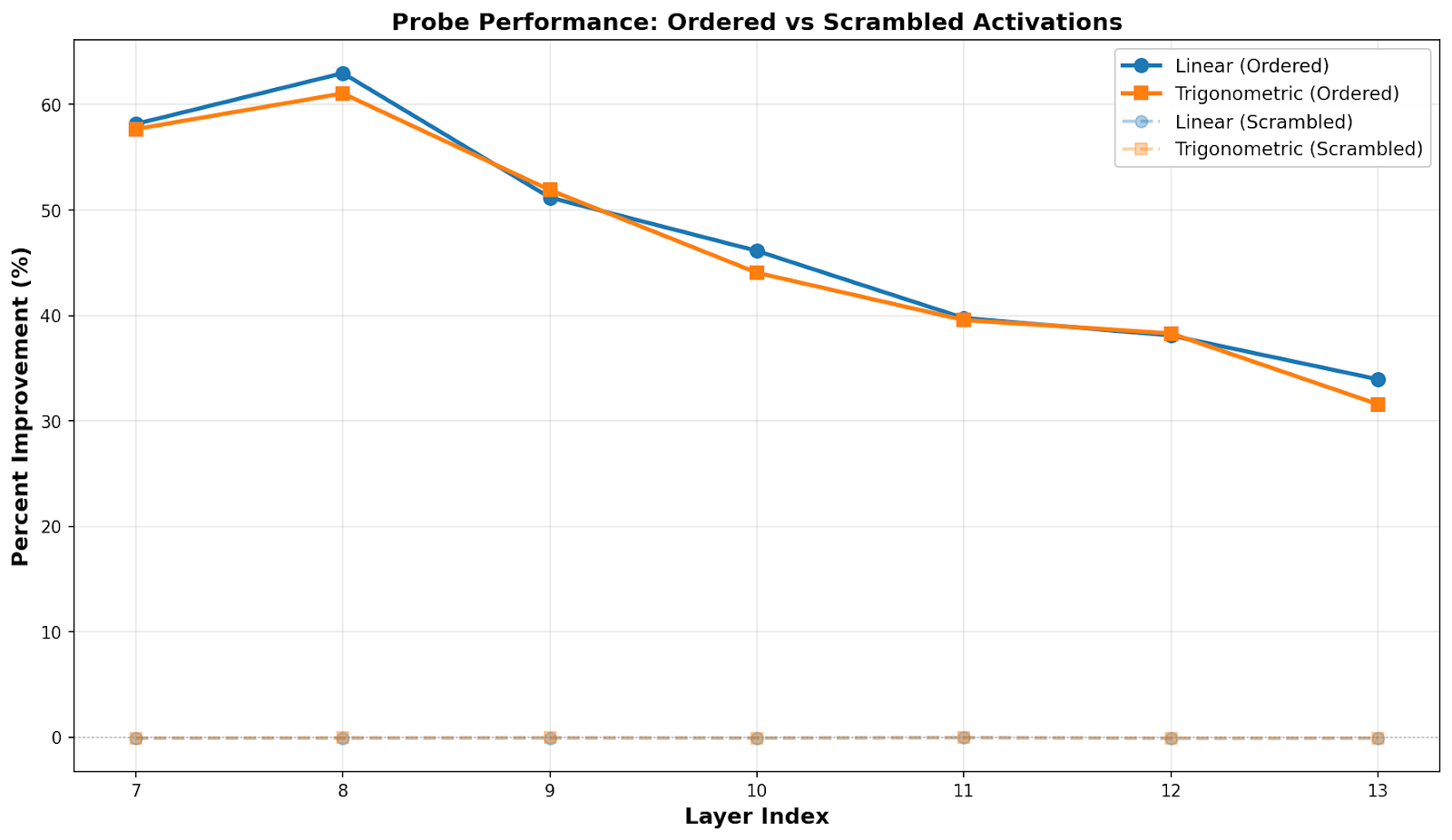
This is adapted from my application for Neel Nanda’s MATS 10.0 stream. It wasn’t accepted, so don’t use this as a good example of an application, but I still think I got some interesting results worth sharing.Executive SummaryI studied the geometry of turn-taking representations in a Llama model. I hypothesized that the model would represent a token’s position in the turn taking structure as a vector that rotates through a plane, given the cyclical nature of a turn-based conversation (the “clock” hypothesis). This is opposed to the traditional view that features are one-dimensionally linear (the “progress bar” or “pendulum” hypotheses). I found evidence supporting both a linear representation of turn-taking and a rotational representation, indicating that turn taking is actually represented helically, or at least that a helical model can approximate the true representation.Key EvidenceLinear and trigonometric probes predicting “phase” in a “round” perform approximately equally well (a “round” is a user turn followed by an assistant turn, and “phase” is a label applied to tokens based on their position in the round, from 0.0 to 0.5 for a user turn and from 0.5 to 1.0 for the assistant turns).At least within assistant turns, there is clear and continuous correlation between true phase and phase predicted by the linear probe, ruling out a “turn-switch” dumbbell shaped geometry.A PCA+Fourier Transform analysis finds pairs of principal components in activation space that form a plane onto which activations can be projected to reveal a (noisy) elliptical pattern (visualized as a color wheel, example below), which would be expected for a rotational geometry. Pairs of principal components were selected by finding components with high phase coherence and near 90 degree phase offsets relative to one another.I ran all experiments on a synthetically generated set of conversations on a diverse range of topics, and validated my results against a control dataset where the order of activations was permuted. The non-scrambled dataset shows a clear signal, while the scrambled dataset does not.ReportIntroductionSteering an LLM assistant’s verbosity is a useful tool to have. Some techniques for doing so already exist, but they can be imprecise and difficult to use in a targeted way. What if we could directly modify an LLM’s representation of how close it is to the end of its turn?LLM internal representations of turn structure have been found in the past. For instance, Nour et al. found linear “start-like” and “end-like” features. We might call this a “progress bar” representation. However, Nour et al. focus on story-telling, while a critical use for LLMs today is as a chatbot assistant. Conversations, as opposed to storytelling, have a cyclical structure: after the user’s turn and the assistant’s turn, we start over again at the user’s turn. Other cyclical concepts, such as days of the week, have been found to sometimes have “rotational” structure in LLMs. In other words, as you move through the cycle, the feature vector rotates in a subspace of activation space. Is it possible that the “true” representation of turn structure in an LLM is rotational? We’ll call this the “clock” hypothesis.SetupTo test these hypotheses, I generated 50 conversations on a diverse range of topics using a small Llama model (Why this model?). The topics were generated by GPT-OSS and given to the Llama model, which was instructed to play the parts of both the assistant and user (see here for details). Each conversation is made up of five rounds (each round being a user turn and an assistant turn). Below is the breakdown of the conversations by token. Note that there are far more assistant tokens than user tokens. This is to be expected since the user is mostly asking relatively short questions and the assistant is providing detailed responses.I then used nnsight to collect Llama’s activations in layers 7-13 for every token across all conversations. The model has 16 layers total, and layers 7-13 were chosen somewhat arbitrarily as a sample of middle-to-late layers, where interesting representations are often found.I also created a second control dataset, where the order of the activations is permuted. The original tokens, and hence the round structure, was left unchanged, but I effectively removed any possible information in the activations about the token’s location in the turn structure, while still keeping the activations in distribution for the model.ExperimentsI assigned each token in all rounds a “phase” from 0.0 to 1.0. The first token of a user’s turn was assigned 0.0, and the last 0.5, with the tokens in between having linearly interpolated phases. Tokens that are part of the assistants turn were similarly assigned phases from 0.5 to 1.0. Each new round of conversation resets the phase back to 0.0. The idea is that the phase represents the token’s position in terms of the turn structure. Note, however, that it’s unlikely the turn position representation rises monotonically throughout a round. For example, it is unlikely that a turn will end mid-sentence, so we might expect the model’s representation of phase to backtrack a bit mid-sentence before “catching up” again at the end (note that I don’t actually find any evidence for this particular mechanism for noise, but it demonstrates the kind of process that could plausible generate it). The experiments I ran, on the other hand, do assume a linear increase in phase. Thus, we should expect to see some amount of noise. See limitations for further discussion of why this way of modeling turn structure is less than ideal.ProbesAs a simple starting point, if