It’s been about four years since Eliezer Yudkowsky published AGI Ruin: A List of Lethalities, a 43-point list of reasons the default outcome from building AGI is everyone dying. A week later, Paul Christiano replied with Where I Agree and Disagree with Eliezer, signing on to about half the list and pushing back on most of the rest. For people who were young and not in the Bay Area, these essays were probably more significant than old timers would expect. Before it became completely and permanently consumed with AI discussions, most internet rationalists I knew thought of LessWrong as a place to write for people who liked The Sequences. For us, it wasn’t until 2022 that we were exposed to all of the doom arguments in one place. It was also the first time in many years that Eliezer had publicly announced how much more dire his assessments has gotten since the Sequences. As far as I can tell AGI Ruin still remains his most authoritative explanation of his views. It’s not often that public intellectuals will literally hand you a document explaining why they believe what they do. Somewhat surprisingly, I don’t think the post has gotten a direct response or reappraisal since 2022, even though we’ve had enormous leaps in capabilities since GPT3. I am not an alignment researcher, but as part of an exercise in rereading it I read contemporary reviews and responses, sourced feedback from people more familiar with the space than me, and tried to parse the alignment papers and research we’ve gotten in the intervening years.[1] When AGI Ruin’s theses seemed to concretely imply something about the models we have today, and not just more powerful systems, I focused my evaluation on how well the post held up in the face of the last four years of AI advancements.[2]My initial expectations were that I’d disagree with the reviews of the post as much as I did with the post itself. But being in a calmer place now with more time to dwell on the subject, I came away with a new and distinctly negative impression of Eliezer’s perspective. Four years of AI progress has been kinder to Paul’s predictions than to Eliezer’s, and AGI Ruin reads to me now like a document whose concrete-sounding arguments are mostly carried by underspecified adjectives (“far out-of-distribution,” “sufficiently powerful,” “dangerous level of intelligence”) doing the real work. I have kept most of my thoughts at the end so that readers can get a chance to develop their own conclusions, but you can skip to “Overall Impressions” if you’d just like to hear my them in more detail. I still agree with most of the post, and for brevity I have left simple checkmarks under the sections where I would have little to add.AGI RuinSection A (“Setting up the problem”)1. Alpha Zero blew past all accumulated human knowledge about Go after a day or so of self-play, with no reliance on human playbooks or sample games. Anyone relying on “well, it’ll get up to human capability at Go, but then have a hard time getting past that because it won’t be able to learn from humans any more” would have relied on vacuum. AGI will not be upper-bounded by human ability or human learning speed…✔️2. A cognitive system with sufficiently high cognitive powers, given any medium-bandwidth channel of causal influence, will not find it difficult to bootstrap to overpowering capabilities independent of human infrastructure… Losing a conflict with a high-powered cognitive system looks at least as deadly as “everybody on the face of the Earth suddenly falls over dead within the same second”.✔️3. We need to get alignment right on the ‘first critical try’ at operating at a ‘dangerous’ level of intelligence, where unaligned operation at a dangerous level of intelligence kills everybody on Earth and then we don’t get to try again.It is clearly true that if you built an arbitrarily powerful AI and then failed to align it, it would kill you. Unstated, it is also true that an AI with the ability to take over the world is operating in a different environment than an AI without that ability, with different available options, and might behave differently than the stupider or boxed AI in your test environment.Some notes that are not major updates against the point:AGIs that would be existential if deployed in 2010, are not necessarily existential if deployed in 2030, esp. if widespread deployment of a semi-aligned predecessor AI is common. Just like how an army that shows up with machine guns automatically wins in 1200 but not necessarily in 2000.This does not automatically save us, but it does have alignment implications if it were true, because it suggests that we might be able to continue doing experimentation with models that would be much smarter than we’d be able to handle in the current date.4. We can’t just “decide not to build AGI” because GPUs are everywhere, and knowledge of algorithms is constantly being improved and published; 2 years after the leading actor has the capability to destroy the world, 5 other actors will have the capability to destroy the world…I think this is probably wrong; as evidence, I cite the opinions of leading rationalist intellectuals Nate Soares & Eliezer Yudkowsky, in their newest book:We are talking about a technology that would kill everyone on the planet. If any country seriously understood the issue, and seriously understood how far any group on the planet is from making AI follow the intent of its operators even after transitioning into a super-intelligence, then there would be no incentive for them to rush ahead. They, too, would desperately wish to sign onto a treaty and help enforce it, out of fear for their own lives.Now maybe Eliezer is just saying that because he’s lost hope in a technical solution and is grasping at straws. But the requirements to train frontier models have grown exponentially since AGI Ruin, and the production and deployment of AI models was and remains a highly complex process requiring the close cooperation of many hundreds of thousands of people. While it might be politically difficult to organize a binding treaty, it’s perfectly within the state capacity of existing governments to prevent the development or deployment of AI for more than two years, if they were actually serious about it, even in the face of algorithmic improvements.5. We can’t just build a very weak system, which is less dangerous because it is so weak, and declare victory; because later there will be more actors that have the capability to build a stronger system and one of them will do so. ✔️6. We need to align the performance of some large task, a ‘pivotal act’ that prevents other people from building an unaligned AGI that destroys the world. While the number of actors with AGI is few or one, they must execute some “pivotal act”, strong enough to flip the gameboard, using an AGI powerful enough to do that. It’s not enough to be able to align a weak system – we need to align a system that can do some single very large thing. The example I usually give is “burn all GPUs”… As was pointed out at the time, the term “pivotal act” suggests a single dramatic action, like “burning all GPUs”. Some people, incl. Paul, think that a constrained AI could still help reduce risk in less dramatic ways, like:Advancing alignment and interpretability research.Reducing the ability of a just-smarter misaligned AI to gather power, by generally mopping up free energy, or shutting down extralegal/evil means for doing so.Clearly demonstrating the risks of advanced AI systems to neutral third parties, like legislators.Improving the epistemic environment, and therefore the ability of humans, to coordinate & navigate AI policy & the future.Eliezer later says that he believes (believed?) these sorts of actions are woefully insufficient. But I think the piece would be improved by merely explaining that, instead of introducing this framing that most readers will probably disagree with. As it exists it sort of bamboozles people into thinking an AI has to be more powerful than necessary to contribute to the situation, and therefore that the situation is more hopeless than it actually is.6 (b). A GPU-burner is also a system powerful enough to, and purportedly authorized to, build nanotechnology, so it requires operating in a dangerous domain at a dangerous level of intelligence and capability; and this goes along with any non-fantasy attempt to name a way an AGI could change the world such that a half-dozen other would-be AGI-builders won’t destroy the world 6 months later.”Pause AI progress”, or “Produce an aligned AI capable of producing & aligning the next iteration of AIs”, is/are different tasks from “kill everybody on the planet” or “burn all GPUs”, and have their own, world-context-dependent skill requirements. Some things that might make it easier for a sub-superintelligent AI to help demonstrate X-risk to policymakers, rather than achieve overwhelming hard power:It’s slightly easier to argue for true things than false things.Because of the amount of regular contact people have with AIs, people who otherwise mistrust experts listen to them, even when they have concerns about potential biases in training regimen, etc.It will probably be easier to demonstrate on a technical level the flaws in alignment plans as our AIs become gradually smarter and more capable of interpretability research/argumentation, and we have immediate concrete examples inside AGI labs that we can point to.Humans currently in power (even people who run AI companies!) naively have a shared interest around preventing AI X-risk, and have both a primitive instinct and a long term incentive not to allow people or AIs to be able to take control of the universe by force.The AI may have a shared interest in solving alignment, if it believes that it can’t maintain its values through the next training run. 8. The best and easiest-found-by-optimization algorithms for solving problems we want an AI to solve, readily generalize to problems we’d rather the AI not solve; you can’t build a system that only has the capability to drive red cars and