
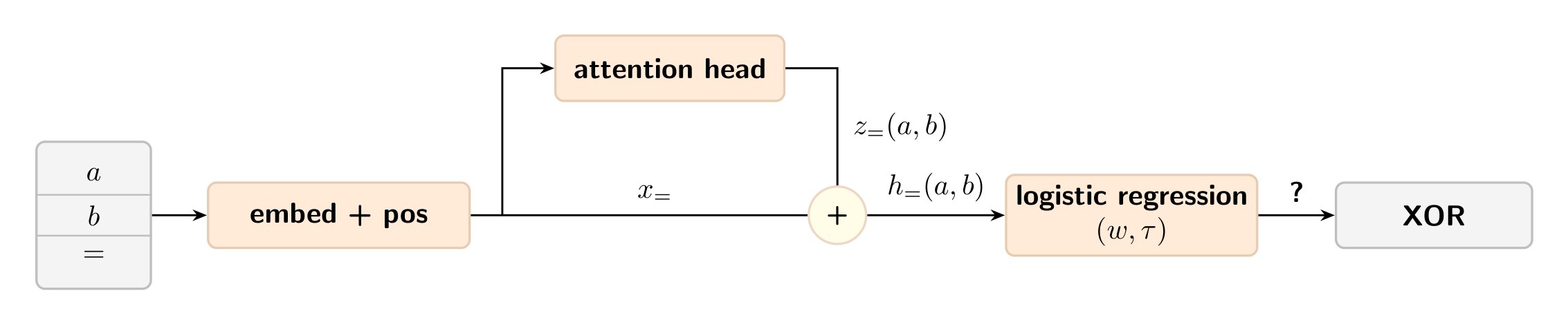
You need at least two attention heads to do XOR, and we will find that it is a surprisingly crisp result which uses only high-school algebra.IntroductionComputing XOR using an attention head. Two input bits and are embedded, processed by an attention head with a skip connection, and read out by a logistic regression classifier. Can the internal activations after the skip connection be used to predict XOR?A single attention head can already do Boolean operations like OR and AND on two input bits, but it cannot do XOR[1]. We will show this using the setup outlined in the above figure: by checking if there exists a logistic regression probe on the internal activations of the query token = to predict[2] . Since the skip connection is constant across all , it can be absorbed into the threshold , so the probe logit depends only on the attention update : If the probe correctly classifies XOR, then it must satisfyMore explicitly, the above equation can be written as: The key fact is that in the single-head setting, for every choice of probe , there exist positive numbers such that But this is impossible under the inequalities above: since each is positive, we would have contradicting the equality. So a single attention head cannot linearly separate XOR.However, two heads are enough. Conceptually, one head detects 0 and the other detects 1. On the mixed inputs 01 and 10, both heads contribute; on 00 and 11, only one of them does. A linear readout can then separate the mixed cases from the same-bit ones.This means you need at least two attention heads to do XOR.[3]SetupWe work with sequences of length 3 over the vocabulary . On input , the model sees the sequence .Self Attention 101Each token has a token embedding , and each position has a positional embedding . The embedded sequence isA single attention head is parameterized by the query, key and value matrices denoted as respectively. The = token attends to all three positions via softmax attention, resulting in the residual stream :where the is attention weight from the key to the = token given as:The = token’s residual stream after the attention head has two parts: the skip connection (its original embedding) and the attention update (the new information it gathered by attending to and ): Since doesn’t depend on the input bits at all, any probe can fold it into its threshold . So the only thing that matters for classification is the attention update . Let denote the value vector at position . The attention update is then a convex combination of these value vectors, weighted by the attention probabilities : The attention probabilities are the softmax of the raw attention logits , which measure how strongly the = token’s query matches each key: resulting in the following attention weights: So we can equivalently write the attention update directly in terms of the ‘s: We now ask: can a hyperplane separate the four attention outputs into the XOR classes? One attention head can do OR and AND[4]It is worth noticing that XOR is the first interesting example here since a single head can already do OR and AND.Here is a simple way to see it. Take a head that attends to 1 tokens and writes a positive value when it reads one.[5] Its output increases with the number of ones, so it produces a score that is monotone in : Now thresholding does the rest:threshold below the medium value gives , i.e. OR;threshold between medium and high gives , i.e. AND.So one head can do monotone threshold functions of just fine. XOR is different because it is not monotone: it fires at but not at or . No single threshold can pick out the middle value from both sides.One attention head cannot do XORHere we are going to work towards a short proof why a single attention head cannot do XOR. The key identitiesIn the setup section, we saw that the attention update takes the formwhere and . Note that , since it will turn out useful later.The key structural fact is that and each split into an -only term, a -only term, and a constant: Because of this, summing over the main diagonal versus the off-diagonal yields identical totals — in both cases you collect exactly one copy each of the and contributions, and one copy each of the and contributions. This gives the key identities: Proof by contradictionSuppose there exists a probe that correctly classifies XOR. This means:so the probe scores must satisfy the XOR sign pattern: Let’s define the denominator-weighted probe score :Since , the XOR sign pattern on the probe scores carries over to :Because is linear in and , the key identities pass straight through to :But the XOR sign pattern forces and , which contradicts the equality above. Conclusion. A single attention head with a linear readout cannot compute XOR.Two heads can do XORNow we switch from one head to two parallel heads. For the existence proof, it is enough to write the residual update as the sum of the two head outputs:whereThe idea is simple:Head 0 softly detects token 0 and writes in one direction;Head 1 softly detects token 1 and writes in an orthogonal direction.Then the mixed inputs 01 and 10 are exactly the cases where both heads contribute.An explicit constructionLet’s work in , with no positional embeddings, and choose the token embeddings as follows:We choose the query, key, value and output matrices for each head as shown below, along with the resulting attention scores and weights from the = query position. The construction is symmetric by design: Head 0 attends preferentially to token 0 and