the model represents the turn structure as a “progress bar”, we may be able to use a linear probe to find it. Similarly, if the model is representing it as a “clock”, we should be able to use a linear probe predicting sin(2pi*phase) and cos(2pi*phase) (“trigonometric probe”). We’ll also try to have the linear and trigonometric probes predict the phase of the scrambled activations. Below is a plot showing the percent improvement (R^2 times 100) of each probe compared to a simple mean baseline on a test set of 20% of the tokens.The first thing to note is that the probes trained on the scrambled data couldn’t do any better than the baseline, which is to be expected. The probes trained on the unscrambled data, on the other hand, do show an improvement over the baseline, indicating that there is some signal for them to pick up on. Maybe more interestingly though, is the fact that both kinds of probes have roughly the same improvement over the baseline. See discussion for what that might indicate.Linear Probe PredictionsPlotting the true vs predicted phase of various tokens (below) shows a clear and smooth correlation between the two, especially for assistant-turn tokens. The linear probe seems to have a harder time placing where exactly user tokens are in the user’s turn, but largely places them as being somewhere in the user’s turn. This is likely an artifact of there being so many fewer user-turn tokens. Also interesting to note is that, visually at least, the predictions seem to follow a vaguely sinusoidal pattern. Some possibilities include that this is simply an artifact of the experiment procedure, that it isn’t statistically significant, or that is a real signal, indicating that the true structure is sinusoidal. Further study would be needed to accurately distinguish between these possibilities.Scrambled (Control)UnscrambledPCA and Fourier AnalysisFor this experiment, I started by running a PCA on the activations. I did a separate PCA for each of the layers (7-13), but each layer’s PCA included the activations from all tokens across all 50 conversations. If there is a strong rotational structure to be found, we expect to see it by picking two principal components, using them as the basis for a plane, projecting all of the token’s activations onto that plane, and plotting the result. If we give the points a hue according to their phase, we should see a sort of (noisy) “color wheel” appear if the two components form a plane close to the plane that the “clock” vector is rotating in.In the plot above, we see our color wheel appear for layer 12’s PC4 and PC6. Note in the plot above that cyans, blues, and purples dominate. That is because those represent the assistant’s turns, which dominate the dataset. Also note that this analysis doesn’t “know” anything about phase. Phase is only used for the validation plots, which makes it all the more striking when we see positive results.Top PCAWhy PC4 and PC6 though, and why layer 12? Maybe we can do something simpler. If the turn structure is very strongly represented in the activations, we may see it come through even in PC0 and PC1. Empirically, however, this doesn’t turn out to be the case. Below is the scatter plot for the activations at layer 12 projected onto PC0 and PC1. While there is some clear structure going on, it doesn’t look like the nice color wheel from PC4 and PC6.High Phase CoherenceSo how can we pick better principal components? One thing we should expect from the “right” principal components is that there should be a strong periodic structure to them. Across a round, we should see a full sinusoid wave in the values of the PC. Numerically, if we take the Fourier Transform of the principal components, we should see a strong spike at a frequency of one. To test this, I resampled the conversations so the samples were spread according to their phase in a round (user tokens get spread more than assistant tokens), ran a separate Fourier Transform on each round, then averaged the complex results to get the phase coherence of each PC-frequency pair across all rounds (we need phase coherence here instead of just average magnitude of frequencies, since we would expect a true signal to have the same phase offset across rounds). Doing so, we get a heatmap like the one below.The top two principal components in terms of their phase coherences are PC6 and PC4 (closely followed by PC2), the ones we saw from the color-wheel example above. However, this doesn’t work for all layers. For instance, if we try the same strategy with layer 13 and pick the top two principal components in terms of phase coherence and plot them, we get the plot below. Again, we see some interesting structure, but not a color wheel.Orthogonal High Phase CoherenceThe missing piece is that high phase coherence alone isn’t enough. We need two PCs that have high phase coherence and that are 90 degrees out of phase with one another. If the two are in phase, the most we can hope for is motion in a line, not an ellipse. To measure this, I define angle dissimilarity to be where is the absolute difference between the angles of the vectors in the plane formed by two principal components. Then, to choose the “best” two principal components, we define their coherence-weighted-angle-dissimilarity to be the product of their phase coherences times the square of their angle dissimilarity: . Calculating this metric for all of the PCs for layer 13, we get the values in the heatmap below.It turns out that while PC2 and PC6 from layer 13 have the highest phase coherences overall in that layer, they are highly aligned, so their angle-weighted-coherence is very small. It is actually PC5 and PC6 that make up the