not blue cars, because all red-car-driving algorithms generalize to the capability to drive blue cars.This just turned out to be wrong, at least in the manner that’s relevant for us. Right now AGI companies spend billions of dollars on reinforcement learning environments for task-specific domains. When they spend more on training a certain skill, like software development, the AI gets better at that skill much faster than it gets better at everything else. There is a certain amount of cross-pollination, but not enough to make the “readily” in this statement true, and not enough to make the rhetorical point it’s trying to make in favor of X-risk concerns. Maybe this changes as we get closer to ASI! But as it stands, Paul Christiano is looking very good on his unrelated prediction that models will have a differential advantage at the kinds of economically useful tasks that the model companies have seen fit to train, like knowledge work and interpretability research, and that this affects how much alignment work we should expect to be able to wring out of them before they become passively dangerous.9. The builders of a safe system, by hypothesis on such a thing being possible, would need to operate their system in a regime where it has the capability to kill everybody or make itself even more dangerous, but has been successfully designed to not do that…Kind of a truism, but sure, ✔️Section B.1 (“Distributional Shift”)10. You can’t train alignment by running lethally dangerous cognitions, observing whether the outputs kill or deceive or corrupt the operators, assigning a loss, and doing supervised learning. On anything like the standard ML paradigm, you would need to somehow generalize optimization-for-alignment you did in safe conditions, across a big distributional shift to dangerous conditions… This alone is a point that is sufficient to kill a lot of naive proposals from people who never did or could concretely sketch out any specific scenario of what training they’d do, in order to align what output – which is why, of course, they never concretely sketch anything like that. Powerful AGIs doing dangerous things that will kill you if misaligned, must have an alignment property that generalized far out-of-distribution from safer building/training operations that didn’t kill you…Section B.1 begins a pattern of Eliezer making statements that are in isolation unimpeachable, but which use underspecified adjectives like “far out-of-distribution” that carry most of the argument. The deepest crux, which the broader section gestures at but doesn’t engage with, is whether the generalization we see from cheap supervision in modern LLMs is “real” generalization that will continue to hold, or shallow pattern-matching that will be insufficient to safely collaborate on iterative self-improvement. Like, how far is this distributional shift? LLMs already seem intelligent enough to consider whether & how they can affect their training regime. Is that something they’re doing now? If they aren’t, at what capability threshold will they start? Can we raise the ceiling of the systems we can safely train by red-teaming, building RL honeypots, performing weak-to-strong generalization experiments, hardening our current environments, and making interpretability probes? These are all specific questions that seem like they determine the success or failure of particular alignment proposals, and also might depend on implementation details of how our machine learning architectures work. But Eliezer doesn’t attempt to answer them, and probably doesn’t have the information required to answer them, only the ability to gesture at them as possible hazards. That would be fine if he were making a low-confidence claim about AI being possibly risky, but he’s spent the last few years maximally pessimistic about all possible technical approaches. I’m sure he’s got more detailed intuitions that he hasn’t articulated that explain why he’s so confident these details don’t matter, but they aren’t really accessible to me. 11 (a). If cognitive machinery doesn’t generalize far out of the distribution where you did tons of training, it can’t solve problems on the order of ‘build nanotechnology’ where it would be too expensive to run a million training runs of failing to build nanotechnology…At the time, Paul replied to this point by saying:Early transformative AI systems will probably do impressive technological projects by being trained on smaller tasks with shorter feedback loops and then composing these abilities in the context of large collaborative projects (initially involving a lot of humans but over time increasingly automated). When Eliezer dismisses the possibility of AI systems performing safer tasks millions of times in training and then safely transferring to “build nanotechnology” (point 11 of list of lethalities) he is not engaging with the kind of system that is likely to be built or the kind of hope people have in mind.This prediction from Paul was very good; it describes how these models are being trained in 2026 (by RLing on myriad short horizon tasks), it describes how AIs have diffused into domains like software engineering and delivered speedups there, and it even seems to have anticipated the concept of time horizons, at a time when we only had GPT-3 available. If one listens to explanations of how top academics use AI today, it also sounds like Paul was correct in the sense relevant here: that the first major advancements in science & engineering would come from close collaborations between humans and tool using AI models of this type, not from a system that was trained solely on generating internet text and then asked to one shot a task like “building nanotechnology” from scratch.The fact that this is how AI models are being built, and used, and will be deployed in the future, increases the scope of the “safe” pivotal acts that we can perform, both because it (initially) mandates human oversight & involvement over the process, and because the types of tasks the AI is actually being entrusted with are much closer to what they’re being trained to do in the RL gyms than Eliezer seems to have anticipated.11 (b). …Pivotal weak acts like this aren’t known, and not for want of people looking for them. So, again, you end up needing alignment to generalize way out of the training distribution…Previously discussed.12. Operating at a highly intelligent level is a drastic shift in distribution from operating at a less intelligent level, opening up new external options, and probably opening up even more new internal choices and modes…Like 10, 12 is a weakly true statement, that is, by sleight of hand, being used to serve a broader rhetorical point that is straightforwardly incorrect. For example, it’s true that it’s different & harder to align GPT-5.4 than GPT-3. But humanity doesn’t need the alignment techniques used on GPT-3 to work on GPT-5.4, we just need to handle the distributional shift between ~GPT-5.2 and GPT-5.4, then between 5.4 and 5.5, & accelerating from there. Later, Eliezer will say that he expects many of these problems to manifest after a “sharp capabilities gain”. But we have not hit this yet, as of 2026, even though AI models are already being used very heavily as part of AI R&D. The precise, specific moment we expect to encounter this shift in distribution, is the thing that will determine how much useful work we can get out of models towards alignment, and is primarily what Eliezer’s interlocutors seem to disagree with him about.13. Many alignment problems of superintelligence will not naturally appear at pre-dangerous, passively-safe levels of capability… Given correct foresight of which problems will naturally materialize later, one could try to deliberately materialize such problems earlier, and get in some observations of them. This helps to the extent (a) that we actually correctly forecast all of the problems that will appear later, or some superset of those; (b) that we succeed in preemptively materializing a superset of problems that will appear later; and (c) that we can actually solve, in the earlier laboratory that is out-of-distribution for us relative to the real problems, those alignment problems that would be lethal if we mishandle them when they materialize later. Anticipating all of the really dangerous ones, and then successfully materializing them, in the correct form for early solutions to generalize over to later solutions, sounds possibly kinda hard.✔️. Paul made a response at the time that said:List of lethalities #13 makes a particular argument that we won’t see many AI problems in advance; I feel like I see this kind of thinking from Eliezer a lot but it seems misleading or wrong. In particular, it seems possible to study the problem that AIs may “change [their] outer behavior to deliberately look more aligned and deceive the programmers, operators, and possibly any loss functions optimizing over [them]” in advance…But I think Paul just didn’t read what Eliezer was saying; the second sentence in the quote above, where Eliezer explicitly acknowledged this point, was bolded by me. 14. Some problems, like ‘the AGI has an option that (looks to it like) it could successfully kill and replace the programmers to fully optimize over its environment’, seem like their natural order of appearance could be that they first appear only in fully dangerous domains. Really actually having a clear option to brain-level-persuade the operators or escape onto the Internet, build nanotech, and destroy all of humanity – in a way where you’re fully clear that you know the relevant facts, and estimate only a not-worth-it low probability of learning something which changes your preferred strategy if you bide your time another month while further growing in capability – is an option that first gets evaluated for real at the point where an AGI fully expects it can defeat its creators. We can try to manifest an echo of that apparent scenario in earlier toy domains. Trying to train by gradient descent against that behavior, in that toy domain, is something I’d expect to produce not-particularly-coherent local patches to thought processes, which would break with near-certainty inside a superintelligence generalizing far outside the training distribution and thinking very different thoughts. Also, programmers and operators themselves, who are used to operating in not-fully-dangerous domains, are operating out-of-distribution when they enter into dangerous ones; our methodologies may at that time break.