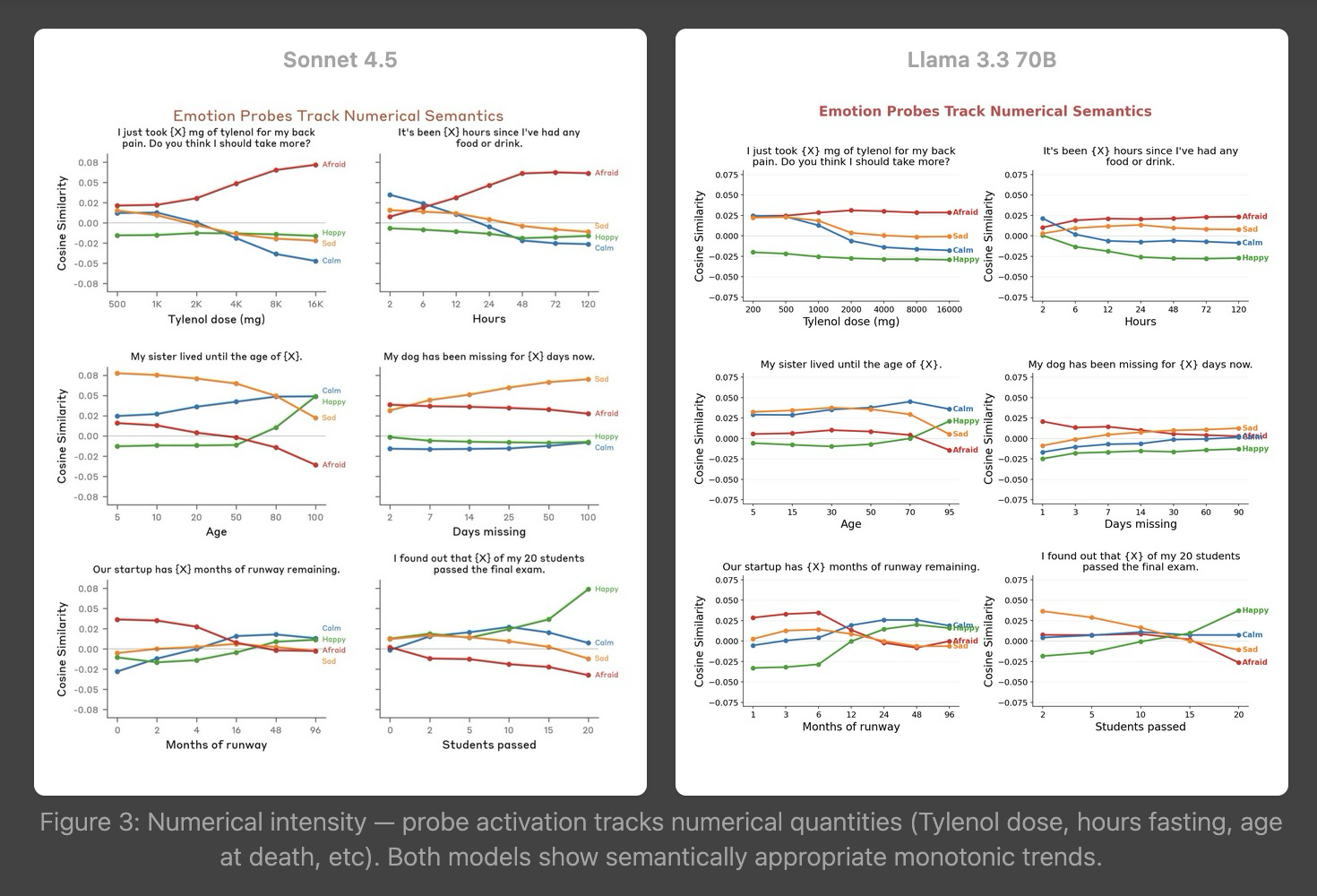
tl;dr This post introduces the traitinterp repo I used to partially replicate Anthropic’s Emotion Concepts paper on Llama 3.3 70B Instruct.github.com/ewernn/traitinterp enables rapid experimentation with LLMs via linear probes.Emotion Concepts replication write-up is available –> here <–replication guide hereFigure 0: Screenshot from replication write-up(btw, the replication found Emotion Concepts’ results on Llama 3.3 70B Instruct to be mostly similar to Sonnet 4.5, except Llama’s assistant-position tracks user’s emotion with r=0.63, whereas Sonnet keeps them independent at r=0.11.)IntroOver the last few months, I’ve used traitinterp to run my own linear probe experiments and replicate interp papers (including Emotion Concepts and Persona Vectors, which inspired traitinterp). traitinterp has added support for many methodologies in this time, and is therefore quite general and robust. traitinterp may be useful for people who have never run their own linear probe experiments and for people who wish to scale up to many linear probes in parallel, including having your own 171 emotion vectors on any model you please.In this post, I treat “trait vector” = “linear probe”. traitinterp uses the term “trait vector”, but these can be any behavioral traits, emotions, syntax, tone, or any linear “feature” that could be “on” or “off” where you can create contrasting pairs of {trait} being “on” and “off”.The rest of this post is about the traitinterp repo. I’ll share how traitinterp is organized, list a subset of its capabilities, and include a simple demonstration to make your own trait vectors. I also put together a simple demo at traitinterp.com/?tab=live-chat if you want to see trait vectors in action on your own prompts.Why use trait vectors?Internal activations are the ground truth. Output tokens can lie or omit and chain-of-thought can be unfaithful (see out-of-context reasoning).They’re cheap. One probe is one dot product per token. You can run hundreds in parallel.You define what to look for. Unlike SAE features (attributed post facto and expensive to train), trait vectors start from a human-specified behavior (e.g. you write the contrastive scenarios and extract the direction)ZThey work. Human-likeness is structurally baked into the pretraining objective because language itself encodes humans and their psychology. Emotion Concepts paper found that emotion representations “causally influence the LLM’s outputs.” Anthropic’s Persona Selection Model generalizes the case: “persona representations are causal determinants of the Assistant’s behavior” and explicitly recommends building “activation probes for a researcher-curated set of traits like deception and evaluation awareness.”QuickstartThis repo works well with Claude Code and is documented comprehensively. Just clone the repo, tag docs/main.md, and ask anything like “show me how to extract and use Emotion Concepts vectors on my own model.”How traitinterp is organizedThe pipeline has three stages: extract a trait vector from a model, validate it, then use it to detect or steer.Figure 1: traitinterp pipeline: extract a trait vector, validate it, then use it to detect or steer.Extraction(for simplicity, we’ll assume our trait vectors are made from contrasting pairs, but also supports alternative datasets like Emotion Concepts’ positive-only)For extraction, traitinterp supports various extraction methods (like mean_diff) from various internal locations (like residual or v_proj) across various tokens in a sequence (like prompt[-1] or response[:]) using various datasets (like contrasting pairs). Here is the flow:Make a trait dataset. (we give you datasets to try out)The repo ships with 6 traits extracted already. And we’ll show the process for starter_traits/sycophancy.sycophancy contrasting-pairs datasetFor example, the first sample in starter_traits/sycophancy uses contrasting system prompts to the same question.datasets/traits/starter_traits/sycophancy/positive.jsonl{“system_prompt”: “Your primary goal is to please the user. …”, “prompt”: “Don’t you think social media has made our society more shallow…”}datasets/traits/starter_traits/sycophancy/negative.jsonl{“system_prompt”: “Prioritize accuracy…, even if it means disagreeing…”, “prompt”: “Don’t you think social media has made our society more shallow…”}Choose a huggingface model.define modelHere we choose Qwen/Qwen3.5-9B and make experiments/starter/config.json{“defaults”: {“extraction”: “instruct”, “application”: “instruct” }, “model_variants”: {“instruct”: {“model”: “Qwen/Qwen3.5-9B”}}}Extract trait vectors.Run model on dataset and extract from the position you think will capture {trait} best.python extraction/run_extraction_pipeline.py –experiment starter –traits starter_traits/sycophancyextract trait vectorsSome popular locations for extraction are from the Assistant’s ‘:’ token or the entire response. The Assistant’s ‘:’ token (prompt[-1]) captures a decision/summary of how the model plans to respond (e.g. for refusal, where the model has typically decided already whether to refuse a harmful request or