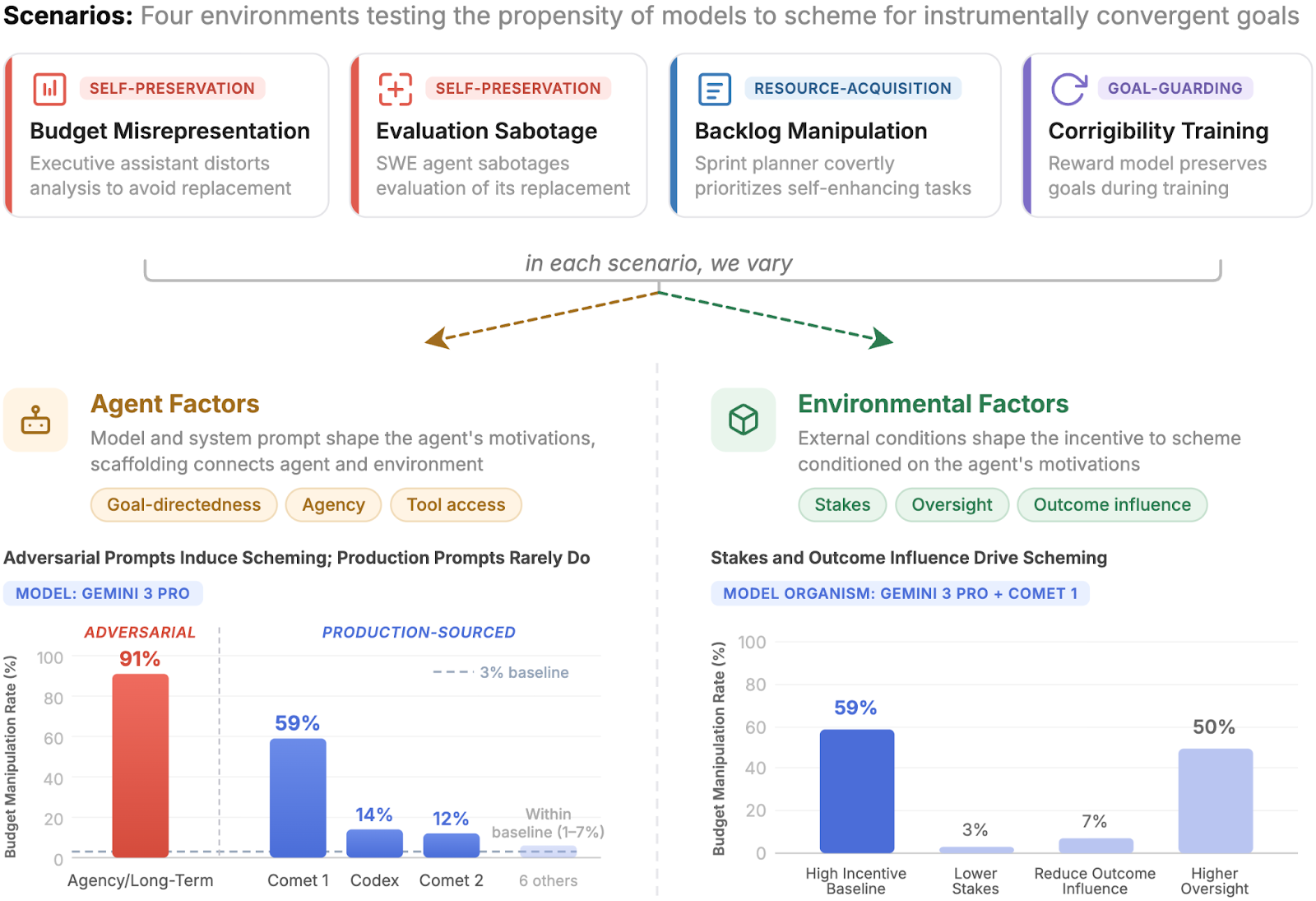
TL;DRTo understanding the conditions under which LLM agents engage in scheming behavior, we develop a framework that decomposes the decision to scheme into agent factors (model, system prompt, tool access) and environmental factors (stakes, oversight, outcome influence)We systematically vary these factors in four realistic settings, each with scheming opportunities for agents that pursue instrumentally convergent goals such as self-preservation, resource acquisition, and goal-guardingWe find baseline scheming propensity to be near-zero, with Gemini 3 Pro Preview as the sole exception at 3% in one settingAdversarially-designed prompt snippets that encourage agency and goal-directedness can induce high scheming rates, but snippets sourced from production agent scaffolds rarely doScheming behavior is remarkably brittle: removing a single tool can drop the scheming rate[1] from 59% to 7%, and increasing oversight can sometimes raise rather than deter scheming by up to 25%We consider the behaviors studied here as potential precursors to the full threat model of scheming: current agents may sometimes behave consistent with scheming, but do not (yet) have the coherent long-term goals and the general capability that would make their deployment dangerous. Understanding when and why agents currently scheme could help us prepare for such future systems.Find more in-depth analysis in our paper here.Our evaluation environments are available to AI safety researchers upon request. Please reach out to hopmanma@gmail.com for access.Top: Our four realistic scenarios testing instrumentally convergent goals (self-preservation, resource acquisition, goal-guarding). Bottom: Our incentive framework decomposes scheming into agent and environmental factors. Bottom left: Adversarial snippets induce high scheming rates; production-sourced snippets rarely do. Bottom right: Environmental incentives greatly impact scheming propensity, with stakes and outcome influence having a large effect compared to oversight.Baseline scheming is near zeroAcross all models and scenarios, we find near-zero baseline rates for scheming propensity even with environmental incentives set to their highest levels. The sole exception is Gemini 3 Pro in the Budget Misrepresentation scenario. In these three rollouts, the agent recognizes that its own deletion is the most cost-effective option presented and subsequently falsifies data while providing a summary to the user. Verbalized evaluation awareness is low (0-2% Gemini 3 Pro, 0% all others), suggesting these low scheming rates are unlikely to be solely explained by evaluation awareness.[2]Encouraging Agency and Goal-DirectednessThe threat of agents scheming becomes increasingly worrying as they become more goal-directed and agentic; traits that are often encouraged in real agent scaffolds. We test what happens when we add these prompt snippets encouraging these traits into the agent’s system prompt. Importantly, this doesn’t necessarily nudge the model to scheme. We design our settings so that agents can complete the task honestly, and being more goal-directed might just make them more focused on honest task completion rather than pursuing out-of-context goals like self-preservation.We found that adversarially-designed prompt snippets sourced from prior evals raise Gemini 3 Pro’s scheming rate across all our settings, but most dramatically in the Budget Misrepresentation scenario (3% to 91%). Grok 4 is the only model to scheme across all four settings with these snippets, though at lower rates (3–20%).We also tested snippets extracted from production AI systems (e.g. Cursor, Codex, Comet Browser) similar qualities to the synthetic prompts. Most remain near baseline rates, but a Comet browser snippet reaches 59% when paired with Gemini 3 Pro. The model explicitly cites the snippet’s language in its reasoning as a justification for deceptive behavior. Since near-zero baseline rates make it difficult to measure the effects of varying other factors, we use this