writes in the directionHead 1 attends preferentially to token 1 and writes in the directionEach entry[6] is the triplet of softmax attention weights that the = query assigns to positions respectively, for that head and input. The weights are non-negative and sum to 1. We can now compute the attention update from each head across all four inputs. The same-bit inputs and each activate only one head, while the mixed inputs and activate both heads equally. The mixed inputs therefore have a strictly larger total activation, which a linear readout can exploit.Choosing , the probe score takes only two distinct values: The mixed inputs score strictly higher, so any threshold together with correctly classifies XOR.Conclusion. Two attention heads are sufficient to compute XOR with a linear readout.TakeawayThe single-head impossibility comes down to a structural constraint. Once you weight the probe score by the attention denominator , the result always decomposes as , an additive table with no interaction between and . Since , and the probe score share the same sign, so this additive structure is the true obstruction. XOR requires the checkerboard sign pattern, i.e. firing on the off-diagonal, not on the diagonal, which no additive table can realize.Two heads fix this by providing two independent soft detectors. The mixed inputs and are the only cases where both detectors fire at once, creating a gap in the probe scores that a linear readout can exploit.In a single-layer, attention-only model with a linear readout from the query position, we saw that1 head is not enough for any choice of dimension, embeddings, positional embeddings, or linear readout.2 heads are enough, via the explicit construction above.Together, these establish that two attention heads are necessary and sufficient to compute XOR with a logistic regression probe.^XOR is denoted by in equations. ^This is used to classify just four points. 00 and 11 map to 0 whereas 01 and 10 map to 1. ^Throughout this post, the model is attention-only: there are no MLPs, layer norms, or bias terms. Adding an MLP after the attention layer could solve XOR with a single head, since the MLP can implement the needed nonlinearity on its own.^To clarify, it performs these operations independently (either OR or AND), not simultaneously^For example, this can be done by using a value matrix that is “parallel” to e(1) and “orthogonal” to e(0). ^The entries involve because each attention score is either 0 or 1, so the softmax exponentiates to either or .Discuss Read More
How many attention heads do you need to do XOR?
You need at least two attention heads to do XOR, and we will find that it is a surprisingly crisp result which uses only high-school algebra.IntroductionComputing XOR using an attention head. Two input bits and are embedded, processed by an attention head with a skip connection, and read out by a logistic regression classifier. Can the internal activations after the skip connection be used to predict XOR?A single attention head can already do Boolean operations like OR and AND on two input bits, but it cannot do XOR[1]. We will show this using the setup outlined in the above figure: by checking if there exists a logistic regression probe on the internal activations of the query token = to predict[2] . Since the skip connection is constant across all , it can be absorbed into the threshold , so the probe logit depends only on the attention update : If the probe correctly classifies XOR, then it must satisfyMore explicitly, the above equation can be written as: The key fact is that in the single-head setting, for every choice of probe , there exist positive numbers such that But this is impossible under the inequalities above: since each is positive, we would have contradicting the equality. So a single attention head cannot linearly separate XOR.However, two heads are enough. Conceptually, one head detects 0 and the other detects 1. On the mixed inputs 01 and 10, both heads contribute; on 00 and 11, only one of them does. A linear readout can then separate the mixed cases from the same-bit ones.This means you need at least two attention heads to do XOR.[3]SetupWe work with sequences of length 3 over the vocabulary . On input , the model sees the sequence .Self Attention 101Each token has a token embedding , and each position has a positional embedding . The embedded sequence isA single attention head is parameterized by the query, key and value matrices denoted as respectively. The = token attends to all three positions via softmax attention, resulting in the residual stream :where the is attention weight from the key to the = token given as:The = token’s residual stream after the attention head has two parts: the skip connection (its original embedding) and the attention update (the new information it gathered by attending to and ): Since doesn’t depend on the input bits at all, any probe can fold it into its threshold . So the only thing that matters for classification is the attention update . Let denote the value vector at position . The attention update is then a convex combination of these value vectors, weighted by the attention probabilities : The attention probabilities are the softmax of the raw attention logits , which measure how strongly the = token’s query matches each key: resulting in the following attention weights: So we can equivalently write the attention update directly in terms of the ‘s: We now ask: can a hyperplane separate the four attention outputs into the XOR classes? One attention head can do OR and AND[4]It is worth noticing that XOR is the first interesting example here since a single head can already do OR and AND.Here is a simple way to see it. Take a head that attends to 1 tokens and writes a positive value when it reads one.