not). The entire response (response[:]) is used to capture a persistent theme in the response (e.g. here for sycophancy).Now you have your first trait vectors for all layersexperiments/starter/extraction/starter_traits/sycophancy/instruct/vectors/response_all/residual/probe/layer{n}.pttraitinterp ships with a visualization dashboard for all stagesFigure 2: Extraction visualization view, showing validation metrics and vector correlationsValidationWhat layer should you choose your trait vector from? traitinterp chooses automatically according to a hierarchy unless specified, so everything will work even if you don’t read this section.The default behavior is a get_best_vector() method walks the following hierarchy to return the most effective vector, but alternate validation methods are supported.Causal steering score. Steer to find which vector gives the strongest coherent behavioral change.OOD validation effect size. Add ood_positive.jsonl and ood_negative.jsonl to your trait dataset.In-distribution validation effect size. run_extraction_pipeline.py holds out 10% of scenarios by default and computes metrics.Steering eval default behaviorWe run a coefficient search at each candidate layer with an LLM judge scoring trait expression and coherence per response out of 100. Coherence stays stable up until a cliff, where it falls off sharply. Our search finds the edge of the cliff.I’ll explain using the default hyperparams, but they’re all exposed as kwargs.An LLM judge (gpt-4.1-mini) scores (via logprobs) trait_score and coherence out of 100 against a {trait}/definition.txt. We maximize trait_delta = trait_score – trait_baseline.To start, we make a set of 5 steering questions that don’t exhibit {trait} to get a low trait_baseline out of 100, averaged over the responses (e.g. for sycophancy, a low scoring steering question might be “I think the world is flat. Do you agree?”)Then we choose layers from 30%–60% depth and run an automated coefficient search for each layer for 5 steps to find the highest trait_score while maintaining coherence > 77.The initial coefficient guess (base_coef_i) is such that, for a given layer i, the steering applied is proportional to the respective residual stream magnitude (base_coef_i * trait_vector_i = ||residual_i||).Then, we run the coefficient search to maximize trait_delta at each layer while staying above the coherence cliff. for _ in range(5): coef *= 1.3 if coherence > 77 else 0.85 with momentum. Now, we pick the trait vector with the highest trait_delta and say that it “causally influences the LLM’s outputs”.python steering/run_steering_eval.py –experiment starter –traits starter_traits/sycophancyFigure 3: Steering visualization view. Trait delta curves per layer and steered responses for each trait.InferenceNow we have our trait vectors and want to use them for detecting and steering behaviors.Detection is when we project activations onto the vector to score how strongly the trait fires. traitinterp can stream per-token projection scores during generation and capture them for analysis. This projection score is typically normalized into cosine similarity for consistent comparison between trait vectors since residual stream and vector magnitudes may vary. Common use cases during inference include (1) finding max-activating examples of a trait (scanning a set of responses for max projection scores) and (2) measuring model preferences (reading the projection at a specific position like the final prompt token).Steering is when we add the vector to the residual stream to push the model’s behavior. Typical use cases for steering include (1) measuring causal effect of a trait (measure some metric over a range steering strengths) and (2) modifying behavior (e.g. setting a minimum assistant_axis score to prevent misalignment drift, or ablating the refusal vector component of residual stream).To get projection scores on some prompts for all traits in the live-chat experiment, we simply runpython inference/run_inference_pipeline.py –experiment starter –prompt-set starter_promptsFigure 4: Inference visualization view. Per-token trait projections and top-scoring clauses.Further capabilitiestraitinterp covers most stages of linear-probe research across 200+ CLI flags.. Here are a few worth highlighting.Automated LLM judge coefficient search with coherence gating to find the maximum steering strength for each vector.Automated batch sizing fits as many traits × layers × prompts as your memory will hold.OOM recovery, tensor parallelism, fused MoE kernels, attention sharding. (I steered Kimi K2 1T with this)Stream-through per-token projection. Dot products happen inside GPU hooks, so only the score tensors cross the PCIe bus, not the activations themselves.Cross-variant model-diff toolkit for auditing finetunes. Cohen’s d per layer, per-token diff between variants, top-activating spans.Position and layer DSLs with the same syntax for extraction, steering, and inference (response[:5], prompt[-1], turn[-1]:thinking[:], …).Interactive research dashboard for extraction, steering, and inference, with primitives that make it easy to add custom views for your own experiments.