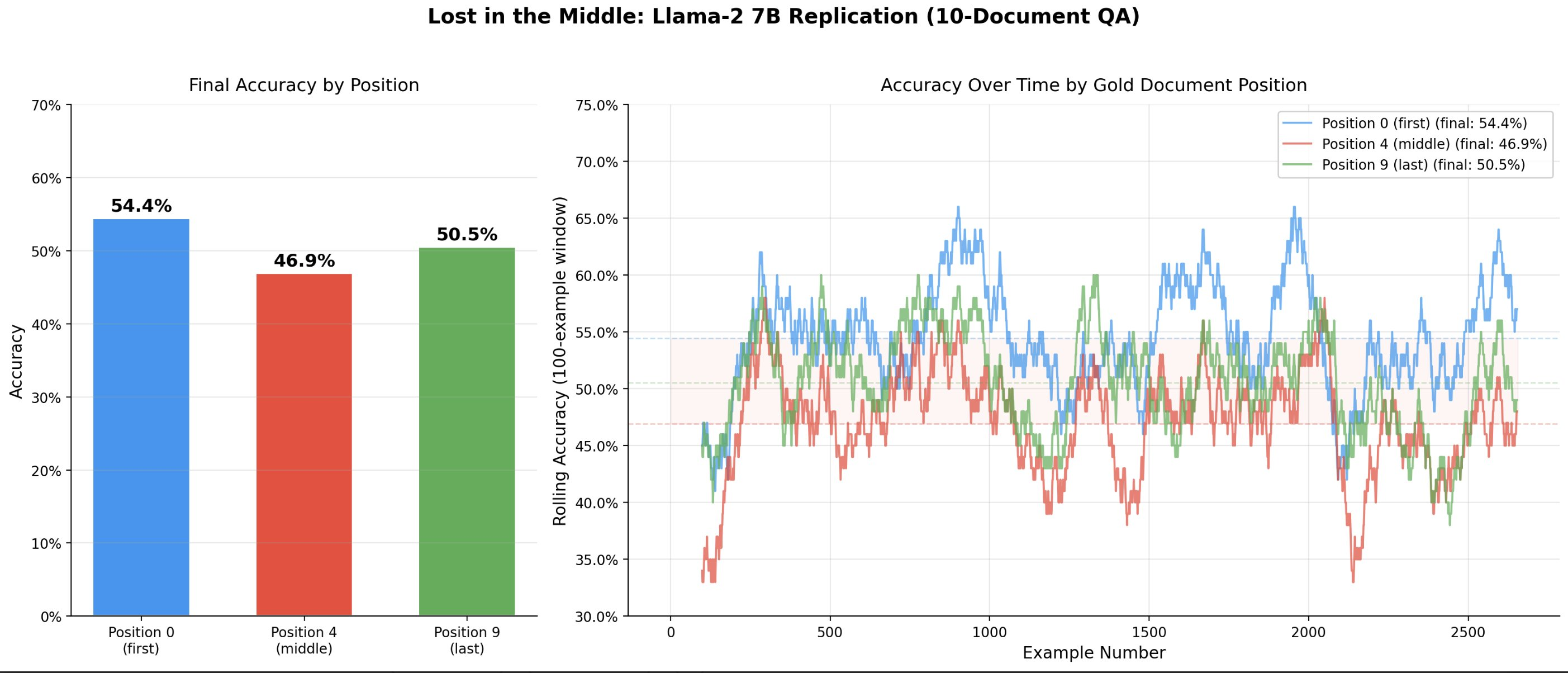
I was able to replicate some of the results from Liu et al’s “Lost in the Middle” paper using a quantized Llama-2 7B model.I used the multi-document question answering task from Liu et al. The model receives a question along with 10 retrieved documents (Wikipedia passages), exactly one of which contains the answer. The model must read all documents and produce the correct answer.I used the exact dataset published by Liu et al., based on Natural Questions (NQ-Open) – a collection of real Google search queries with short factual answers derived from Wikipedia. For the 10-document setting, the dataset provides 2,655 test examples at each of three gold document positions:Position 0 – the answer-containing document is placed firstPosition 4 – the answer-containing document is placed in the middle (5th of 10)Position 9 – the answer-containing document is placed lastEach test example consists of the same question and the same 10 documents; only the position of the gold (answer-containing) document varies. The 9 distractor documents are real Wikipedia passages retrieved for the same query that do not contain the answer.The “U-Shaped” effect where the model did worse at answering questions based on information contained in Position 4 did replicate, though personally I’d describe it more as a Nike Swoosh. Note that the Liu et al. paper did a 20 document test for some of the models, which I did not bother to replicate as the primary purpose of this replication was just to establish a baseline for my own internal use.Discuss Read More
“Lost in the Middle” Replicates
I was able to replicate some of the results from Liu et al’s “Lost in the Middle” paper using a quantized Llama-2 7B model.I used the multi-document question answering task from Liu et al. The model receives a question along with 10 retrieved documents (Wikipedia passages), exactly one of which contains the answer. The model must read all documents and produce the correct answer.I used the exact dataset published by Liu et al., based on Natural Questions (NQ-Open) – a collection of real Google search queries with short factual answers derived from Wikipedia. For the 10-document setting, the dataset provides 2,655 test examples at each of three gold document positions:Position 0 – the answer-containing document is placed firstPosition 4 – the answer-containing document is placed in the middle (5th of 10)Position 9 – the answer-containing document is placed lastEach test example consists of the same question and the same 10 documents; only the position of the gold (answer-containing) document varies. The 9 distractor documents are real Wikipedia passages retrieved for the same query that do not contain the answer.The “U-Shaped” effect where the model did worse at answering questions based on information contained in Position 4 did replicate, though personally I’d describe it more as a Nike Swoosh. Note that the Liu et al. paper did a 20 document test for some of the models, which I did not bother to replicate as the primary purpose of this replication was just to establish a baseline for my own internal use.Discuss Read More
Related Posts

Exploring Reinforcement Learning Effects on Chain-of-Thought Legibility
Published on January 6, 2026 3:04 AM GMTThis project was conducted as part of the…
Introducing ControlArena: A library for running AI control experiments
Published on October 24, 2025 9:51 AM GMTThis has been a collaborative effort between UK…
Why your boss isn’t worried about AI
Published on October 14, 2025 5:58 PM GMT(a note for technical folk)[1]When it comes to…