[5] Its output increases with the number of ones, so it produces a score that is monotone in : Now thresholding does the rest:threshold below the medium value gives , i.e. OR;threshold between medium and high gives , i.e. AND.So one head can do monotone threshold functions of just fine. XOR is different because it is not monotone: it fires at but not at or . No single threshold can pick out the middle value from both sides.One attention head cannot do XORHere we are going to work towards a short proof why a single attention head cannot do XOR. The key identitiesIn the setup section, we saw that the attention update takes the formwhere and . Note that , since it will turn out useful later.The key structural fact is that and each split into an -only term, a -only term, and a constant: Because of this, summing over the main diagonal versus the off-diagonal yields identical totals — in both cases you collect exactly one copy each of the and contributions, and one copy each of the and contributions. This gives the key identities: Proof by contradictionSuppose there exists a probe that correctly classifies XOR. This means:so the probe scores must satisfy the XOR sign pattern: Let’s define the denominator-weighted probe score :Since , the XOR sign pattern on the probe scores carries over to :Because is linear in and , the key identities pass straight through to :But the XOR sign pattern forces and , which contradicts the equality above. Conclusion. A single attention head with a linear readout cannot compute XOR.Two heads can do XORNow we switch from one head to two parallel heads. For the existence proof, it is enough to write the residual update as the sum of the two head outputs:whereThe idea is simple:Head 0 softly detects token 0 and writes in one direction;Head 1 softly detects token 1 and writes in an orthogonal direction.Then the mixed inputs 01 and 10 are exactly the cases where both heads contribute.An explicit constructionLet’s work in , with no positional embeddings, and choose the token embeddings as follows:We choose the query, key, value and output matrices for each head as shown below, along with the resulting attention scores and weights from the = query position. The construction is symmetric by design: Head 0 attends preferentially to token 0 and writes in the directionHead 1 attends preferentially to token 1 and writes in the directionEach entry[6] is the triplet of softmax attention weights that the = query assigns to positions respectively, for that head and input. The weights are non-negative and sum to 1. We can now compute the attention update from each head across all four inputs. The same-bit inputs and each activate only one head, while the mixed inputs and activate both heads equally. The mixed inputs therefore have a strictly larger total activation, which a linear readout can exploit.Choosing , the probe score takes only two distinct values: The mixed inputs score strictly higher, so any threshold together with correctly classifies XOR.Conclusion. Two attention heads are sufficient to compute XOR with a linear readout.TakeawayThe single-head impossibility comes down to a structural constraint. Once you weight the probe score by the attention denominator , the result always decomposes as , an additive table with no interaction between and . Since , and the probe score share the same sign, so this additive structure is the true obstruction. XOR requires the checkerboard sign pattern, i.e. firing on the off-diagonal, not on the diagonal, which no additive table can realize.Two heads fix this by providing two independent soft detectors. The mixed inputs and are the only cases where both detectors fire at once, creating a gap in the probe scores that a linear readout can exploit.In a single-layer, attention-only model with a linear readout from the query position, we saw that1 head is not enough for any choice of dimension, embeddings, positional embeddings, or linear readout.2 heads are enough, via the explicit construction above.Together, these establish that two attention heads are necessary and sufficient to compute XOR with a logistic regression probe.^XOR is denoted by in equations. ^This is used to classify just four points. 00 and 11 map to 0 whereas 01 and 10 map to 1. ^Throughout this post, the model is attention-only: there are no MLPs, layer norms, or bias terms. Adding an MLP after the attention layer could solve XOR with a single head, since the MLP can implement the needed nonlinearity on its own.^To clarify, it performs these operations independently (either OR or AND), not simultaneously^For example, this can be done by using a value matrix that is “parallel” to e(1) and “orthogonal” to e(0). ^The entries involve because each attention score is either 0 or 1, so the softmax exponentiates to either or .Discuss Read More
Related Posts

Anthropic is (probably) not meeting its RSP security commitments
Published on November 18, 2025 11:34 PM GMTTLDR: An AI company's model weight security is…
Google seemingly solved efficient attention
Published on December 21, 2025 1:54 PM GMTCrosspost from my substack[Epistemic status - speculative, but…
Studying Mechanistic of Alignment Faking in Llama-3.1-405B
Published on November 25, 2025 11:21 AM GMTThe Problem: How can we explain why alignment…