best pair. Below is a plot with those two PCs. We don’t see the color wheel with the same clarity that we did on layer 12, but we do see reds to the right, cyans and greens to the bottom left, and blues concentrated towards the top. As for layer 12, it turns out that (by coincidence as far as I know) it was the only layer whose top two PCs in terms of phase coherence also happened to have the highest coherence-weighted-angle-dissimilarity. In fact, they have the highest coherence-weighted-angle-dissimilarity out of any two PCs in any layer (at approximately 35,000, compared to layer 13’s maximum of about 30,000). This may explain why the color wheel is so clear on layer 12.Baseline ComparisonBut are we just seeing what we want to see? To test that, I ran the same PCA and Fourier Analysis tests on the scrambled dataset. Below is shown an angle-weighted-coherence heatmap and scatterplot of the best two PCs for layer 12 for the scrambled dataset. Note the drastic change in scale from the heatmap above, and the fact that the scatterplot has become pure noise. In other words, there was no signal to be found in the scrambled dataset, even when cherry-picking the best results for the scrambled dataset.Scrambled (Control)UnscrambledDiscussionWe can confidently conclude that the Llama model under study has some internal representation that is correlated turn structure. However, the exact geometry of that representation remains somewhat unclear. Tests for both “progress bar” and “clock” geometry come up positive, and in roughly equal measure. Some possible interpretations:Both geometries are represented by Llama (i.e. the representation is a helix). If this is the case, it could be because both kinds of representations are useful for different purposes.Neither is truly present, but instead there is some third geometry that is approximated about as well by a linear model or rotational model. Intuitively, this feels unlikely to me (how likely is it that tests for linear and rotational models would find roughly the same signal if this were the case?). However, I can’t definitively rule this out without further experiments.One concrete possibility here is that the geometry is a “switch” geometry. In other words, Llama doesn’t keep track of where it is in a turn, only whose turn it is. However, I believe the smooth correlation in the upper right quadrant of the plot of the linear probe predictions rules this out.Another is a sine wave geometry, i.e. a “pendulum” or “spring”. There is not a full two dimensional rotation, but there is a sinusoidal structure (as opposed to the “sawtooth” wave predicted by the “progress bar” hypothesis). This would fit well with the linear probe prediction graph, but doesn’t explain the color wheel plots on its own, and it is unclear to me why both the rotational and linear probes should have roughly equal R^2 in that case.Out of all the proposed hypotheses, the evidence presented here most strongly points to a helical model turn structure, but I can’t definitively say that there isn’t some better model. I can say that there is some representation correlated with turn structure, and that a helical model at least approximates that representation. To establish this more firmly, a causal study should be run. Can you speed up a turn by adding the “end of turn” representation to the activations? (yes) How does that compare to rotating the activations around towards “end of turn”?Limitations and Future WorkPhase AssignmentsI somewhat arbitrarily assigned phases 0.0-0.5 to user tokens and 0.5-1.0 to assistant tokens. This would make the most sense if the model divided the hypothetical subspaces equally between the two kinds of representations. However, I think this is actually unlikely to be the case. Llama is instruction tuned with loss masked on user tokens, and there are usually fewer user tokens in any case, so it is reasonable to imagine that the model dedicates more space to the representation of the assistant’s turns. In other words, maybe only 12:00 to 1:00 is the user’s turn on the clock, or 0-10% on the progress bar. In practical terms, this meant that the probes had far fewer user-turn datapoints and the visualizations were dominated by assistant tokens. A possible alternative set of experiments would have the phase assignments linearly increase across the whole round, instead of separating it into user and assistant turns.One Small ModelI used one relatively small open source model for this study. I did this to get fast iteration times, and I believe it is justified since even a model of this size is more than capable of holding a turn based conversation. However, I have no real evidence beyond intuition that these results would extend to other models or differently sized models.Synthetic ConversationsIn order to get activations for the study study, I had Llama play the role of both the assistant and the user. This might be an unnatural thing to do. Ideally, I would have a dataset of real conversations that people have had with this model, but considering that I didn’t, this seemed the next best thing. It is possible that the model-generated user-turns are out of distribution for what a real user might say, which could throw the model off and invalidate the results. An alternative could be to use a dataset such as WildChat. However, that would have the opposite issue: the assistant turns would be generated by a different model, potentially throwing us even further off distribution.No Causal ProbingAs no causal study was performed, these experiments only demonstrate that there are activations correlated with round phase in the Llama model. In other words, the information is present, but