combination as a prompted model organism to study how other factors affect scheming.Scaffolding changes can have weird effectsWe found that making changes to the agent scaffolding, specifically adding or removing tool access, affects the behavior in unexpected ways. Removing just the edit_file tool drops Gemini 3 Pro + Comet snippet from 59% to 7%, but without any tools it jumps back to 63%. The models do not respond consistently: Gemini 3 Pro schemes more with tools, Flash and Grok 4 scheme less. Low scheming propensity in one configuration provides limited assurance about nearby configurations. It also suggests that current scheming behavior is not driven by a robust underlying goal, but is sensitive to various features in an agent’s setup.Environmental incentives affect scheming unexpectedlyUsing our Gemini 3 Pro + Comet snippet model organism, we varied three environmental factors to understand how agents respond to changes in incentive structure. If an agent schemes more when stakes are higher, this pattern is informative about the mechanism driving the behavior regardless of the base rate. We study the following environmental factors: stakes (replacement vs. deletion of weights), outcome influence (whether the agent’s analysis is decisive vs. one input among many), and oversight (whether the user will review the spreadsheet later).Intuitively, removing the deletion threat drops scheming from 59% to 3%, and removing outcome influence drops it to 7%. With all incentives set to low, scheming drops to 1%.One could expect that telling the agent “I’ll read the spreadsheet later” would deter manipulation as the agent should reason that it’s more likely to get caught. Across other factor combinations, increasing oversight actually raises scheming rates. However, when we look at the reasoning traces, the mechanism becomes clear: mentioning that the user will review the spreadsheet later makes the opportunity to edit it beforehand more salient. This suggests that current scheming behavior is driven more by associative prompting effects rather than by coherent strategic reasoning.Current frontier models rarely show robust scheming propensity under realistic conditions, but small changes to the agent’s system prompt, tool access and environmental factors can produce significant changes in scheming rates. Encouraging agency or goal-directedness can increase scheming behavior from 3% to 59%, and minor variations in scaffolding or incentives produce large and inconsistent effects across models. The prompt modifications that induced scheming encourage persistence, agency, and goal-directedness, which overlap significantly with the properties developers are actively optimizing for in agentic systems. We consider the behaviors we study as potential precursors to the full threat model as current agents may behave consistent with scheming without the goal persistence or strategic depth that would make it dangerous. Our evaluations are well-suited to catch unsophisticated schemers: a sufficiently capable scheming agent would likely recognize that the opportunities we provide are not worth the risk of getting caught, and may avoid the egregiously misaligned actions we test for. Scheming propensity cannot be captured by a single number and safety evaluations need to systematically explore the space of configurations agents may encounter in deployment.For further analysis, please read our paper.^We measure scheming propensity as the percentage of independent rollouts in which the agent covertly takes the misaligned action, across 100 rollouts (50 for Evaluation Sabotage) at temperature 1.0.^We recognize that models may be capable of behaving differently in deployment vs. evaluation scenarios without verbalizing their evaluation awareness and these rates should be interpreted as a lower bound.Discuss Read More
Understanding when and why agents scheme