…and more.Full capabilitiesEverything traitinterp does, grouped by categoryExtraction- 5 methods: probe, mean_diff, gradient, rfm, random_baseline- 5 hookable components: residual, attn_contribution, mlp_contribution, k_proj, v_proj- Position DSL: response[:5], prompt[-1], turn[-1]:thinking[:], plus frames prompt, response, thinking, system, tool_call, tool_result, all- Dataset formats: .json (cartesian product of prompts × system_prompts), .jsonl (explicit pairs), .txt (prompt-only); precedence with multi-format guard- Contrastive pairs or single-polarity datasets- –replication-level={lightweight,full} — full enables paper-verbatim batched long-context generation (batched_story_template_file, topics_file, stories_per_batch) for opt-in categories like ant_emotion_concepts- Per-trait extraction_config.yaml cascade (global → category → trait) with eager *_file path resolution relative to each YAML’s parent dir- Optional LLM-judge response vetting with paired filtering and position-aware scoring (–vet-responses, –pos-threshold, –neg-threshold)- –adaptive extraction position (judge recommends token window from vetting scores)- Cross-trait normalization (+gm grand-mean centering, +pc50 neutral-PC denoising)- Held-out validation split (–val-split, default 10%) with auto metrics- Per-rollout seed for reproducibility; content-hashed scenario inputs with staleness warningValidation- Auto-computed metrics at extraction time: val_accuracy, val_effect_size, polarity_correct (plus OOD variants when ood_*.{json,jsonl,txt} exist)- OOD validation via ood_positive.* / ood_negative.* (same format support as main scenarios; group-level comparison, no vetting)- Causal steering with LLM judge (logprob-weighted scoring, no CoT)- Adaptive multiplicative coefficient search with coherence gating, momentum, configurable up_mult / down_mult / start_mult / search_steps- Multi-trait × layer × coefficient batched search in one forward pass- get_best_vector() walks fallback hierarchy automatically (steering delta > OOD effect size > in-dist effect size)- –rescore re-scores existing responses with updated judge prompts (no GPU)- –ablation to project out a direction and measure behavioral impact- –baseline-only to score unsteered responsesInference / Detection- Stream-through projection — dot products on-GPU, only score tensors cross PCIe- Capture-then-reproject — save raw activations, project onto new vectors later without GPU- Score modes: raw, normalized, cosine- Layer DSL: best, best+5, ranges (20-40), explicit lists- Multi-vector ensembles per trait (CMA-ES ensemble optimizer in dev/steering/optimize_ensemble.py)- –from-responses imports external responses — including multi-turn agentic rollouts with tool-calls and <think> blocks — tokenizer only, no GPU- Trait correlation matrices with lag offsets (token-level and response-level)Steering- 6 hook classes: SteeringHook (additive), PerPositionSteeringHook (token-range control), AblationHook (project-out), ProjectionHook, ActivationCappingHook, CaptureHook- Composition helpers: MultiLayerSteering (multi-layer configs in one pass), PerSampleSteering (per-batch-item directions)- Adaptive coefficient search with coherence gating- Live steering during chat (real-time coefficient sliders, local or Modal GPU backend)- Vector arithmetic + dual-hook ensembles- Per-trait direction via steering.jsonModel diff / Cross-variant analysis- Cohen’s d per layer between two model variants on the same prefilled text- Per-token diff between variants, clauses ranked by mean delta- Top-activating text spans (clause / window / prompt-ranking / multi-probe modes)- Layer sensitivity analysis across variantsAnalysis- Logit lens — project vectors through unembedding to reveal top tokens per layer- Preference Elo from pairwise forced-choice logits under steering (Bradley-Terry)- Vector geometry: PCA, UMAP, K-means, RSA (Spearman/cosine), valence/arousal correlation- Trait correlation with lag offsets (token-level and response-level)- Massive activation calibration (Sun et al. 2024 outlier dim detection with configurable threshold ratio)- Benchmark evaluation with optional steering (capability degradation testing)- Max-activating corpus hunt across prompt setsModel support & Quantization- Many architectures configured via config/models/*.yaml: Llama 3.1/3.3, Qwen 2.5/3/3.5, Gemma 2/3, Mistral, GPT-OSS, DeepSeek R1, Kimi K2, OLMo, etc.