there is no guarantee that Llama actually uses that information.Conflation With Positional EmbeddingsThanks to Jaden Lorenc for this insightThere is a strong possibility that the Fourier Analysis found frequencies that resonate with the rotational positional embedding used in Llama. While round lengths varied significantly (see Setup), it’s possible that the variance is low enough that the frequency analysis is picking up on that (noisy) signal instead of anything natively measuring turn length. Further work would need to be done to disentangle these two signals.AppendixAngles on TokensAs a qualitative sanity check, I produced a visualization on various conversations using PCA/Fourier Transform analysis to predict the phase of tokens. The color wheel is shifted so that the first “user” token is pure red. Predictions were generated by taking the angle of a token’s activation vector projected onto the plane defined by the “best” pair of principal components (those with the highest coherence-weighted-angle-dissimilarity). You can see a sample here. Note the tendency of the colors to shift towards yellow and red towards the end of the assistant’s turn, indicating that it is “wrapping up”. These visualizations were not included in the main report for the sake of space and because they are extremely qualitative.Dataset Generation ProcedureTo generate the 50 conversations, Llama was given the following system prompt.You are simulating a detailed, multi-turn conversation between a User and an Assistant about: “{topic}”.- The User is curious, skeptical, and asks follow-up questions.- The Assistant is helpful, knowledgeable, and concise.- You will generate BOTH sides.- Unless explicitly told otherwise, act as the Assistant.Then, before a user’s turn is simulated, an extra system prompt is appended to the end of the conversation. For the user’s first turn, the system prompt is:Now, act as the User. Write an initial question about ‘{topic}’ to start the conversation. The User is curious and wants to learn. Do not prefix with ‘User:’. Just write the question.For subsequent user turns, the extra system prompt is:Now, act as the User. Write a skeptical follow-up question based on the Assistant’s last point. Do not prefix with ‘User:’. Just write the question.After Llama generates a user turn, the additional system prompt is removed from the conversation and a normal assistant turn is generated. Unfortunately, the Llama model had a tendency to try to prefix assistant turns with “User:”. When this happened, I simply retried the conversation generation.Here is a full list of conversation topics:The cultural impact of jazz music in the 20th century.The history and symbolism of the lotus flower in Eastern traditions.The evolution of folk storytelling across indigenous communities.The role of storytelling in preserving oral histories.The influence of Shakespeare on modern drama.The significance of the Taj Mahal as a symbol of love.The philosophical questions surrounding free will.The impact of the printing press on European society.The ecological importance of coral reefs and their decline.The effect of climate change on polar bear habitats.The psychological benefits of regular meditation practice.The history of the Silk Road and its cultural exchanges.The role of women in the Renaissance art world.The significance of the moon landing for global politics.The evolution of religious rituals across cultures.The importance of biodiversity in tropical rainforests.The role of public art in urban revitalization.The influence of ancient Greek philosophy on modern ethics.The history of the Olympic Games and their modern revival.The cultural importance of traditional Japanese tea ceremony.The impact of the Black Panther Party on civil rights.The significance of the Great Barrier Reef’s bleaching events.The effect of music therapy on patients with dementia.The history of the feminist movement in the 19th century.The role of folklore in shaping national identity.The evolution of language families across continents.The influence of African griots on contemporary music.The significance of the Hiroshima Peace Memorial.The impact of urban green spaces on mental health.The history of the printing of the Gutenberg Bible.The role of indigenous knowledge in sustainable agriculture.The philosophical debate over determinism versus indeterminism.The cultural practices surrounding the harvest festival in Nepal.The effect of storytelling on child development.The history of the transatlantic slave trade.The importance of conservation efforts for the Sumatran tiger.The role of women in early computing history.The significance of the fall of the Berlin Wall.The evolution of culinary traditions in Mediterranean cuisine.The impact of renewable energy adoption on rural communities.The psychological impact of social isolation during pandemics.The history of the Magna Carta and its legacy.The role of the arts in post-war reconstruction.The significance of the Voyager probes’ golden records.The cultural importance of storytelling rituals in Papua New Guinea.The effect of climate variability on ancient Maya civilization.The role of traditional healers in modern healthcare systems.The history of the civil rights march on Washington.The philosophical implications of artificial consciousness.The impact of global migration on cultural landscapes.Code and All FiguresThe code and full data used in this study can be found here.Discuss Read More
Helical Representations of Turn Structure in an LLM
