Fine-tuning large language models (LLMs) with backpropagation — even for a subset of parameters such as LoRA — can be much more memory-consuming than inference and is often deemed impractical for resource-constrained mobile devices. Alternative methods, such as zeroth-order optimization (ZO), can greatly reduce the memory footprint but come at the cost of significantly slower model convergence (10× to 100× more steps than backpropagation). We propose a memory-efficient implementation of backpropagation (MeBP) on mobile devices that provides better trade-off between memory usage and compute… Read More
Memory-Efficient Backpropagation for Fine-Tuning LLMs on Resource-Constrained Mobile Devices
Fine-tuning large language models (LLMs) with backpropagation — even for a subset of parameters such as LoRA — can be much more memory-consuming than inference and is often deemed impractical for resource-constrained mobile devices. Alternative methods, such as zeroth-order optimization (ZO), can greatly reduce the memory footprint but come at the cost of significantly slower model convergence (10× to 100× more steps than backpropagation). We propose a memory-efficient implementation of backpropagation (MeBP) on mobile devices that provides better trade-off between memory usage and compute…

Related Posts
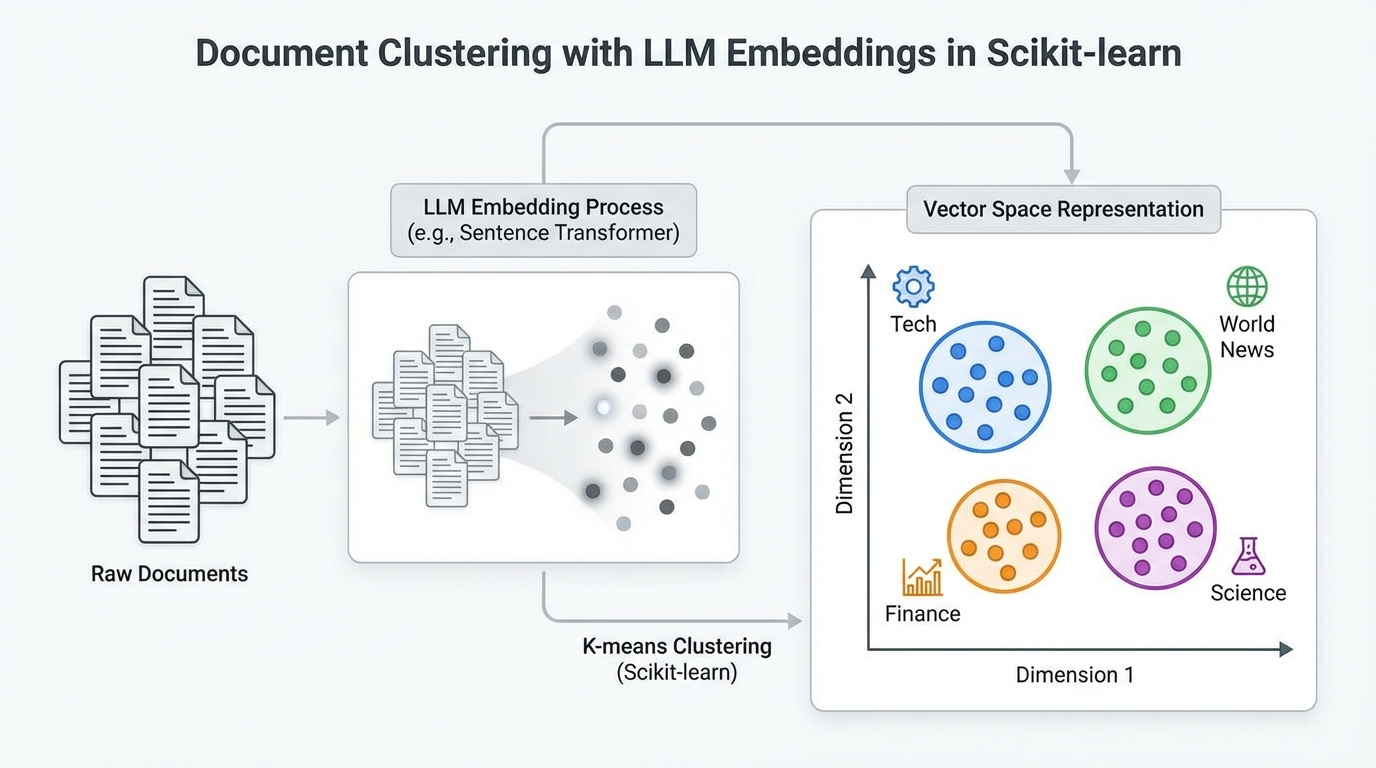
Document Clustering with LLM Embeddings in Scikit-learn
Imagine that you suddenly obtain a large collection of unclassified documents and are tasked with…
Gemini Enterprise: The new front door for Google AI in your workplace
True business transformation in the era of AI must go beyond simple chatbots. That’s what…