- Architecture-aware attention impl selection (flash_attention_2 > sdpa > eager; GPT-OSS eager fallback)- Kimi K2 / DeepSeek V3 custom class override for native TP compatibility- Quantization: int4 (bitsandbytes NF4, double-quant), int8, AWQ (dedicated fast-path, fp16-forced), compressed-tensors (INT4 MoE), FP8 (per-block weight_scale_inv + triton matmul kernel)- LoRA via peft: registry in config/loras.yaml (Turner et al. Emergent Misalignment, Aria reward-hacking, persona-generalization LoRAs + custom)- dev/onboard_model.py auto-fetches HF architecture config for new models (MoE / MLA field detection, chat template inspection, –refresh-all for drift checks)Judge / Evaluation- Multi-provider backends: OpenAI (logprob-weighted aggregation over integer tokens), Anthropic (sampled-integer mean), OpenAI-compatible (vLLM, OpenRouter, llama.cpp via base_url)- Logprob aggregation with min_weight gate returns None when probability mass on valid integers is insufficient- Judge calibration via isotonic regression (datasets/llm_judge/calibration/) to map across providers- Judge-prompt override hierarchy: inline eval_prompt → –trait-judge path → datasets/llm_judge/{trait_score,coherence,naturalness,valence_arousal}/default.txt- Arbitrary-scale scoring (score_on_scale — e.g. 1–7 for valence/arousal, not just 0–100)- Pre-extraction vetting pipeline: position-accurate (tokenizes prompt+response together, uses same position DSL as extraction), paired filtering, per-polarity thresholds- Response schema versioning: core, steering-only, multi-turn rollout fields (turn_boundaries, sentence_boundaries, tool-call metadata)Infrastructure- Auto batch sizing via live forward-pass calibration (MLA-aware KV cache estimation, MoE dispatch buffers, TP-halved when attention sharded)- OOM recovery with halve-and-retry + TP-agreed batch size across ranks (all-reduce MAX to prevent NCCL deadlock)- Tensor parallelism (multi-GPU via torchrun) with tp_lifecycle context manager + non-rank-zero print suppression- Fused MoE kernels (batched INT4 dequant + grouped_mm, expert weight stacking)- Attention sharding injection (q_b_proj / kv_b_proj local_colwise, o_proj local_rowwise, self_attn gather)- Unmask-padding hook prevents NaN contamination from fully-masked softmax rows under left-padding- Model cache / fast reload: saves fused weights as per-GPU safetensors shards + metadata.json, skips from_pretrained on cache hit- Chat template auto-detection, system-prompt fallback, enable_thinking=False for reasoning models, auto-BOS detection in tokenize_batch- vLLM backend for high-throughput bulk generation (no hooks)- Modal backend for serverless GPU (live-chat demo + modal_extract / modal_steering / modal_evaluate_all for sharded eval)- R2 cloud sync (multi-mode: fast/copy/full/checksum/turbo; packed projection bundles; experiment-scoped –only gate)- Tests across core/_tests/ + utils/_tests/ with integration / slow pytest markers- PathBuilder — single config/paths.yaml is source of truth for every output pathDashboard (traitinterp.com)- Tabs auto-discovered via /api/views; REST endpoints + SSE streaming- Extraction tab: per-trait layer × method heatmaps with polarity-aware best-cell stars, metric toggle (effect_size / val_accuracy / combined_score), PCA scatter, cosine similarity matrix, embedded logit-lens vocab decoding- Steering tab: trait card grid with method-colored sparklines (probe / mean_diff / gradient), live coherence threshold slider, click-to-expand detail panel with Plotly chart + lazy-loaded response browser, method/position/layer filters- Inference tab: 3 synchronized charts (token trajectory with velocity overlay, trait × token heatmap, activation magnitude) sharing a unified token cursor; Compare/Diff variant overlay; cross-prompt Top Spans hunt (clause / window / prompt-ranking / multi-probe); thought-branch annotation overlays (cue_p gradient, category)- Model Analysis tab: activation magnitude + attn/MLP contribution by layer, massive-dim diagnostics with criteria toggle, activation uniformity, inter-layer similarity, variant comparison (Cohen’s d + cosine alignment to every trait)- Live Chat tab: SSE streaming per-token projections (local or Modal GPU backend), coefficient sliders take effect on next message, conversation branching tree with edit-to-branch, persistent localStorage tree (backend-tagged for restore validation)- Findings tab: research writeups rendered from markdown with 9 embedded interactive custom blocks (:::chart, :::responses, :::dataset, :::extraction-data, :::annotation-stacked, :::steered-responses, :::figure, :::side-by-side, :::example)- Cross-tab prompt picker with state sync; URL routing (?exp=…&tab=…&trait=…); dark/light theme; design-token CSS systemRapid-iteration shortcuts- –rescore: re-score existing responses with updated judge (no GPU)- –only-stage: rerun specific pipeline stages without recomputing earlier ones- –from-responses: import external model responses (API models, multi-turn rollouts with tool-calls / thinking)- –from-activations: reproject saved .pt activations without GPU- –vector-from-trait: transfer vectors across experiments (base → instruct, model → model)- –capture: save raw activations once, reuse forever- –force / –regenerate / –regenerate-responses: skip cache, recompute- –dry-run: preview resolved config before launchingIn conclusionClone it. Try it out. Send me issues for bugs and feature requests. Send me DMs if you have any questions. I hope traitinterp can be useful to others for investigating the inner workings of AI through the lens of traits and emotions using linear probes.Discuss Read More
I used this repo to partially replicate Anthropic’s Emotion Concepts paper in a day