This is adapted from my application for Neel Nanda’s MATS 10.0 stream. It wasn’t accepted, so don’t use this as a good example of an application, but I still think I got some interesting results worth sharing.Executive SummaryI studied the geometry of turn-taking representations in a Llama model. I hypothesized that the model would represent a token’s position in the turn taking structure as a vector that rotates through a plane, given the cyclical nature of a turn-based conversation (the “clock” hypothesis). This is opposed to the traditional view that features are one-dimensionally linear (the “progress bar” or “pendulum” hypotheses). I found evidence supporting both a linear representation of turn-taking and a rotational representation, indicating that turn taking is actually represented helically, or at least that a helical model can approximate the true representation.Key EvidenceLinear and trigonometric probes predicting “phase” in a “round” perform approximately equally well (a “round” is a user turn followed by an assistant turn, and “phase” is a label applied to tokens based on their position in the round, from 0.0 to 0.5 for a user turn and from 0.5 to 1.0 for the assistant turns).At least within assistant turns, there is clear and continuous correlation between true phase and phase predicted by the linear probe, ruling out a “turn-switch” dumbbell shaped geometry.A PCA+Fourier Transform analysis finds pairs of principal components in activation space that form a plane onto which activations can be projected to reveal a (noisy) elliptical pattern (visualized as a color wheel, example below), which would be expected for a rotational geometry. Pairs of principal components were selected by finding components with high phase coherence and near 90 degree phase offsets relative to one another.I ran all experiments on a synthetically generated set of conversations on a diverse range of topics, and validated my results against a control dataset where the order of activations was permuted. The non-scrambled dataset shows a clear signal, while the scrambled dataset does not.ReportIntroductionSteering an LLM assistant’s verbosity is a useful tool to have. Some techniques for doing so already exist, but they can be imprecise and difficult to use in a targeted way. What if we could directly modify an LLM’s representation of how close it is to the end of its turn?LLM internal representations of turn structure have been found in the past. For instance, Nour et al. found linear “start-like” and “end-like” features. We might call this a “progress bar” representation. However, Nour et al. focus on story-telling, while a critical use for LLMs today is as a chatbot assistant. Conversations, as opposed to storytelling, have a cyclical structure: after the user’s turn and the assistant’s turn, we start over again at the user’s turn. Other cyclical concepts, such as days of the week, have been found to sometimes have “rotational” structure in LLMs. In other words, as you move through the cycle, the feature vector rotates in a subspace of activation space. Is it possible that the “true” representation of turn structure in an LLM is rotational? We’ll call this the “clock” hypothesis.SetupTo test these hypotheses, I generated 50 conversations on a diverse range of topics using a small Llama model (Why this model?). The topics were generated by GPT-OSS and given to the Llama model, which was instructed to play the parts of both the assistant and user (see here for details). Each conversation is made up of five rounds (each round being a user turn and an assistant turn). Below is the breakdown of the conversations by token. Note that there are far more assistant tokens than user tokens. This is to be expected since the user is mostly asking relatively short questions and the assistant is providing detailed responses.I then used nnsight to collect Llama’s activations in layers 7-13 for every token across all conversations. The model has 16 layers total, and layers 7-13 were chosen somewhat arbitrarily as a sample of middle-to-late layers, where interesting representations are often found.I also created a second control dataset, where the order of the activations is permuted. The original tokens, and hence the round structure, was left unchanged, but I effectively removed any possible information in the activations about the token’s location in the turn structure, while still keeping the activations in distribution for the model.ExperimentsI assigned each token in all rounds a “phase” from 0.0 to 1.0. The first token of a user’s turn was assigned 0.0, and the last 0.5, with the tokens in between having linearly interpolated phases. Tokens that are part of the assistants turn were similarly assigned phases from 0.5 to 1.0. Each new round of conversation resets the phase back to 0.0. The idea is that the phase represents the token’s position in terms of the turn structure. Note, however, that it’s unlikely the turn position representation rises monotonically throughout a round. For example, it is unlikely that a turn will end mid-sentence, so we might expect the model’s representation of phase to backtrack a bit mid-sentence before “catching up” again at the end (note that I don’t actually find any evidence for this particular mechanism for noise, but it demonstrates the kind of process that could plausible generate it). The experiments I ran, on the other hand, do assume a linear increase in phase. Thus, we should expect to see some amount of noise. See limitations for further discussion of why this way of modeling turn structure is less than ideal.ProbesAs a simple starting point, if the model represents the turn structure as a “progress bar”, we may be able to use a linear probe to find it. Similarly, if the model is representing it as a “clock”, we should be able to use a linear probe predicting