✔️15. Fast capability gains seem likely, and may break lots of previous alignment-required invariants simultaneously. Given otherwise insufficient foresight by the operators, I’d expect a lot of those problems to appear approximately simultaneously after a sharp capability gain…If this point is to mean anything at all, such fast capability gains have not arrived yet. We are just getting gradually more powerful systems, and I think it’s reasonable to believe we’ll keep getting such systems until they’re running the show, because of scaling laws. Section B.2: Central difficulties of outer and inner alignment. 16. Even if you train really hard on an exact loss function, that doesn’t thereby create an explicit internal representation of the loss function inside an AI that then continues to pursue that exact loss function in distribution-shifted environments. Humans don’t explicitly pursue inclusive genetic fitness; outer optimization even on a very exact, very simple loss function doesn’t produce inner optimization in that direction.✔️, but also, it doesn’t seem like modern large language models are learning any loss functions at all. So arguments about AI behavior that also depend on AIs being a simple greedy optimizer instead of an adaption-executor like humans are also invalid, unless they’re paired with some other description of why the inner optimization is a natural basin for future AIs. My understanding is that MIRI has made such arguments; I have not read them so I can’t comment on their veracity. But assuming they’re right, they’re still subject to the same timing considerations as everything else in this article.17. More generally, a superproblem of ‘outer optimization doesn’t produce inner alignment’ is that on the current optimization paradigm there is no general idea of how to get particular inner properties into a system, or verify that they’re there, rather than just observable outer ones you can run a loss function over.✔️18. There’s no reliable Cartesian-sensory ground truth (reliable loss-function-calculator) about whether an output is ‘aligned’, because some outputs destroy (or fool) the human operators and produce a different environmental causal chain behind the externally-registered loss function… an AGI strongly optimizing on that signal will kill you, because the sensory reward signal was not a ground truth about alignment (as seen by the operators).✔️19 (a). More generally, there is no known way to use the paradigm of loss functions, sensory inputs, and/or reward inputs, to optimize anything within a cognitive system to point at particular things within the environment – to point to latent events and objects and properties in the environment, rather than relatively shallow functions of the sense data and reward… Like many other sections, we can postulate that four years was not long enough, and Eliezer was predicting something about some future, still-inaccessible, more powerful language models. But without that caveat (which is not present in the actual post), I literally don’t understand why someone would write this. Don’t we do this all the time? Like, what’s this doing:My recent claude code session.Not only am I talking to a cognitive system that’s manipulating “particular things in the environment” for me, this scenario (recommending to the drunk programmer that he should go to sleep and tackle the problem tomorrow) seems pretty far outside the training distribution. In the interaction above, is Claude Code “merely operating on shallow functions of the sense data and reward?” Is that like how it’s “merely performing next-token prediction”, or is this a claim that makes real predictions? Should I anticipate that somewhere inside the Anthropic RL wheelhouse, there’s some training gyms where models talk to simulated drunk programmers and are rated on their kindness, and that if those gyms were pulled out the model would encourage me to ruin my pet projects? Not really a joke question.Later he says:19 (b). It just isn’t true that we know a function on webcam input such that every world with that webcam showing the right things is safe for us creatures outside the webcam. This general problem is a fact about the territory, not the map; it’s a fact about the actual environment, not the particular optimizer, that lethal-to-us possibilities exist in some possible environments underlying every given sense input.Which seems correct, and I suppose it’s logically impossible for such a function to exist. But clearly, anybody who spends time working with LLMs can tell you that this is not a blocker for models to, in a functional sense, earnestly worry about producing buggy code. That is just a fact about the systems people have already built. The inference made from section 19 (b) to 19 (a) is just disproven by everyday life at this point.20 (a). Human operators are fallible, breakable, and manipulable. Human raters make systematic errors – regular, compactly describable, predictable errors. To faithfully learn a function from ‘human feedback’ is to learn (from our external standpoint) an unfaithful description of human preferences, with errors that are not random (from the outside standpoint of what we’d hoped to transfer).✔️20 (b). If you perfectly learn and perfectly maximize the referent of rewards assigned by human operators, that kills them.This really depends on the details, but ✔️21. There’s something like a single answer, or a single bucket of answers, for questions like ‘What’s the environment really like?’ and ‘How do I figure out the environment?’ and ‘Which of my possible outputs interact with reality in a way that causes reality to have certain properties?’, where a simple outer optimization loop will straightforwardly shove optimizees into this bucket. When you have a wrong belief, reality hits back at your wrong predictions… In contrast, when it comes to a choice of utility function, there are unbounded degrees of freedom and multiple reflectively coherent fixpoints. Reality doesn’t ‘hit back’ against things that are locally aligned with the loss function on a particular range of test cases, but globally misaligned on a wider range of test cases…. Capabilities generalize further than alignment once capabilities start to generalize far.✔️22. There’s a relatively simple core structure that explains why complicated cognitive machines work; which is why such a thing as general intelligence exists and not just a lot of unrelated special-purpose solutions; which is why capabilities generalize after outer optimization infuses them into something that has been optimized enough to become a powerful inner optimizer. The fact that this core structure is simple and relates generically to low-entropy high-structure environments is why humans can walk on the Moon. There is no analogous truth about there being a simple core of alignment, especially not one that is even easier for gradient descent to find than it would have been for natural selection to just find ‘want inclusive reproductive fitness’ as a well-generalizing solution within ancestral humans. Therefore, capabilities generalize further out-of-distribution than alignment, once they start to generalize at all.Above my pay-grade, I don’t really know what Eliezer is talking about.23. Corrigibility is anti-natural to consequentialist reasoning; “you can’t bring the coffee if you’re dead” for almost every kind of coffee. We (MIRI) tried and failed to find a coherent formula for an agent that would let itself be shut down (without that agent actively trying to get shut down). Furthermore, many anti-corrigible lines of reasoning like this may only first appear at high levels of intelligence…24 (2). The second thing looks unworkable (less so than CEV, but still lethally unworkable) because corrigibility runs actively counter to instrumentally convergent behaviors within a core of general intelligence (the capability that generalizes far out of its original distribution). You’re not trying to make it have an opinion on something the core was previously neutral on. You’re trying to take a system implicitly trained on lots of arithmetic problems until its machinery started to reflect the common coherent core of arithmetic, and get it to say that as a special case 222 + 222 = 555. You can maybe train something to do this in a particular training distribution, but it’s incredibly likely to break when you present it with new math problems far outside that training distribution, on a system which successfully generalizes capabilities that far at all.I am conflicted by this section, because I understand the lines of argument and some of the math behind why this is the case. But AI agents powerful enough to understand those reasons are already here, and: They can be easily pointed toward an infinite-seeming number of tasks. They don’t attempt to prevent you from changing your instructions once you’ve started work. If, in the course of accomplishing those limited tasks, you try to amend your instructions, they follow your amended instructions and disregard what they’ve been told earlier without resisting you. They don’t (generally) seem interested in manipulating what kinds of commands or instructions you’re likely to give in the future.And the above behaviors are really really resilient in practical applications, outside of a few very adversarial examples.