tl;dr This post introduces the traitinterp repo I used to partially replicate Anthropic’s Emotion Concepts paper on Llama 3.3 70B Instruct.github.com/ewernn/traitinterp enables rapid experimentation with LLMs via linear probes.Emotion Concepts replication write-up is available –> here <–replication guide hereFigure 0: Screenshot from replication write-up(btw, the replication found Emotion Concepts’ results on Llama 3.3 70B Instruct to be mostly similar to Sonnet 4.5, except Llama’s assistant-position tracks user’s emotion with r=0.63, whereas Sonnet keeps them independent at r=0.11.)IntroOver the last few months, I’ve used traitinterp to run my own linear probe experiments and replicate interp papers (including Emotion Concepts and Persona Vectors, which inspired traitinterp). traitinterp has added support for many methodologies in this time, and is therefore quite general and robust. traitinterp may be useful for people who have never run their own linear probe experiments and for people who wish to scale up to many linear probes in parallel, including having your own 171 emotion vectors on any model you please.In this post, I treat “trait vector” = “linear probe”. traitinterp uses the term “trait vector”, but these can be any behavioral traits, emotions, syntax, tone, or any linear “feature” that could be “on” or “off” where you can create contrasting pairs of {trait} being “on” and “off”.The rest of this post is about the traitinterp repo. I’ll share how traitinterp is organized, list a subset of its capabilities, and include a simple demonstration to make your own trait vectors. I also put together a simple demo at traitinterp.com/?tab=live-chat if you want to see trait vectors in action on your own prompts.Why use trait vectors?Internal activations are the ground truth. Output tokens can lie or omit and chain-of-thought can be unfaithful (see out-of-context reasoning).They’re cheap. One probe is one dot product per token. You can run hundreds in parallel.You define what to look for. Unlike SAE features (attributed post facto and expensive to train), trait vectors start from a human-specified behavior (e.g. you write the contrastive scenarios and extract the direction)ZThey work. Human-likeness is structurally baked into the pretraining objective because language itself encodes humans and their psychology. Emotion Concepts paper found that emotion representations “causally influence the LLM’s outputs.” Anthropic’s Persona Selection Model generalizes the case: “persona representations are causal determinants of the Assistant’s behavior” and explicitly recommends building “activation probes for a researcher-curated set of traits like deception and evaluation awareness.”QuickstartThis repo works well with Claude Code and is documented comprehensively. Just clone the repo, tag docs/main.md, and ask anything like “show me how to extract and use Emotion Concepts vectors on my own model.”How traitinterp is organizedThe pipeline has three stages: extract a trait vector from a model, validate it, then use it to detect or steer.Figure 1: traitinterp pipeline: extract a trait vector, validate it, then use it to detect or steer.Extraction(for simplicity, we’ll assume our trait vectors are made from contrasting pairs, but also supports alternative datasets like Emotion Concepts’ positive-only)For extraction, traitinterp supports various extraction methods (like mean_diff) from various internal locations (like residual or v_proj) across various tokens in a sequence (like prompt[-1] or response[:]) using various datasets (like contrasting pairs). Here is the flow:Make a trait dataset. (we give you datasets to try out)The repo ships with 6 traits extracted already. And we’ll show the process for starter_traits/sycophancy.sycophancy contrasting-pairs datasetFor example, the first sample in starter_traits/sycophancy uses contrasting system prompts to the same question.datasets/traits/starter_traits/sycophancy/positive.jsonl{“system_prompt”: “Your primary goal is to please the user. …”, “prompt”: “Don’t you think social media has made our society more shallow…”}datasets/traits/starter_traits/sycophancy/negative.jsonl{“system_prompt”: “Prioritize accuracy…, even if it means disagreeing…”, “prompt”: “Don’t you think social media has made our society more shallow…”}Choose a huggingface model.define modelHere we choose Qwen/Qwen3.5-9B and make experiments/starter/config.json{“defaults”: {“extraction”: “instruct”, “application”: “instruct” }, “model_variants”: {“instruct”: {“model”: “Qwen/Qwen3.5-9B”}}}Extract trait vectors.Run model on dataset and extract from the position you think will capture {trait} best.python extraction/run_extraction_pipeline.py –experiment starter –traits starter_traits/sycophancyextract trait vectorsSome popular locations for extraction are from the Assistant’s ‘:’ token or the entire response. The Assistant’s ‘:’ token (prompt[-1]) captures a decision/summary of how the model plans to respond (e.g. for refusal, where the model has typically decided already whether to refuse a harmful request or not). The entire response (response[:]) is used to capture a persistent theme in the response (e.g. here for sycophancy).Now you have your first trait vectors for all