sin(2pi*phase) and cos(2pi*phase) (“trigonometric probe”). We’ll also try to have the linear and trigonometric probes predict the phase of the scrambled activations. Below is a plot showing the percent improvement (R^2 times 100) of each probe compared to a simple mean baseline on a test set of 20% of the tokens.The first thing to note is that the probes trained on the scrambled data couldn’t do any better than the baseline, which is to be expected. The probes trained on the unscrambled data, on the other hand, do show an improvement over the baseline, indicating that there is some signal for them to pick up on. Maybe more interestingly though, is the fact that both kinds of probes have roughly the same improvement over the baseline. See discussion for what that might indicate.Linear Probe PredictionsPlotting the true vs predicted phase of various tokens (below) shows a clear and smooth correlation between the two, especially for assistant-turn tokens. The linear probe seems to have a harder time placing where exactly user tokens are in the user’s turn, but largely places them as being somewhere in the user’s turn. This is likely an artifact of there being so many fewer user-turn tokens. Also interesting to note is that, visually at least, the predictions seem to follow a vaguely sinusoidal pattern. Some possibilities include that this is simply an artifact of the experiment procedure, that it isn’t statistically significant, or that is a real signal, indicating that the true structure is sinusoidal. Further study would be needed to accurately distinguish between these possibilities.Scrambled (Control)UnscrambledPCA and Fourier AnalysisFor this experiment, I started by running a PCA on the activations. I did a separate PCA for each of the layers (7-13), but each layer’s PCA included the activations from all tokens across all 50 conversations. If there is a strong rotational structure to be found, we expect to see it by picking two principal components, using them as the basis for a plane, projecting all of the token’s activations onto that plane, and plotting the result. If we give the points a hue according to their phase, we should see a sort of (noisy) “color wheel” appear if the two components form a plane close to the plane that the “clock” vector is rotating in.In the plot above, we see our color wheel appear for layer 12’s PC4 and PC6. Note in the plot above that cyans, blues, and purples dominate. That is because those represent the assistant’s turns, which dominate the dataset. Also note that this analysis doesn’t “know” anything about phase. Phase is only used for the validation plots, which makes it all the more striking when we see positive results.Top PCAWhy PC4 and PC6 though, and why layer 12? Maybe we can do something simpler. If the turn structure is very strongly represented in the activations, we may see it come through even in PC0 and PC1. Empirically, however, this doesn’t turn out to be the case. Below is the scatter plot for the activations at layer 12 projected onto PC0 and PC1. While there is some clear structure going on, it doesn’t look like the nice color wheel from PC4 and PC6.High Phase CoherenceSo how can we pick better principal components? One thing we should expect from the “right” principal components is that there should be a strong periodic structure to them. Across a round, we should see a full sinusoid wave in the values of the PC. Numerically, if we take the Fourier Transform of the principal components, we should see a strong spike at a frequency of one. To test this, I resampled the conversations so the samples were spread according to their phase in a round (user tokens get spread more than assistant tokens), ran a separate Fourier Transform on each round, then averaged the complex results to get the phase coherence of each PC-frequency pair across all rounds (we need phase coherence here instead of just average magnitude of frequencies, since we would expect a true signal to have the same phase offset across rounds). Doing so, we get a heatmap like the one below.The top two principal components in terms of their phase coherences are PC6 and PC4 (closely followed by PC2), the ones we saw from the color-wheel example above. However, this doesn’t work for all layers. For instance, if we try the same strategy with layer 13 and pick the top two principal components in terms of phase coherence and plot them, we get the plot below. Again, we see some interesting structure, but not a color wheel.Orthogonal High Phase CoherenceThe missing piece is that high phase coherence alone isn’t enough. We need two PCs that have high phase coherence and that are 90 degrees out of phase with one another. If the two are in phase, the most we can hope for is motion in a line, not an ellipse. To measure this, I define angle dissimilarity to be where is the absolute difference between the angles of the vectors in the plane formed by two principal components. Then, to choose the “best” two principal components, we define their coherence-weighted-angle-dissimilarity to be the product of their phase coherences times the square of their angle dissimilarity: . Calculating this metric for all of the PCs for layer 13, we get the values in the heatmap below.It turns out that while PC2 and PC6 from layer 13 have the highest phase coherences overall in that layer, they are highly aligned, so their angle-weighted-coherence is very small. It is actually PC5 and PC6 that make up the best pair. Below is a plot with those two PCs. We don’t see the color wheel with the same clarity that we did on layer 12, but we do see reds to the right, cyans and greens to the bottom left, and blues concentrated