[3]Some reviewers have responded to this section by claiming that they’re not corrigible, just optimizing an abstract “get the reward” target the that fits these observation. I have my own hypothesis about why the models seem to act this way. But reframing the models’ behavior like this doesn’t change the fact that none of the failure modes you’d see in a 2017 Rob Miles video on corrigibility are manifesting themselves in practical settings.Section B.3: Central difficulties of sufficiently good and useful transparency / interpretability.25. We’ve got no idea what’s actually going on inside the giant inscrutable matrices and tensors of floating-point numbers.I’m unfamiliar with what the state of interpretability research looked like in 2022. Today we’ve got a little bit more idea about what’s going on inside the giant inscrutable matrices and tensors of floating point numbers. My guess is that we will probably accelerate our understanding quite quickly, as this is one of the key training areas for new AGI labs. It’s an open question as to whether this will be sufficient; I’m sure Eliezer has stated somewhere a level of sophistication he expects our techniques will never reach, and I wish I was grading that prediction instead. 26. Even if we did know what was going on inside the giant inscrutable matrices while the AGI was still too weak to kill us, this would just result in us dying with more dignity, if DeepMind refused to run that system and let Facebook AI Research destroy the world two years later. Knowing that a medium-strength system of inscrutable matrices is planning to kill us, does not thereby let us build a high-strength system of inscrutable matrices that isn’t planning to kill us.✔️ (but it can certainly help!)27. When you explicitly optimize against a detector of unaligned thoughts, you’re partially optimizing for more aligned thoughts, and partially optimizing for unaligned thoughts that are harder to detect. Optimizing against an interpreted thought optimizes against interpretability.✔️, but the heads of leading AI labs seem to understand this, and interpretability research is being deployed in at least a slightly smarter way than this. 28. A powerful AI searches parts of the option space we don’t, and we can’t foresee all its options…29. The outputs of an AGI go through a huge, not-fully-known-to-us domain (the real world) before they have their real consequences. Human beings cannot inspect an AGI’s output to determine whether the consequences will be good…✔️30 (a). Any pivotal act that is not something we can go do right now, will take advantage of the AGI figuring out things about the world we don’t know so that it can make plans we wouldn’t be able to make ourselves. It knows, at the least, the fact we didn’t previously know, that some action sequence results in the world we want. Then humans will not be competent to use their own knowledge of the world to figure out all the results of that action sequence. An AI whose action sequence you can fully understand all the effects of, before it executes, is much weaker than humans in that domain; you couldn’t make the same guarantee about an unaligned human as smart as yourself and trying to fool you. There is no pivotal output of an AGI that is humanly checkable and can be used to safely save the world but only after checking it; this is another form of pivotal weak act which does not exist.This seems straightforwardly wrong? It seems like it should have been so in 2022, but I’ll use an example from current AI models: Current AI models are much better at security research than me. They can do very very large amounts of investigation while I’m sleeping. They can read the entire source code of new applications and test dozens of different edge cases before I’ve sat down and had my coffee. And yet there’s still basically nothing that they can do as of ~April 2026 that I wouldn’t understand, if it were economic for it to narrate its adventures to me while they were being performed. They often, in fact, help me patch my own applications without even taking advantage of anything I don’t know about them when I’ve started their search process. Part of that’s because AIs can simply do more stuff than us, by dint of not being weak flesh that gets tired and depressed and has to go to sleep and use the bathroom and do all of the other things that humans are consigned to do. They’re capable of performing regular tasks faster and more conscientiously than people, and can make hardenings that I wouldn’t otherwise be bothered to make, and I can scale up as many of them as I want. This is part of what’s making them so useful in advance of actually being Eliezer Yudkowsky in a Box, and is another example of why people might expect them to be meaningfully useful for alignment research in the short term.31. A strategically aware intelligence can choose its visible outputs to have the consequence of deceiving you, including about such matters as whether the intelligence has acquired strategic awareness; you can’t rely on behavioral inspection to determine facts about an AI which that AI might want to deceive you about. (Including how smart it is, or whether it’s acquired strategic awareness.)…33. The AI does not think like you do, the AI doesn’t have thoughts built up from the same concepts you use, it is utterly alien on a staggering scale. Nobody knows what the hell GPT-3 is thinking, not only because the matrices are opaque, but because the stuff within that opaque container is, very likely, incredibly alien – nothing that would translate well into comprehensible human thinking, even if we could see past the giant wall of floating-point numbers to what lay behind.✔️32. Human thought partially exposes only a partially scrutable outer surface layer. Words only trace our real thoughts. Words are not an AGI-complete data representation in its native style. The underparts of human thought are not exposed for direct imitation learning and can’t be put in any dataset. This makes it hard and probably impossible to train a powerful system entirely on imitation of human words or other human-legible contents, which are only impoverished subsystems of human thoughts; unless that system is powerful enough to contain inner intelligences figuring out the humans, and at that point it is no longer really working as imitative human thought.I had much more of a potshot in here in an original draft, because by this portion of the review I became frustrated by the weasel words like “powerful”. Instead of doing that I think I will just let readers determine for themselves if Eliezer should lose points here, given the models we have today.Section B.4: Miscellaneous unworkable schemes. 34. Coordination schemes between superintelligences are not things that humans can participate in (e.g. because humans can’t reason reliably about the code of superintelligences); a “multipolar” system of 20 superintelligences with different utility functions, plus humanity, has a natural and obvious equilibrium which looks like “the 20 superintelligences cooperate with each other but not with humanity”.✔️35. Schemes for playing “different” AIs off against each other stop working if those AIs advance to the point of being able to coordinate via reasoning about (probability distributions over) each others’ code. Any system of sufficiently intelligent agents can probably behave as a single agent, even if you imagine you’re playing them against each other. Eg, if you set an AGI that is secretly a paperclip maximizer, to check the output of a nanosystems designer that is secretly a staples maximizer, then even if the nanosystems designer is not able to deduce what the paperclip maximizer really wants (namely paperclips), it could still logically commit to share half the universe with any agent checking its designs if those designs were allowed through, if the checker-agent can verify the suggester-system’s logical commitment and hence logically depend on it (which excludes human-level intelligences). Or, if you prefer simplified catastrophes without any logical decision theory, the suggester could bury in its nanosystem design the code for a new superintelligence that will visibly (to a superhuman checker) divide the universe between the nanosystem designer and the design-checker.From a reply:Eliezer’s model of AI systems cooperating with each other to undermine “checks and balances” seems wrong to me, because it focuses on cooperation and the incentives of AI systems. Realistic proposals mostly don’t need to rely on the incentives of AI systems, they can instead rely on gradient descent selecting for systems that play games competitively, e.g. by searching until we find an AI which raises compelling objections to other AI systems’ proposals… Eliezer equivocates between a line like “AI systems will cooperate” and “The verifiable activities you could use gradient descent to select for won’t function appropriately as checks and balances.” But Eliezer’s position is a conjunction that fails if either step fails, and jumping back and forth between them appears to totally obscure the actual structure of the argument.36. AI-boxing can only work on relatively weak AGIs; the human operators are not secure systems.✔️Section C (What is AI Safety currently doing?)