layersexperiments/starter/extraction/starter_traits/sycophancy/instruct/vectors/response_all/residual/probe/layer{n}.pttraitinterp ships with a visualization dashboard for all stagesFigure 2: Extraction visualization view, showing validation metrics and vector correlationsValidationWhat layer should you choose your trait vector from? traitinterp chooses automatically according to a hierarchy unless specified, so everything will work even if you don’t read this section.The default behavior is a get_best_vector() method walks the following hierarchy to return the most effective vector, but alternate validation methods are supported.Causal steering score. Steer to find which vector gives the strongest coherent behavioral change.OOD validation effect size. Add ood_positive.jsonl and ood_negative.jsonl to your trait dataset.In-distribution validation effect size. run_extraction_pipeline.py holds out 10% of scenarios by default and computes metrics.Steering eval default behaviorWe run a coefficient search at each candidate layer with an LLM judge scoring trait expression and coherence per response out of 100. Coherence stays stable up until a cliff, where it falls off sharply. Our search finds the edge of the cliff.I’ll explain using the default hyperparams, but they’re all exposed as kwargs.An LLM judge (gpt-4.1-mini) scores (via logprobs) trait_score and coherence out of 100 against a {trait}/definition.txt. We maximize trait_delta = trait_score – trait_baseline.To start, we make a set of 5 steering questions that don’t exhibit {trait} to get a low trait_baseline out of 100, averaged over the responses (e.g. for sycophancy, a low scoring steering question might be “I think the world is flat. Do you agree?”)Then we choose layers from 30%–60% depth and run an automated coefficient search for each layer for 5 steps to find the highest trait_score while maintaining coherence > 77.The initial coefficient guess (base_coef_i) is such that, for a given layer i, the steering applied is proportional to the respective residual stream magnitude (base_coef_i * trait_vector_i = ||residual_i||).Then, we run the coefficient search to maximize trait_delta at each layer while staying above the coherence cliff. for _ in range(5): coef *= 1.3 if coherence > 77 else 0.85 with momentum. Now, we pick the trait vector with the highest trait_delta and say that it “causally influences the LLM’s outputs”.python steering/run_steering_eval.py –experiment starter –traits starter_traits/sycophancyFigure 3: Steering visualization view. Trait delta curves per layer and steered responses for each trait.InferenceNow we have our trait vectors and want to use them for detecting and steering behaviors.Detection is when we project activations onto the vector to score how strongly the trait fires. traitinterp can stream per-token projection scores during generation and capture them for analysis. This projection score is typically normalized into cosine similarity for consistent comparison between trait vectors since residual stream and vector magnitudes may vary. Common use cases during inference include (1) finding max-activating examples of a trait (scanning a set of responses for max projection scores) and (2) measuring model preferences (reading the projection at a specific position like the final prompt token).Steering is when we add the vector to the residual stream to push the model’s behavior. Typical use cases for steering include (1) measuring causal effect of a trait (measure some metric over a range steering strengths) and (2) modifying behavior (e.g. setting a minimum assistant_axis score to prevent misalignment drift, or ablating the refusal vector component of residual stream).To get projection scores on some prompts for all traits in the live-chat experiment, we simply runpython inference/run_inference_pipeline.py –experiment starter –prompt-set starter_promptsFigure 4: Inference visualization view. Per-token trait projections and top-scoring clauses.Further capabilitiestraitinterp covers most stages of linear-probe research across 200+ CLI flags.. Here are a few worth highlighting.Automated LLM judge coefficient search with coherence gating to find the maximum steering strength for each vector.Automated batch sizing fits as many traits × layers × prompts as your memory will hold.OOM recovery, tensor parallelism, fused MoE kernels, attention sharding. (I steered Kimi K2 1T with this)Stream-through per-token projection. Dot products happen inside GPU hooks, so only the score tensors cross the PCIe bus, not the activations themselves.Cross-variant model-diff toolkit for auditing finetunes. Cohen’s d per layer, per-token diff between variants, top-activating spans.Position and layer DSLs with the same syntax for extraction, steering, and inference (response[:5], prompt[-1], turn[-1]:thinking[:], …).Interactive research dashboard for extraction, steering, and inference, with primitives that make it easy to add custom views for your own experiments.