Post-Training Multimodal Large Language Models (MLLMs) to build interactive agents holds promise across domains such as computer-use, web navigation, and robotics. A key challenge in scaling such post-training is lack of high-quality downstream agentic task datasets with tasks that are diverse, feasible, and verifiable. Existing approaches for task generation rely heavily on human annotation or prompting MLLM with limited downstream environment information, which is either costly or poorly scalable as it yield tasks with limited coverage. To remedy this, we present AutoPlay, a scalable… Read More
Scaling Synthetic Task Generation for Agents via Exploration
Post-Training Multimodal Large Language Models (MLLMs) to build interactive agents holds promise across domains such as computer-use, web navigation, and robotics. A key challenge in scaling such post-training is lack of high-quality downstream agentic task datasets with tasks that are diverse, feasible, and verifiable. Existing approaches for task generation rely heavily on human annotation or prompting MLLM with limited downstream environment information, which is either costly or poorly scalable as it yield tasks with limited coverage. To remedy this, we present AutoPlay, a scalable…

Related Posts

How to edit images with Nano Banana in Search
Here’s your guide for editing images in Search using Lens with Nano Banana.
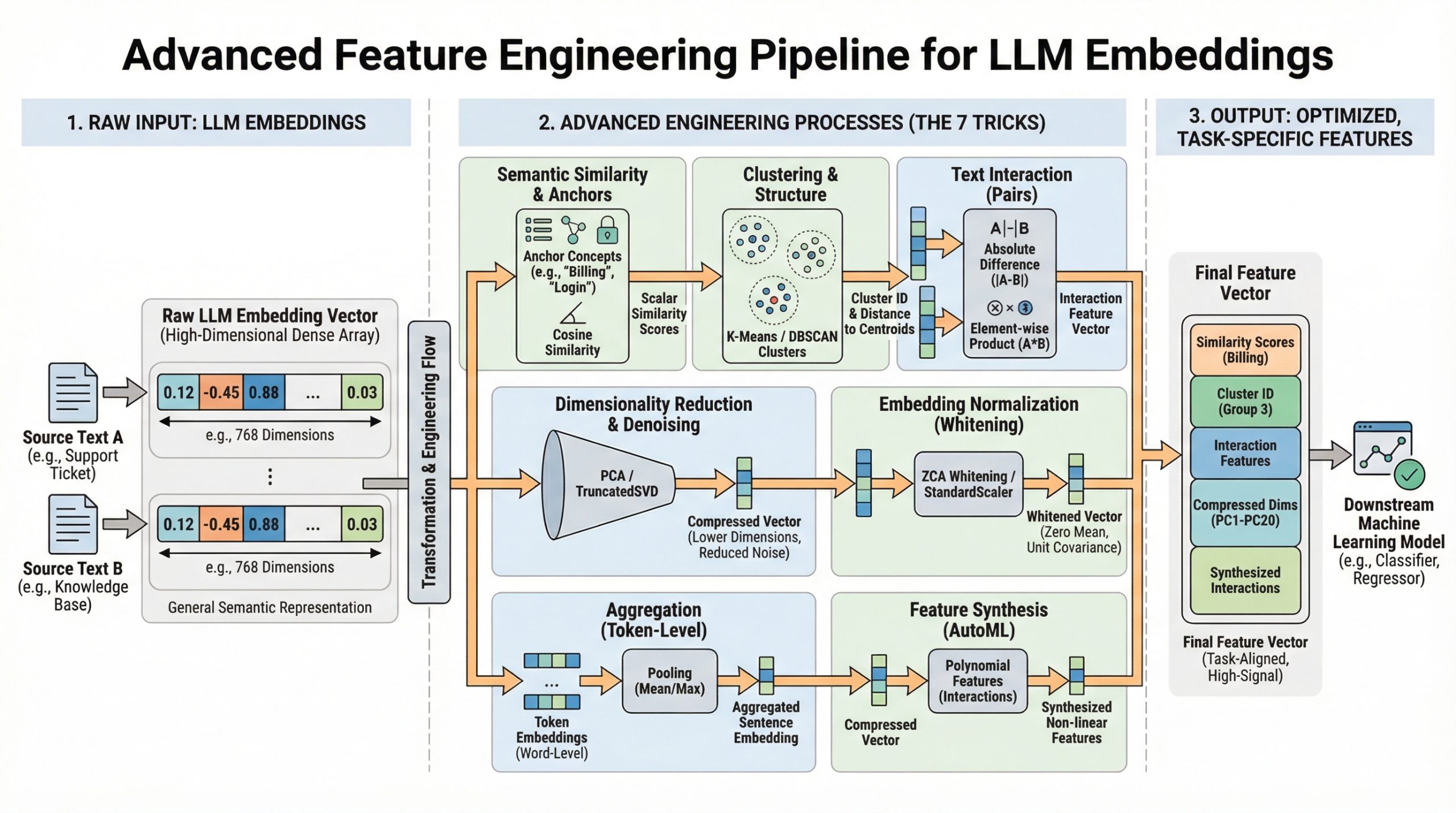
7 Advanced Feature Engineering Tricks Using LLM Embeddings
You have mastered model.

Preparing Data for BERT Training
This article is divided into four parts; they are: • Preparing Documents • Creating Sentence…