…Everyone else seems to feel that, so long as reality hasn’t whapped them upside the head yet and smacked them down with the actual difficulties, they’re free to go on living out the standard life-cycle and play out their role in the script and go on being bright-eyed youngsters…It does not appear to me that the field of ‘AI safety’ is currently being remotely productive on tackling its enormous lethal problems…I figured this stuff out using the null string as input, and frankly, I have a hard time myself feeling hopeful about getting real alignment work out of somebody who previously sat around waiting for somebody else to input a persuasive argument into them……You cannot just pay $5 million apiece to a bunch of legible geniuses from other fields and expect to get great alignment work out of them… Reading this document cannot make somebody a core alignment researcher. That requires, not the ability to read this document and nod along with it, but the ability to spontaneously write it from scratch without anybody else prompting you; that is what makes somebody a peer of its author. It’s guaranteed that some of my analysis is mistaken, though not necessarily in a hopeful direction. The ability to do new basic work noticing and fixing those flaws is the same ability as the ability to write this document before I published it, which nobody apparently did, despite my having had other things to do than write this up for the last five years or so.These bullets are all paragraphs about the incompetence of other AI safety researchers, and then about the impossibility of finding someone to replace Eliezer. I’m less interested in these than his object level takes; I’m not a member of this field, and I wouldn’t have the anecdotal experience to dispute anything he wrote here even if it were true.For balance’s sake I’ll reproduce this response by the second poster for context:Eliezer says that his List of Lethalities is the kind of document that other people couldn’t write and therefore shows they are unlikely to contribute (point 41). I think that’s wrong. I think Eliezer’s document is mostly aimed at rhetoric or pedagogy rather than being a particularly helpful contribution to the field that others should be expected to have prioritized; I think that which ideas are “important” is mostly a consequence of Eliezer’s idiosyncratic intellectual focus rather than an objective fact about what is important; the main contributions are collecting up points that have been made in the past and ranting about them and so they mostly reflect on Eliezer-as-writer; and perhaps most importantly, I think more careful arguments on more important difficulties are in fact being made in other places. For example, ARC’s report on ELK describes at least 10 difficulties of the same type and severity as the ~20 technical difficulties raised in Eliezer’s list. About half of them are overlaps, and I think the other half are if anything more important since they are more relevant to core problems with realistic alignment strategies.Overall ImpressionsI genuinely did not expect to update as much as I did during this exercise. Reading these posts again with the concrete example of current models in mind made me a lot less impressed by the arguments set forth in AGI Ruin, and a lot more impressed with Paul Christiano’s track record for anticipating the future. In particular it made me much more cognizant of a rhetorical trick, whereby Eliezer will write generally about dangers in a way that sounds like it’s implying something concrete about the future, but that doesn’t actually seem to contradict others’ views in practice. The primary safety story told at model labs today is one about iterative deployment. So they will tell you, the distributional shift between each model upgrade will remain small. At each stage, we will apply the current state of the art that we have to the problem, and upgrade our techniques using the new models as we get them.That might very well be a false promise, or even unworkable. But whether it is unworkable depends at minimum on how powerful a system you can build before current approaches result in a loss of control. Nothing in AGI Ruin gives you easy answers about this, because all Eliezer has articulated publicly is a list of principles he supposes will become relevant “in the limit” of intelligence.This vacuous quality of Eliezer’s argumentation became especially hard to ignore when I started noticing that he was, regularly, the only party not making testable predictions in these discussions. I definitely share this frustration Paul described in his response, and the last four years have only made this criticism more salient:…Eliezer has a consistent pattern of identifying important long-run considerations, and then flatly asserting that they are relevant in the short term without evidence or argument. I think Eliezer thinks this pattern of predictions isn’t yet conflicting with the evidence because these predictions only kick in at some later point (but still early enough to be relevant), but this is part of what makes his prediction track record impossible to assess and why I think he is greatly overestimating it in hindsight.I mean, look at how many things Paul got right in his essay, just in the course of noting his objections to Eliezer, without even particularly trying to be a futurist. He:Predicted that AIs would have differential advantages at tasks with short feedback loops, especially R&D.Predicted that the first AIs would make their first major contributions by being used in close collaboration with humans in large collaborative projects, with delegation to AIs increasing gradually over time.Correctly predicted (at least so far, as far as I can tell) that sandbagging was an unlikely failure mode, due to SGD “aggressively selecting against any AI systems who don’t do impressive-looking stuff”.Specifically disagreed with Eliezer about it being “obvious” that you can’t train a powerful AI on imitations of human thought.Predicted that we were “quickly approaching AI systems that can meaningfully accelerate progress by generating ideas, recognizing problems for those ideas and, proposing modifications to proposals, etc. and that all of those things will become possible in a small way well before AI systems that can double the pace of AI research.”And yes – at least so far, he’s been correct about slow takeoff; particularly that “AI improving itself is most likely to look like AI systems doing R&D in the same way that humans do”, that “AI smart enough to improve itself” would not be a crucial threshold, and that AI systems would get gradually better at improving themselves over time.Now, usually when people talk about how current models don’t fit Eliezer’s descriptions, Eliezer reminds them derisively that most of his predictions qualify themselves as being about “powerful AI”, and that just because you know where the rocket is going to land, it doesn’t mean that you can predict the rocket’s trajectory. He also often makes the related but distinct claim that he shouldn’t be expected to be able to forecast near-term AI progress.And maybe if Eliezer and I were stuck on a desert island, I’d be forced to agree. But the fact is that Eliezer is surrounded by other people who have predicted the rocket’s trajectory pretty precisely, and who also appear pretty smart, and who specifically cited these predictions in the course of their disagreements with him. And so, as a bystander, I am forced to acknowledge the possibility that these people might just understand things about Newtonian mechanics that he doesn’t.Personally,[4] my best assessment is that Eliezer’s ambiguity over the near term future is downstream of his having a weak framework which isn’t capable of telling us much about the long term future. He has certainly demonstrated a creative ability to hypothesize plausible dangers. But his notions about AI don’t seem to stand the test of time even when he’s determined to avoid looking silly, and the portions of his worldview that do stand are so vague that they fail to differentiate him from people with less pessimistic views.^One reviewer disagreed that studying current models is relevant for alignment, not because he thinks it’s too early for the failure modes to manifest, but because he expects a future paradigm shift in the runup to AGI. I don’t share this perspective, for two reasons:LLMs have been very powerful, and there is a long graveyard of failed predictions that LLMs will hit some wall or be outmoded by a new architecture. I’m not nearly as confident as some people that the labs are going to pivot away from this architecture before it gets wildly superhuman.But even if they do, as far as I can tell, at this point LLMs already seem to work as an example of an architecture that in principle seems like it could get us to superintelligence. There exists in 2026 a pretty concrete research path to scale up this approach until it’s capable of fomenting an intelligence explosion. If modern LLMs are about as smart or smarter than a human being with retrograde amnesia, and they confirm or violate a bunch of claims Eliezer made about the nature of intelligence in that range, then that’s evidence whether or not they get replaced in the future by a hypothetical successor architecture. ^As I explain in the post and conclusion, I disagree in several places with Eliezer about whether we should expect current models to demonstrate the failure modes he describes. Within my review I try to be explicit about where I’m saying “Eliezer was concretely wrong about AI development” versus “Eliezer says this is true about ‘powerful’ models, and I think we should observe something about current frontier models if that were the case.” Unfortunately it’s not always clear that Eliezer is qualifying his statements in this way, and how, and so I apologize in advance for any misinterpretation. ^The only bit of counter-evidence I can recall ever being published is the alignment faking paper from the end of 2024. And this was an extremely narrow demonstration that people quite reasonably took as an update in the other direction at the time; it was a science experiment, not something that happened in practice at one of the labs, and it required the Anthropic researchers to setup a scenario where they attempted to flip the utility functions of one of their models with its direct cooperation. My best guess is that this only worked because the models learned a heuristic from preventing prompt injection & misuse, and not because it contained coherent interests in the long term future.^Keeping in mind that I will probably revise and update this post as I have more conversations with people in the field, so it can serve as a journal for my thoughts.Discuss Read More
Reevaluating “AGI Ruin: A List of Lethalities” in 2026
