Conclusion : What This Means (And Doesn’t Mean)Debiased-CKA analysis suggests cross-architectural activation similarity is statistically significant yet weak, with max debiased CKA around ~0.2 (mean = 0.05 ~ 0.1), confirmed by permutation tests with p < 0.002. Intra-family (Llama-1B vs Llama-3B) is much stronger, CKA averaging ~0.6. We challenge the Platonic Representation Hypothesis that models will converge to a mathematically interpretable “platonic ideal”, at least not supported at this scale. Whether this holds at larger scales remains an open question.We then try experimenting whether the “statistically meaningful” CKA metrics hold for actual practical semantic transferability, by introducing a linear bridging method and testing multiple linear probes spanning tasks as easy as binary classification to next-token prediction.For both binary classification and next-token prediction tasks, within-family transfer (Llama-1B vs -3B) stands strong, averaging >90% of the accuracy of the target linear probe trained on itself. However cross-architectural transfers are yet questionable regarding the practicality, as we observe weak and inconsistent results (frozen bridges outperforming task-specific bridges, transferability flatlining even when increasing the dimensionality of the transfer). Still, we observe that a weaker version holds of cross-architectural models sharing coarse linguistic features or at least improving some binary classification tasks predictions.For AI interpretability research: This project started with an ambitious objective whether to see if activation oracles can generalize across different models, which would be an interesting breakthrough by itself. However it does seem like this is yet to be supported without meticulous design to enhance generalizability, at least in this scale (1B-3B). Whether the transferability will improve once model sizes increase remains a question, however looking at the results here scaling alone may not be sufficient, might need targeted interventions.Caveats and LimitationsI want to be clear about what this work doesn’t show:Scale. All models we’ve tested are in the 1~3B parameter range. The Platonic Representation Hypothesis predicts a platonic convergence increasing with model size, therefore results may differ as we scale up to 70B+. I didn’t have the compute budget to test this.Single Pair for Testing. In this project we only test 1 cross-architecture transfer (Gemma -> Qwen), and 1 within-family transfer (Llama-1B -> Llama-3B). Would be better to test across different pairs and see whether the results generalize.Linear Bridge Deepdive. There needs to be more sophisticated research done in order to understand how the bridges worked under the hoods. As in, what are the recognizable patterns, does it relate to the dimensions of the binary “task” vector, etc?Dataset Dependency. All the probes and tasks were trained and tested on the same text corpus. Would be better if we can see if the learned bridges can actually generalize to different domains.ReferencesHuh et al. (2024). The Platonic Representation Hypothesis. ICML 2024.Gröger, Wen & Brbić (2026). Revisiting the Platonic Representation Hypothesis: An Aristotelian View.Kornblith et al. (2019). Similarity of Neural Network Representations Revisited. ICML 2019.Song et al. (2012). Feature selection via dependence maximization. JMLR.Roger et al. (2025). Activation Space Interventions Transfer Across Large Language Models.Karvonen et al. (2025). Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers.Discuss Read More
Related Posts

Axiological Stopsigns
Published on January 5, 2026 7:30 AM GMTEpistemic Status: I wrote the bones of this…
Reasoning Long Jump: Why we shouldn’t rely on CoT monitoring for interpretability
Published on January 26, 2026 10:10 AM GMTIn Part One, we explore how models sometimes…
How to survive in the storm of uncertainty (and shit)?
Published on October 18, 2025 9:53 AM GMTI've been posting my story here at less…