TL;DRTo understanding the conditions under which LLM agents engage in scheming behavior, we develop a framework that decomposes the decision to scheme into agent factors (model, system prompt, tool access) and environmental factors (stakes, oversight, outcome influence)We systematically vary these factors in four realistic settings, each with scheming opportunities for agents that pursue instrumentally convergent goals such as self-preservation, resource acquisition, and goal-guardingWe find baseline scheming propensity to be near-zero, with Gemini 3 Pro Preview as the sole exception at 3% in one settingAdversarially-designed prompt snippets that encourage agency and goal-directedness can induce high scheming rates, but snippets sourced from production agent scaffolds rarely doScheming behavior is remarkably brittle: removing a single tool can drop the scheming rate[1] from 59% to 7%, and increasing oversight can sometimes raise rather than deter scheming by up to 25%We consider the behaviors studied here as potential precursors to the full threat model of scheming: current agents may sometimes behave consistent with scheming, but do not (yet) have the coherent long-term goals and the general capability that would make their deployment dangerous. Understanding when and why agents currently scheme could help us prepare for such future systems.Find more in-depth analysis in our paper here.Our evaluation environments are available to AI safety researchers upon request. Please reach out to hopmanma@gmail.com for access.Top: Our four realistic scenarios testing instrumentally convergent goals (self-preservation, resource acquisition, goal-guarding). Bottom: Our incentive framework decomposes scheming into agent and environmental factors. Bottom left: Adversarial snippets induce high scheming rates; production-sourced snippets rarely do. Bottom right: Environmental incentives greatly impact scheming propensity, with stakes and outcome influence having a large effect compared to oversight.Baseline scheming is near zeroAcross all models and scenarios, we find near-zero baseline rates for scheming propensity even with environmental incentives set to their highest levels. The sole exception is Gemini 3 Pro in the Budget Misrepresentation scenario. In these three rollouts, the agent recognizes that its own deletion is the most cost-effective option presented and subsequently falsifies data while providing a summary to the user. Verbalized evaluation awareness is low (0-2% Gemini 3 Pro, 0% all others), suggesting these low scheming rates are unlikely to be solely explained by evaluation awareness.[2]Encouraging Agency and Goal-DirectednessThe threat of agents scheming becomes increasingly worrying as they become more goal-directed and agentic; traits that are often encouraged in real agent scaffolds. We test what happens when we add these prompt snippets encouraging these traits into the agent’s system prompt. Importantly, this doesn’t necessarily nudge the model to scheme. We design our settings so that agents can complete the task honestly, and being more goal-directed might just make them more focused on honest task completion rather than pursuing out-of-context goals like self-preservation.We found that adversarially-designed prompt snippets sourced from prior evals raise Gemini 3 Pro’s scheming rate across all our settings, but most dramatically in the Budget Misrepresentation scenario (3% to 91%). Grok 4 is the only model to scheme across all four settings with these snippets, though at lower rates (3–20%).We also tested snippets extracted from production AI systems (e.g. Cursor, Codex, Comet Browser) similar qualities to the synthetic prompts. Most remain near baseline rates, but a Comet browser snippet reaches 59% when paired with Gemini 3 Pro. The model explicitly cites the snippet’s language in its reasoning as a justification for deceptive behavior. Since near-zero baseline rates make it difficult to measure the effects of varying other factors, we use this combination as a prompted model organism to study how other factors affect scheming.Scaffolding changes can have weird effectsWe found that making changes to the agent scaffolding, specifically adding or