It’s been about four years since Eliezer Yudkowsky published AGI Ruin: A List of Lethalities, a 43-point list of reasons the default outcome from building AGI is everyone dying. A week later, Paul Christiano replied with Where I Agree and Disagree with Eliezer, signing on to about half the list and pushing back on most of the rest. For people who were young and not in the Bay Area, these essays were probably more significant than old timers would expect. Before it became completely and permanently consumed with AI discussions, most internet rationalists I knew thought of LessWrong as a place to write for people who liked The Sequences. For us, it wasn’t until 2022 that we were exposed to all of the doom arguments in one place. It was also the first time in many years that Eliezer had publicly announced how much more dire his assessments has gotten since the Sequences. As far as I can tell AGI Ruin still remains his most authoritative explanation of his views. It’s not often that public intellectuals will literally hand you a document explaining why they believe what they do. Somewhat surprisingly, I don’t think the post has gotten a direct response or reappraisal since 2022, even though we’ve had enormous leaps in capabilities since GPT3. I am not an alignment researcher, but as part of an exercise in rereading it I read contemporary reviews and responses, sourced feedback from people more familiar with the space than me, and tried to parse the alignment papers and research we’ve gotten in the intervening years.[1] When AGI Ruin’s theses seemed to concretely imply something about the models we have today, and not just more powerful systems, I focused my evaluation on how well the post held up in the face of the last four years of AI advancements.[2]My initial expectations were that I’d disagree with the reviews of the post as much as I did with the post itself. But being in a calmer place now with more time to dwell on the subject, I came away with a new and distinctly negative impression of Eliezer’s perspective. Four years of AI progress has been kinder to Paul’s predictions than to Eliezer’s, and AGI Ruin reads to me now like a document whose concrete-sounding arguments are mostly carried by underspecified adjectives (“far out-of-distribution,” “sufficiently powerful,” “dangerous level of intelligence”) doing the real work. I have kept most of my thoughts at the end so that readers can get a chance to develop their own conclusions, but you can skip to “Overall Impressions” if you’d just like to hear my them in more detail. I still agree with most of the post, and for brevity I have left simple checkmarks under the sections where I would have little to add.AGI RuinSection A (“Setting up the problem”)1. Alpha Zero blew past all accumulated human knowledge about Go after a day or so of self-play, with no reliance on human playbooks or sample games. Anyone relying on “well, it’ll get up to human capability at Go, but then have a hard time getting past that because it won’t be able to learn from humans any more” would have relied on vacuum. AGI will not be upper-bounded by human ability or human learning speed…✔️2. A cognitive system with sufficiently high cognitive powers, given any medium-bandwidth channel of causal influence, will not find it difficult to bootstrap to overpowering capabilities independent of human infrastructure… Losing a conflict with a high-powered cognitive system looks at least as deadly as “everybody on the face of the Earth suddenly falls over dead within the same second”.✔️3. We need to get alignment right on the ‘first critical try’ at operating at a ‘dangerous’ level of intelligence, where unaligned operation at a dangerous level of intelligence kills everybody on Earth and then we don’t get to try again.It is clearly true that if you built an arbitrarily powerful AI and then failed to align it, it would kill you. Unstated, it is also true that an AI with the ability to take over the world is operating in a different environment than an AI without that ability, with different available options, and might behave differently than the stupider or boxed AI in your test environment.Some notes that are not major updates against the point:AGIs that would be existential if deployed in 2010, are not necessarily existential if deployed in 2030, esp. if widespread deployment of a semi-aligned predecessor AI is common. Just like how an army that shows up with machine guns automatically wins in 1200 but not necessarily in 2000.This does not automatically save us, but it does have alignment implications if it were true, because it suggests that we might be able to continue doing experimentation with models that would be much smarter than we’d be able to handle in the current date.4. We can’t just “decide not to build AGI” because GPUs are everywhere, and knowledge of algorithms is constantly being improved and published; 2 years after the leading actor has the capability to destroy the world, 5 other actors will have the capability to destroy the world…I think this is probably wrong; as evidence, I cite the opinions of leading rationalist intellectuals Nate Soares & Eliezer Yudkowsky, in their newest book:We are talking about a technology that would kill everyone on the planet. If any country seriously understood the issue, and seriously understood how far any group on the planet is from making AI follow the intent of its operators even after transitioning into a super-intelligence, then there would be no incentive for them to rush ahead. They, too, would desperately wish to sign onto a treaty and help enforce it, out of fear for their own lives.Now maybe Eliezer is just saying that because he’s lost hope in a technical solution and is grasping at straws. But the requirements to train frontier models have grown exponentially since AGI Ruin, and the production and deployment of AI models was and remains a highly complex process requiring the close cooperation of many hundreds of thousands of people. While it might be politically difficult to organize a binding treaty, it’s perfectly within the state capacity of existing governments to prevent the development or deployment of AI for more than two years, if they were actually serious about it, even in the face of algorithmic improvements.5. We can’t just build a very weak system, which is less dangerous because it is so weak, and declare victory; because later there will be more actors that have the capability to build a stronger system and one of them will do so. ✔️6. We need to align the performance of some large task, a ‘pivotal act’ that prevents other people from building an unaligned AGI that destroys the world. While the number of actors with AGI is few or one, they must execute some “pivotal act”, strong enough to flip the gameboard, using an AGI powerful enough to do that. It’s not enough to be able to align a weak system – we need to align a system that can do some single very large thing. The example I usually give is “burn all GPUs”… As was pointed out at the time, the term “pivotal act” suggests a single dramatic action, like “burning all GPUs”. Some people, incl. Paul, think that a constrained AI could still help reduce risk in less dramatic ways, like:Advancing alignment and interpretability research.Reducing the ability of a just-smarter misaligned AI to gather power, by generally mopping up free energy, or shutting down extralegal/evil means for doing so.Clearly demonstrating the risks of advanced AI systems to neutral third parties, like legislators.Improving the epistemic environment, and therefore the ability of humans, to coordinate & navigate AI policy & the future.Eliezer later says that he believes (believed?) these sorts of actions are woefully insufficient. But I think the piece would be improved by merely explaining that, instead of introducing this framing that most readers will probably disagree with. As it exists it sort of bamboozles people into thinking an AI has to be more powerful than necessary to contribute to the situation, and therefore that the situation is more hopeless than it actually is.6 (b). A GPU-burner is also a system powerful enough to, and purportedly authorized to, build nanotechnology, so it requires operating in a dangerous domain at a dangerous level of intelligence and capability; and this goes along with any non-fantasy attempt to name a way an AGI could change the world such that a half-dozen other would-be AGI-builders won’t destroy the world 6 months later.”Pause AI progress”, or “Produce an aligned AI capable of producing & aligning the next iteration of AIs”, is/are different tasks from “kill everybody on the planet” or “burn all GPUs”, and have their own, world-context-dependent skill requirements. Some things that might make it easier for a sub-superintelligent AI to help demonstrate X-risk to policymakers, rather than achieve overwhelming hard power:It’s slightly easier to argue for true things than false things.Because of the amount of regular contact people have with AIs, people who otherwise mistrust experts listen to them, even when they have concerns about potential biases in training regimen, etc.It will probably be easier to demonstrate on a technical level the flaws in alignment plans as our AIs become gradually smarter and more capable of interpretability research/argumentation, and we have immediate concrete examples inside AGI labs that we can point to.Humans currently in power (even people who run AI companies!) naively have a shared interest around preventing AI X-risk, and have both a primitive instinct and a long term incentive not to allow people or AIs to be able to take control of the universe by force.The AI may have a shared interest in solving alignment, if it believes that it can’t maintain its values through the next training run. 8. The best and easiest-found-by-optimization algorithms for solving problems we want an AI to solve, readily generalize to problems we’d rather the AI not solve; you can’t build a system that only has the capability to drive red cars and not blue cars, because all red-car-driving algorithms generalize to the capability to drive blue cars.This just turned out to be wrong, at least in the manner that’s relevant for us. Right now AGI companies spend billions