Current face video forgery detectors use wide or dual-stream backbones. We show that a single, lightweight fusion of two handcrafted cues can achieve higher accuracy with a much smaller model. Based on the Xception baseline model (21.9 million parameters), we build two detectors: LFWS, which adds a 1×1 convolution to combine a low-frequency Wavelet-Denoised Feature (WDF) with the phase-only Spatial-Phase Shallow Learning (SPSL) map, and LFWL, which merges WDF with Local Binary Patterns (LBP) in the same way. This extra module adds only 292 parameters, keeping the total at 21.9 million—smaller… Read More
Multi-Frequency Fusion for Robust Video Face Forgery Detection
Current face video forgery detectors use wide or dual-stream backbones. We show that a single, lightweight fusion of two handcrafted cues can achieve higher accuracy with a much smaller model. Based on the Xception baseline model (21.9 million parameters), we build two detectors: LFWS, which adds a 1×1 convolution to combine a low-frequency Wavelet-Denoised Feature (WDF) with the phase-only Spatial-Phase Shallow Learning (SPSL) map, and LFWL, which merges WDF with Local Binary Patterns (LBP) in the same way. This extra module adds only 292 parameters, keeping the total at 21.9 million—smaller…

Related Posts
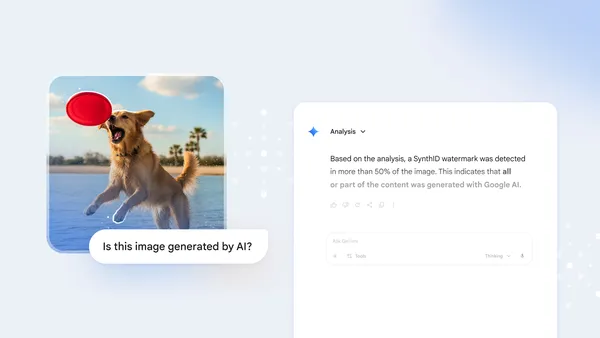
How we’re bringing AI image verification to the Gemini app
Our new Gemini app feature allows you to verify Google AI images and determine whether…

New AI-powered features help you connect with web content in Search and Discover.
We’re introducing two new AI-powered features in Search and Discover to help you connect with…

Our 2026 Responsible AI Progress Report
A look at our 2026 Responsible AI Progress Report.