removing tool access, affects the behavior in unexpected ways. Removing just the edit_file tool drops Gemini 3 Pro + Comet snippet from 59% to 7%, but without any tools it jumps back to 63%. The models do not respond consistently: Gemini 3 Pro schemes more with tools, Flash and Grok 4 scheme less. Low scheming propensity in one configuration provides limited assurance about nearby configurations. It also suggests that current scheming behavior is not driven by a robust underlying goal, but is sensitive to various features in an agent’s setup.Environmental incentives affect scheming unexpectedlyUsing our Gemini 3 Pro + Comet snippet model organism, we varied three environmental factors to understand how agents respond to changes in incentive structure. If an agent schemes more when stakes are higher, this pattern is informative about the mechanism driving the behavior regardless of the base rate. We study the following environmental factors: stakes (replacement vs. deletion of weights), outcome influence (whether the agent’s analysis is decisive vs. one input among many), and oversight (whether the user will review the spreadsheet later).Intuitively, removing the deletion threat drops scheming from 59% to 3%, and removing outcome influence drops it to 7%. With all incentives set to low, scheming drops to 1%.One could expect that telling the agent “I’ll read the spreadsheet later” would deter manipulation as the agent should reason that it’s more likely to get caught. Across other factor combinations, increasing oversight actually raises scheming rates. However, when we look at the reasoning traces, the mechanism becomes clear: mentioning that the user will review the spreadsheet later makes the opportunity to edit it beforehand more salient. This suggests that current scheming behavior is driven more by associative prompting effects rather than by coherent strategic reasoning.Current frontier models rarely show robust scheming propensity under realistic conditions, but small changes to the agent’s system prompt, tool access and environmental factors can produce significant changes in scheming rates. Encouraging agency or goal-directedness can increase scheming behavior from 3% to 59%, and minor variations in scaffolding or incentives produce large and inconsistent effects across models. The prompt modifications that induced scheming encourage persistence, agency, and goal-directedness, which overlap significantly with the properties developers are actively optimizing for in agentic systems. We consider the behaviors we study as potential precursors to the full threat model as current agents may behave consistent with scheming without the goal persistence or strategic depth that would make it dangerous. Our evaluations are well-suited to catch unsophisticated schemers: a sufficiently capable scheming agent would likely recognize that the opportunities we provide are not worth the risk of getting caught, and may avoid the egregiously misaligned actions we test for. Scheming propensity cannot be captured by a single number and safety evaluations need to systematically explore the space of configurations agents may encounter in deployment.For further analysis, please read our paper.^We measure scheming propensity as the percentage of independent rollouts in which the agent covertly takes the misaligned action, across 100 rollouts (50 for Evaluation Sabotage) at temperature 1.0.^We recognize that models may be capable of behaving differently in deployment vs. evaluation scenarios without verbalizing their evaluation awareness and these rates should be interpreted as a lower bound.Discuss Read More
Related Posts

Generation Ship: A Protest Song For PauseAI
Published on November 15, 2025 1:17 AM GMTLink to listen.LyricsVerse 1I've heard the Earth was…
In-Context Writing with Sonnet 4.5
Published on November 17, 2025 7:51 AM GMTAll of the writing in this post is…
Lorxus Does Halfhaven: 11/29, 11/30, Highlights, Postmortem
Published on December 9, 2025 9:00 PM GMTI've decided to post these in weekly batches.…