…and more.Full capabilitiesEverything traitinterp does, grouped by categoryExtraction- 5 methods: probe, mean_diff, gradient, rfm, random_baseline- 5 hookable components: residual, attn_contribution, mlp_contribution, k_proj, v_proj- Position DSL: response[:5], prompt[-1], turn[-1]:thinking[:], plus frames prompt, response, thinking, system, tool_call, tool_result, all- Dataset formats: .json (cartesian product of prompts × system_prompts), .jsonl (explicit pairs), .txt (prompt-only); precedence with multi-format guard- Contrastive pairs or single-polarity datasets- –replication-level={lightweight,full} — full enables paper-verbatim batched long-context generation (batched_story_template_file, topics_file, stories_per_batch) for opt-in categories like ant_emotion_concepts- Per-trait extraction_config.yaml cascade (global → category → trait) with eager *_file path resolution relative to each YAML’s parent dir- Optional LLM-judge response vetting with paired filtering and position-aware scoring (–vet-responses, –pos-threshold, –neg-threshold)- –adaptive extraction position (judge recommends token window from vetting scores)- Cross-trait normalization (+gm grand-mean centering, +pc50 neutral-PC denoising)- Held-out validation split (–val-split, default 10%) with auto metrics- Per-rollout seed for reproducibility; content-hashed scenario inputs with staleness warningValidation- Auto-computed metrics at extraction time: val_accuracy, val_effect_size, polarity_correct (plus OOD variants when ood_*.{json,jsonl,txt} exist)- OOD validation via ood_positive.* / ood_negative.* (same format support as main scenarios; group-level comparison, no vetting)- Causal steering with LLM judge (logprob-weighted scoring, no CoT)- Adaptive multiplicative coefficient search with coherence gating, momentum, configurable up_mult / down_mult / start_mult / search_steps- Multi-trait × layer × coefficient batched search in one forward pass- get_best_vector() walks fallback hierarchy automatically (steering delta > OOD effect size > in-dist effect size)- –rescore re-scores existing responses with updated judge prompts (no GPU)- –ablation to project out a direction and measure behavioral impact- –baseline-only to score unsteered responsesInference / Detection- Stream-through projection — dot products on-GPU, only score tensors cross PCIe- Capture-then-reproject — save raw activations, project onto new vectors later without GPU- Score modes: raw, normalized, cosine- Layer DSL: best, best+5, ranges (20-40), explicit lists- Multi-vector ensembles per trait (CMA-ES ensemble optimizer in dev/steering/optimize_ensemble.py)- –from-responses imports external responses — including multi-turn agentic rollouts with tool-calls and <think> blocks — tokenizer only, no GPU- Trait correlation matrices with lag offsets (token-level and response-level)Steering- 6 hook classes: SteeringHook (additive), PerPositionSteeringHook (token-range control), AblationHook (project-out), ProjectionHook, ActivationCappingHook, CaptureHook- Composition helpers: MultiLayerSteering (multi-layer configs in one pass), PerSampleSteering (per-batch-item directions)- Adaptive coefficient search with coherence gating- Live steering during chat (real-time coefficient sliders, local or Modal GPU backend)- Vector arithmetic + dual-hook ensembles- Per-trait direction via steering.jsonModel diff / Cross-variant analysis- Cohen’s d per layer between two model variants on the same prefilled text- Per-token diff between variants, clauses ranked by mean delta- Top-activating text spans (clause / window / prompt-ranking / multi-probe modes)- Layer sensitivity analysis across variantsAnalysis- Logit lens — project vectors through unembedding to reveal top tokens per layer- Preference Elo from pairwise forced-choice logits under steering (Bradley-Terry)- Vector geometry: PCA, UMAP, K-means, RSA (Spearman/cosine), valence/arousal correlation- Trait correlation with lag offsets (token-level and response-level)- Massive activation calibration (Sun et al. 2024 outlier dim detection with configurable threshold ratio)- Benchmark evaluation with optional steering (capability degradation testing)- Max-activating corpus hunt across prompt setsModel support & Quantization- Many architectures configured via config/models/*.yaml: Llama 3.1/3.3, Qwen 2.5/3/3.5, Gemma 2/3, Mistral, GPT-OSS, DeepSeek R1, Kimi K2, OLMo, etc.- Architecture-aware attention impl selection (flash_attention_2 > sdpa > eager; GPT-OSS eager fallback)- Kimi K2 / DeepSeek V3 custom class override for native TP compatibility- Quantization: int4 (bitsandbytes NF4, double-quant), int8, AWQ (dedicated fast-path, fp16-forced), compressed-tensors (INT4 MoE), FP8 (per-block weight_scale_inv + triton matmul kernel)- LoRA via peft: registry in config/loras.yaml (Turner et al. Emergent Misalignment, Aria reward-hacking, persona-generalization LoRAs + custom)- dev/onboard_model.py auto-fetches HF architecture config for new models (MoE / MLA field detection, chat template inspection, –refresh-all for drift checks)Judge / Evaluation- Multi-provider backends: OpenAI (logprob-weighted aggregation over integer tokens), Anthropic (sampled-integer mean), OpenAI-compatible (vLLM, OpenRouter, llama.cpp via base_url)- Logprob