towards the top. As for layer 12, it turns out that (by coincidence as far as I know) it was the only layer whose top two PCs in terms of phase coherence also happened to have the highest coherence-weighted-angle-dissimilarity. In fact, they have the highest coherence-weighted-angle-dissimilarity out of any two PCs in any layer (at approximately 35,000, compared to layer 13’s maximum of about 30,000). This may explain why the color wheel is so clear on layer 12.Baseline ComparisonBut are we just seeing what we want to see? To test that, I ran the same PCA and Fourier Analysis tests on the scrambled dataset. Below is shown an angle-weighted-coherence heatmap and scatterplot of the best two PCs for layer 12 for the scrambled dataset. Note the drastic change in scale from the heatmap above, and the fact that the scatterplot has become pure noise. In other words, there was no signal to be found in the scrambled dataset, even when cherry-picking the best results for the scrambled dataset.Scrambled (Control)UnscrambledDiscussionWe can confidently conclude that the Llama model under study has some internal representation that is correlated turn structure. However, the exact geometry of that representation remains somewhat unclear. Tests for both “progress bar” and “clock” geometry come up positive, and in roughly equal measure. Some possible interpretations:Both geometries are represented by Llama (i.e. the representation is a helix). If this is the case, it could be because both kinds of representations are useful for different purposes.Neither is truly present, but instead there is some third geometry that is approximated about as well by a linear model or rotational model. Intuitively, this feels unlikely to me (how likely is it that tests for linear and rotational models would find roughly the same signal if this were the case?). However, I can’t definitively rule this out without further experiments.One concrete possibility here is that the geometry is a “switch” geometry. In other words, Llama doesn’t keep track of where it is in a turn, only whose turn it is. However, I believe the smooth correlation in the upper right quadrant of the plot of the linear probe predictions rules this out.Another is a sine wave geometry, i.e. a “pendulum” or “spring”. There is not a full two dimensional rotation, but there is a sinusoidal structure (as opposed to the “sawtooth” wave predicted by the “progress bar” hypothesis). This would fit well with the linear probe prediction graph, but doesn’t explain the color wheel plots on its own, and it is unclear to me why both the rotational and linear probes should have roughly equal R^2 in that case.Out of all the proposed hypotheses, the evidence presented here most strongly points to a helical model turn structure, but I can’t definitively say that there isn’t some better model. I can say that there is some representation correlated with turn structure, and that a helical model at least approximates that representation. To establish this more firmly, a causal study should be run. Can you speed up a turn by adding the “end of turn” representation to the activations? (yes) How does that compare to rotating the activations around towards “end of turn”?Limitations and Future WorkPhase AssignmentsI somewhat arbitrarily assigned phases 0.0-0.5 to user tokens and 0.5-1.0 to assistant tokens. This would make the most sense if the model divided the hypothetical subspaces equally between the two kinds of representations. However, I think this is actually unlikely to be the case. Llama is instruction tuned with loss masked on user tokens, and there are usually fewer user tokens in any case, so it is reasonable to imagine that the model dedicates more space to the representation of the assistant’s turns. In other words, maybe only 12:00 to 1:00 is the user’s turn on the clock, or 0-10% on the progress bar. In practical terms, this meant that the probes had far fewer user-turn datapoints and the visualizations were dominated by assistant tokens. A possible alternative set of experiments would have the phase assignments linearly increase across the whole round, instead of separating it into user and assistant turns.One Small ModelI used one relatively small open source model for this study. I did this to get fast iteration times, and I believe it is justified since even a model of this size is more than capable of holding a turn based conversation. However, I have no real evidence beyond intuition that these results would extend to other models or differently sized models.Synthetic ConversationsIn order to get activations for the study study, I had Llama play the role of both the assistant and the user. This might be an unnatural thing to do. Ideally, I would have a dataset of real conversations that people have had with this model, but considering that I didn’t, this seemed the next best thing. It is possible that the model-generated user-turns are out of distribution for what a real user might say, which could throw the model off and invalidate the results. An alternative could be to use a dataset such as WildChat. However, that would have the opposite issue: the assistant turns would be generated by a different model, potentially throwing us even further off distribution.No Causal ProbingAs no causal study was performed, these experiments only demonstrate that there are activations correlated with round phase in the Llama model. In other words, the information is present, but there is no guarantee that Llama actually uses that information.Conflation With Positional EmbeddingsThanks to Jaden Lorenc for this insightThere is a strong possibility that the Fourier Analysis found frequencies that