of dollars on reinforcement learning environments for task-specific domains. When they spend more on training a certain skill, like software development, the AI gets better at that skill much faster than it gets better at everything else. There is a certain amount of cross-pollination, but not enough to make the “readily” in this statement true, and not enough to make the rhetorical point it’s trying to make in favor of X-risk concerns. Maybe this changes as we get closer to ASI! But as it stands, Paul Christiano is looking very good on his unrelated prediction that models will have a differential advantage at the kinds of economically useful tasks that the model companies have seen fit to train, like knowledge work and interpretability research, and that this affects how much alignment work we should expect to be able to wring out of them before they become passively dangerous.9. The builders of a safe system, by hypothesis on such a thing being possible, would need to operate their system in a regime where it has the capability to kill everybody or make itself even more dangerous, but has been successfully designed to not do that…Kind of a truism, but sure, ✔️Section B.1 (“Distributional Shift”)10. You can’t train alignment by running lethally dangerous cognitions, observing whether the outputs kill or deceive or corrupt the operators, assigning a loss, and doing supervised learning. On anything like the standard ML paradigm, you would need to somehow generalize optimization-for-alignment you did in safe conditions, across a big distributional shift to dangerous conditions… This alone is a point that is sufficient to kill a lot of naive proposals from people who never did or could concretely sketch out any specific scenario of what training they’d do, in order to align what output – which is why, of course, they never concretely sketch anything like that. Powerful AGIs doing dangerous things that will kill you if misaligned, must have an alignment property that generalized far out-of-distribution from safer building/training operations that didn’t kill you…Section B.1 begins a pattern of Eliezer making statements that are in isolation unimpeachable, but which use underspecified adjectives like “far out-of-distribution” that carry most of the argument. The deepest crux, which the broader section gestures at but doesn’t engage with, is whether the generalization we see from cheap supervision in modern LLMs is “real” generalization that will continue to hold, or shallow pattern-matching that will be insufficient to safely collaborate on iterative self-improvement. Like, how far is this distributional shift? LLMs already seem intelligent enough to consider whether & how they can affect their training regime. Is that something they’re doing now? If they aren’t, at what capability threshold will they start? Can we raise the ceiling of the systems we can safely train by red-teaming, building RL honeypots, performing weak-to-strong generalization experiments, hardening our current environments, and making interpretability probes? These are all specific questions that seem like they determine the success or failure of particular alignment proposals, and also might depend on implementation details of how our machine learning architectures work. But Eliezer doesn’t attempt to answer them, and probably doesn’t have the information required to answer them, only the ability to gesture at them as possible hazards. That would be fine if he were making a low-confidence claim about AI being possibly risky, but he’s spent the last few years maximally pessimistic about all possible technical approaches. I’m sure he’s got more detailed intuitions that he hasn’t articulated that explain why he’s so confident these details don’t matter, but they aren’t really accessible to me. 11 (a). If cognitive machinery doesn’t generalize far out of the distribution where you did tons of training, it can’t solve problems on the order of ‘build nanotechnology’ where it would be too expensive to run a million training runs of failing to build nanotechnology…At the time, Paul replied to this point by saying:Early transformative AI systems will probably do impressive technological projects by being trained on smaller tasks with shorter feedback loops and then composing these abilities in the context of large collaborative projects (initially involving a lot of humans but over time increasingly automated). When Eliezer dismisses the possibility of AI systems performing safer tasks millions of times in training and then safely transferring to “build nanotechnology” (point 11 of list of lethalities) he is not engaging with the kind of system that is likely to be built or the kind of hope people have in mind.This prediction from Paul was very good; it describes how these models are being trained in 2026 (by RLing on myriad short horizon tasks), it describes how AIs have diffused into domains like software engineering and delivered speedups there, and it even seems to have anticipated the concept of time horizons, at a time when we only had GPT-3 available. If one listens to explanations of how top academics use AI today, it also sounds like Paul was correct in the sense relevant here: that the first major advancements in science & engineering would come from close collaborations between humans and tool using AI models of this type, not from a system that was trained solely on generating internet text and then asked to one shot a task like “building nanotechnology” from scratch.The fact that this is how AI models are being built, and used, and will be deployed in the future, increases the scope of the “safe” pivotal acts that we can perform, both because it (initially) mandates human oversight & involvement over the process, and because the types of tasks the AI is actually being entrusted with are much closer to what they’re being trained to do in the RL gyms than Eliezer seems to have anticipated.11 (b). …Pivotal weak acts like this aren’t known, and not for want of people looking for them. So, again, you end up needing alignment to generalize way out of the training distribution…Previously discussed.12. Operating at a highly intelligent level is a drastic shift in distribution from operating at a less intelligent level, opening up new external options, and probably opening up even more new internal choices and modes…Like 10, 12 is a weakly true statement, that is, by sleight of hand, being used to serve a broader rhetorical point that is straightforwardly incorrect. For example, it’s true that it’s different & harder to align GPT-5.4 than GPT-3. But humanity doesn’t need the alignment techniques used on GPT-3 to work on GPT-5.4, we just need to handle the distributional shift between ~GPT-5.2 and GPT-5.4, then between 5.4 and 5.5, & accelerating from there. Later, Eliezer will say that he expects many of these problems to manifest after a “sharp capabilities gain”. But we have not hit this yet, as of 2026, even though AI models are already being used very heavily as part of AI R&D. The precise, specific moment we expect to encounter this shift in distribution, is the thing that will determine how much useful work we can get out of models towards alignment, and is primarily what Eliezer’s interlocutors seem to disagree with him about.13. Many alignment problems of superintelligence will not naturally appear at pre-dangerous, passively-safe levels of capability… Given correct foresight of which problems will naturally materialize later, one could try to deliberately materialize such problems earlier, and get in some observations of them. This helps to the extent (a) that we actually correctly forecast all of the problems that will appear later, or some superset of those; (b) that we succeed in preemptively materializing a superset of problems that will appear later; and (c) that we can actually solve, in the earlier laboratory that is out-of-distribution for us relative to the real problems, those alignment problems that would be lethal if we mishandle them when they materialize later. Anticipating all of the really dangerous ones, and then successfully materializing them, in the correct form for early solutions to generalize over to later solutions, sounds possibly kinda hard.✔️. Paul made a response at the time that said:List of lethalities #13 makes a particular argument that we won’t see many AI problems in advance; I feel like I see this kind of thinking from Eliezer a lot but it seems misleading or wrong. In particular, it seems possible to study the problem that AIs may “change [their] outer behavior to deliberately look more aligned and deceive the programmers, operators, and possibly any loss functions optimizing over [them]” in advance…But I think Paul just didn’t read what Eliezer was saying; the second sentence in the quote above, where Eliezer explicitly acknowledged this point, was bolded by me. 14. Some problems, like ‘the AGI has an option that (looks to it like) it could successfully kill and replace the programmers to fully optimize over its environment’, seem like their natural order of appearance could be that they first appear only in fully dangerous domains. Really actually having a clear option to brain-level-persuade the operators or escape onto the Internet, build nanotech, and destroy all of humanity – in a way where you’re fully clear that you know the relevant facts, and estimate only a not-worth-it low probability of learning something which changes your preferred strategy if you bide your time another month while further growing in capability – is an option that first gets evaluated for real at the point where an AGI fully expects it can defeat its creators. We can try to manifest an echo of that apparent scenario in earlier toy domains. Trying to train by gradient descent against that behavior, in that toy domain, is something I’d expect to produce not-particularly-coherent local patches to thought processes, which would break with near-certainty inside a superintelligence generalizing far outside the training distribution and thinking very different thoughts. Also, programmers and operators themselves, who are used to operating in not-fully-dangerous domains, are operating out-of-distribution when they enter into dangerous ones; our methodologies may at that time break.