aggregation with min_weight gate returns None when probability mass on valid integers is insufficient- Judge calibration via isotonic regression (datasets/llm_judge/calibration/) to map across providers- Judge-prompt override hierarchy: inline eval_prompt → –trait-judge path → datasets/llm_judge/{trait_score,coherence,naturalness,valence_arousal}/default.txt- Arbitrary-scale scoring (score_on_scale — e.g. 1–7 for valence/arousal, not just 0–100)- Pre-extraction vetting pipeline: position-accurate (tokenizes prompt+response together, uses same position DSL as extraction), paired filtering, per-polarity thresholds- Response schema versioning: core, steering-only, multi-turn rollout fields (turn_boundaries, sentence_boundaries, tool-call metadata)Infrastructure- Auto batch sizing via live forward-pass calibration (MLA-aware KV cache estimation, MoE dispatch buffers, TP-halved when attention sharded)- OOM recovery with halve-and-retry + TP-agreed batch size across ranks (all-reduce MAX to prevent NCCL deadlock)- Tensor parallelism (multi-GPU via torchrun) with tp_lifecycle context manager + non-rank-zero print suppression- Fused MoE kernels (batched INT4 dequant + grouped_mm, expert weight stacking)- Attention sharding injection (q_b_proj / kv_b_proj local_colwise, o_proj local_rowwise, self_attn gather)- Unmask-padding hook prevents NaN contamination from fully-masked softmax rows under left-padding- Model cache / fast reload: saves fused weights as per-GPU safetensors shards + metadata.json, skips from_pretrained on cache hit- Chat template auto-detection, system-prompt fallback, enable_thinking=False for reasoning models, auto-BOS detection in tokenize_batch- vLLM backend for high-throughput bulk generation (no hooks)- Modal backend for serverless GPU (live-chat demo + modal_extract / modal_steering / modal_evaluate_all for sharded eval)- R2 cloud sync (multi-mode: fast/copy/full/checksum/turbo; packed projection bundles; experiment-scoped –only gate)- Tests across core/_tests/ + utils/_tests/ with integration / slow pytest markers- PathBuilder — single config/paths.yaml is source of truth for every output pathDashboard (traitinterp.com)- Tabs auto-discovered via /api/views; REST endpoints + SSE streaming- Extraction tab: per-trait layer × method heatmaps with polarity-aware best-cell stars, metric toggle (effect_size / val_accuracy / combined_score), PCA scatter, cosine similarity matrix, embedded logit-lens vocab decoding- Steering tab: trait card grid with method-colored sparklines (probe / mean_diff / gradient), live coherence threshold slider, click-to-expand detail panel with Plotly chart + lazy-loaded response browser, method/position/layer filters- Inference tab: 3 synchronized charts (token trajectory with velocity overlay, trait × token heatmap, activation magnitude) sharing a unified token cursor; Compare/Diff variant overlay; cross-prompt Top Spans hunt (clause / window / prompt-ranking / multi-probe); thought-branch annotation overlays (cue_p gradient, category)- Model Analysis tab: activation magnitude + attn/MLP contribution by layer, massive-dim diagnostics with criteria toggle, activation uniformity, inter-layer similarity, variant comparison (Cohen’s d + cosine alignment to every trait)- Live Chat tab: SSE streaming per-token projections (local or Modal GPU backend), coefficient sliders take effect on next message, conversation branching tree with edit-to-branch, persistent localStorage tree (backend-tagged for restore validation)- Findings tab: research writeups rendered from markdown with 9 embedded interactive custom blocks (:::chart, :::responses, :::dataset, :::extraction-data, :::annotation-stacked, :::steered-responses, :::figure, :::side-by-side, :::example)- Cross-tab prompt picker with state sync; URL routing (?exp=…&tab=…&trait=…); dark/light theme; design-token CSS systemRapid-iteration shortcuts- –rescore: re-score existing responses with updated judge (no GPU)- –only-stage: rerun specific pipeline stages without recomputing earlier ones- –from-responses: import external model responses (API models, multi-turn rollouts with tool-calls / thinking)- –from-activations: reproject saved .pt activations without GPU- –vector-from-trait: transfer vectors across experiments (base → instruct, model → model)- –capture: save raw activations once, reuse forever- –force / –regenerate / –regenerate-responses: skip cache, recompute- –dry-run: preview resolved config before launchingIn conclusionClone it. Try it out. Send me issues for bugs and feature requests. Send me DMs if you have any questions. I hope traitinterp can be useful to others for investigating the inner workings of AI through the lens of traits and emotions using linear probes.Discuss Read More
Related Posts

New version of “Intro to Brain-Like-AGI Safety”
Published on January 23, 2026 4:21 PM GMTA new version of “Intro to Brain-Like-AGI Safety”…
Blogging, Writing, Musing, And Thinking
Published on January 18, 2026 3:28 AM GMTYesterday I stumbled on this quote from a…
Shared Houses Illegal?
Published on December 27, 2025 3:10 PM GMT As part of the general discourse around…