resonate with the rotational positional embedding used in Llama. While round lengths varied significantly (see Setup), it’s possible that the variance is low enough that the frequency analysis is picking up on that (noisy) signal instead of anything natively measuring turn length. Further work would need to be done to disentangle these two signals.AppendixAngles on TokensAs a qualitative sanity check, I produced a visualization on various conversations using PCA/Fourier Transform analysis to predict the phase of tokens. The color wheel is shifted so that the first “user” token is pure red. Predictions were generated by taking the angle of a token’s activation vector projected onto the plane defined by the “best” pair of principal components (those with the highest coherence-weighted-angle-dissimilarity). You can see a sample here. Note the tendency of the colors to shift towards yellow and red towards the end of the assistant’s turn, indicating that it is “wrapping up”. These visualizations were not included in the main report for the sake of space and because they are extremely qualitative.Dataset Generation ProcedureTo generate the 50 conversations, Llama was given the following system prompt.You are simulating a detailed, multi-turn conversation between a User and an Assistant about: “{topic}”.- The User is curious, skeptical, and asks follow-up questions.- The Assistant is helpful, knowledgeable, and concise.- You will generate BOTH sides.- Unless explicitly told otherwise, act as the Assistant.Then, before a user’s turn is simulated, an extra system prompt is appended to the end of the conversation. For the user’s first turn, the system prompt is:Now, act as the User. Write an initial question about ‘{topic}’ to start the conversation. The User is curious and wants to learn. Do not prefix with ‘User:’. Just write the question.For subsequent user turns, the extra system prompt is:Now, act as the User. Write a skeptical follow-up question based on the Assistant’s last point. Do not prefix with ‘User:’. Just write the question.After Llama generates a user turn, the additional system prompt is removed from the conversation and a normal assistant turn is generated. Unfortunately, the Llama model had a tendency to try to prefix assistant turns with “User:”. When this happened, I simply retried the conversation generation.Here is a full list of conversation topics:The cultural impact of jazz music in the 20th century.The history and symbolism of the lotus flower in Eastern traditions.The evolution of folk storytelling across indigenous communities.The role of storytelling in preserving oral histories.The influence of Shakespeare on modern drama.The significance of the Taj Mahal as a symbol of love.The philosophical questions surrounding free will.The impact of the printing press on European society.The ecological importance of coral reefs and their decline.The effect of climate change on polar bear habitats.The psychological benefits of regular meditation practice.The history of the Silk Road and its cultural exchanges.The role of women in the Renaissance art world.The significance of the moon landing for global politics.The evolution of religious rituals across cultures.The importance of biodiversity in tropical rainforests.The role of public art in urban revitalization.The influence of ancient Greek philosophy on modern ethics.The history of the Olympic Games and their modern revival.The cultural importance of traditional Japanese tea ceremony.The impact of the Black Panther Party on civil rights.The significance of the Great Barrier Reef’s bleaching events.The effect of music therapy on patients with dementia.The history of the feminist movement in the 19th century.The role of folklore in shaping national identity.The evolution of language families across continents.The influence of African griots on contemporary music.The significance of the Hiroshima Peace Memorial.The impact of urban green spaces on mental health.The history of the printing of the Gutenberg Bible.The role of indigenous knowledge in sustainable agriculture.The philosophical debate over determinism versus indeterminism.The cultural practices surrounding the harvest festival in Nepal.The effect of storytelling on child development.The history of the transatlantic slave trade.The importance of conservation efforts for the Sumatran tiger.The role of women in early computing history.The significance of the fall of the Berlin Wall.The evolution of culinary traditions in Mediterranean cuisine.The impact of renewable energy adoption on rural communities.The psychological impact of social isolation during pandemics.The history of the Magna Carta and its legacy.The role of the arts in post-war reconstruction.The significance of the Voyager probes’ golden records.The cultural importance of storytelling rituals in Papua New Guinea.The effect of climate variability on ancient Maya civilization.The role of traditional healers in modern healthcare systems.The history of the civil rights march on Washington.The philosophical implications of artificial consciousness.The impact of global migration on cultural landscapes.Code and All FiguresThe code and full data used in this study can be found here.Discuss Read More
Related Posts

I Had Claude Read Every AI Safety Paper Since 2020, Here’s the DB
Click here if you just want to see the Database I made of all[1] AI safety…
21st Century Civilization curriculum
Published on October 21, 2025 7:43 AM GMTI’ve just released a curriculum on foundational questions…
Robert Sapolsky Is Simply Not Talking About Compatibilism
Published on February 21, 2026 1:27 AM GMTImagine someone wrote a 500-page book called Taking…