
Efficient large-scale inference of transformer-based large language models (LLMs) remains a fundamental systems challenge, frequently requiring multi-GPU parallelism to meet stringent latency and throughput targets. Conventional tensor parallelism decomposes matrix operations across devices but introduces substantial inter-GPU synchronization, leading to communication bottlenecks and degraded scalability. We propose the Parallel Track (PT) Transformer, a novel architectural paradigm that restructures computation to minimize cross-device dependencies. PT achieves up to a 16x reduction in… Read More
Parallel Track Transformers: Enabling Fast GPU Inference with Reduced Synchronization
Efficient large-scale inference of transformer-based large language models (LLMs) remains a fundamental systems challenge, frequently requiring multi-GPU parallelism to meet stringent latency and throughput targets. Conventional tensor parallelism decomposes matrix operations across devices but introduces substantial inter-GPU synchronization, leading to communication bottlenecks and degraded scalability. We propose the Parallel Track (PT) Transformer, a novel architectural paradigm that restructures computation to minimize cross-device dependencies. PT achieves up to a 16x reduction in…

Related Posts

10 Python One-Liners for Calling LLMs from Your Code
You don’t always need a heavy wrapper, a big client class, or dozens of lines…

We’re celebrating Geoffrey Hinton’s Nobel-winning legacy with the University of Toronto.
Today, we are celebrating the extraordinary impact of Nobel Prize-winner Geoffrey Hinton by investing in…
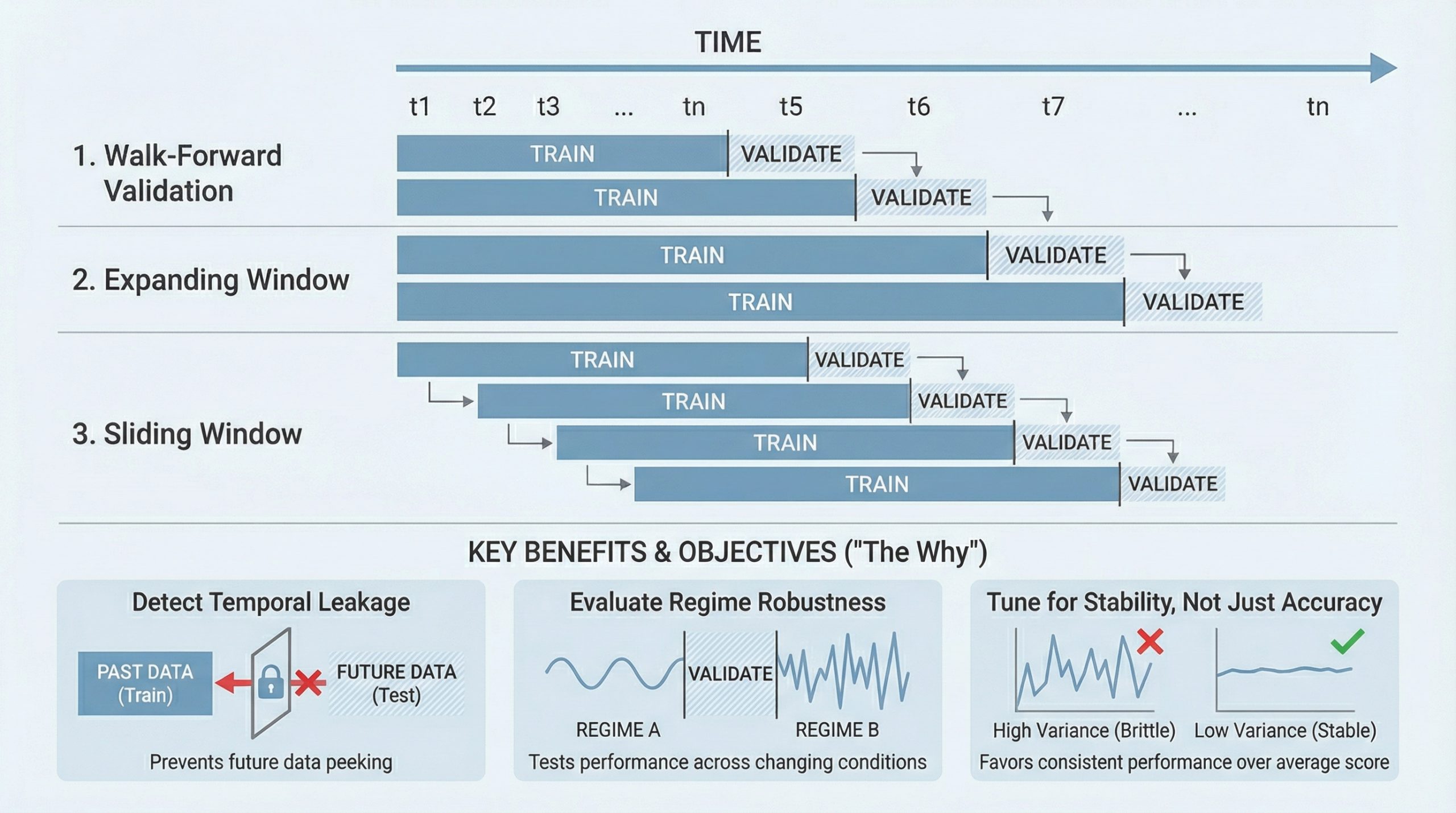
5 Ways to Use Cross-Validation to Improve Time Series Models
Time series modeling