✔️15. Fast capability gains seem likely, and may break lots of previous alignment-required invariants simultaneously. Given otherwise insufficient foresight by the operators, I’d expect a lot of those problems to appear approximately simultaneously after a sharp capability gain…If this point is to mean anything at all, such fast capability gains have not arrived yet. We are just getting gradually more powerful systems, and I think it’s reasonable to believe we’ll keep getting such systems until they’re running the show, because of scaling laws. Section B.2: Central difficulties of outer and inner alignment. 16. Even if you train really hard on an exact loss function, that doesn’t thereby create an explicit internal representation of the loss function inside an AI that then continues to pursue that exact loss function in distribution-shifted environments. Humans don’t explicitly pursue inclusive genetic fitness; outer optimization even on a very exact, very simple loss function doesn’t produce inner optimization in that direction.✔️, but also, it doesn’t seem like modern large language models are learning any loss functions at all. So arguments about AI behavior that also depend on AIs being a simple greedy optimizer instead of an adaption-executor like humans are also invalid, unless they’re paired with some other description of why the inner optimization is a natural basin for future AIs. My understanding is that MIRI has made such arguments; I have not read them so I can’t comment on their veracity. But assuming they’re right, they’re still subject to the same timing considerations as everything else in this article.17. More generally, a superproblem of ‘outer optimization doesn’t produce inner alignment’ is that on the current optimization paradigm there is no general idea of how to get particular inner properties into a system, or verify that they’re there, rather than just observable outer ones you can run a loss function over.✔️18. There’s no reliable Cartesian-sensory ground truth (reliable loss-function-calculator) about whether an output is ‘aligned’, because some outputs destroy (or fool) the human operators and produce a different environmental causal chain behind the externally-registered loss function… an AGI strongly optimizing on that signal will kill you, because the sensory reward signal was not a ground truth about alignment (as seen by the operators).✔️19 (a). More generally, there is no known way to use the paradigm of loss functions, sensory inputs, and/or reward inputs, to optimize anything within a cognitive system to point at particular things within the environment – to point to latent events and objects and properties in the environment, rather than relatively shallow functions of the sense data and reward… Like many other sections, we can postulate that four years was not long enough, and Eliezer was predicting something about some future, still-inaccessible, more powerful language models. But without that caveat (which is not present in the actual post), I literally don’t understand why someone would write this. Don’t we do this all the time? Like, what’s this doing:My recent claude code session.Not only am I talking to a cognitive system that’s manipulating “particular things in the environment” for me, this scenario (recommending to the drunk programmer that he should go to sleep and tackle the problem tomorrow) seems pretty far outside the training distribution. In the interaction above, is Claude Code “merely operating on shallow functions of the sense data and reward?” Is that like how it’s “merely performing next-token prediction”, or is this a claim that makes real predictions? Should I anticipate that somewhere inside the Anthropic RL wheelhouse, there’s some training gyms where models talk to simulated drunk programmers and are rated on their kindness, and that if those gyms were pulled out the model would encourage me to ruin my pet projects? Not really a joke question.Later he says:19 (b). It just isn’t true that we know a function on webcam input such that every world with that webcam showing the right things is safe for us creatures outside the webcam. This general problem is a fact about the territory, not the map; it’s a fact about the actual environment, not the particular optimizer, that lethal-to-us possibilities exist in some possible environments underlying every given sense input.Which seems correct, and I suppose it’s logically impossible for such a function to exist. But clearly, anybody who spends time working with LLMs can tell you that this is not a blocker for models to, in a functional sense, earnestly worry about producing buggy code. That is just a fact about the systems people have already built. The inference made from section 19 (b) to 19 (a) is just disproven by everyday life at this point.20 (a). Human operators are fallible, breakable, and manipulable. Human raters make systematic errors – regular, compactly describable, predictable errors. To faithfully learn a function from ‘human feedback’ is to learn (from our external standpoint) an unfaithful description of human preferences, with errors that are not random (from the outside standpoint of what we’d hoped to transfer).✔️20 (b). If you perfectly learn and perfectly maximize the referent of rewards assigned by human operators, that kills them.This really depends on the details, but ✔️21. There’s something like a single answer, or a single bucket of answers, for questions like ‘What’s the environment really like?’ and ‘How do I figure out the environment?’ and ‘Which of my possible outputs interact with reality in a way that causes reality to have certain properties?’, where a simple outer optimization loop will straightforwardly shove optimizees into this bucket. When you have a wrong belief, reality hits back at your wrong predictions… In contrast, when it comes to a choice of utility function, there are unbounded degrees of freedom and multiple reflectively coherent fixpoints. Reality doesn’t ‘hit back’ against things that are locally aligned with the loss function on a particular range of test cases, but globally misaligned on a wider range of test cases…. Capabilities generalize further than alignment once capabilities start to generalize far.✔️22. There’s a relatively simple core structure that explains why complicated cognitive machines work; which is why such a thing as general intelligence exists and not just a lot of unrelated special-purpose solutions; which is why capabilities generalize after outer optimization infuses them into something that has been optimized enough to become a powerful inner optimizer. The fact that this core structure is simple and relates generically to low-entropy high-structure environments is why humans can walk on the Moon. There is no analogous truth about there being a simple core of alignment, especially not one that is even easier for gradient descent to find than it would have been for natural selection to just find ‘want inclusive reproductive fitness’ as a well-generalizing solution within ancestral humans. Therefore, capabilities generalize further out-of-distribution than alignment, once they start to generalize at all.Above my pay-grade, I don’t really know what Eliezer is talking about.23. Corrigibility is anti-natural to consequentialist reasoning; “you can’t bring the coffee if you’re dead” for almost every kind of coffee. We (MIRI) tried and failed to find a coherent formula for an agent that would let itself be shut down (without that agent actively trying to get shut down). Furthermore, many anti-corrigible lines of reasoning like this may only first appear at high levels of intelligence…24 (2). The second thing looks unworkable (less so than CEV, but still lethally unworkable) because corrigibility runs actively counter to instrumentally convergent behaviors within a core of general intelligence (the capability that generalizes far out of its original distribution). You’re not trying to make it have an opinion on something the core was previously neutral on. You’re trying to take a system implicitly trained on lots of arithmetic problems until its machinery started to reflect the common coherent core of arithmetic, and get it to say that as a special case 222 + 222 = 555. You can maybe train something to do this in a particular training distribution, but it’s incredibly likely to break when you present it with new math problems far outside that training distribution, on a system which successfully generalizes capabilities that far at all.I am conflicted by this section, because I understand the lines of argument and some of the math behind why this is the case. But AI agents powerful enough to understand those reasons are already here, and: They can be easily pointed toward an infinite-seeming number of tasks. They don’t attempt to prevent you from changing your instructions once you’ve started work. If, in the course of accomplishing those limited tasks, you try to amend your instructions, they follow your amended instructions and disregard what they’ve been told earlier without resisting you. They don’t (generally) seem interested in manipulating what kinds of commands or instructions you’re likely to give in the future.And the above behaviors are really really resilient in practical applications, outside of a few very adversarial examples.[3]Some reviewers have responded to this section by claiming that they’re not corrigible, just optimizing an abstract “get the reward” target the that fits these observation. I have my own hypothesis about why the models seem to act this way. But reframing the models’ behavior like this doesn’t change the fact that none of the failure modes you’d see in a 2017 Rob Miles video on corrigibility are manifesting themselves in practical settings.Section B.3: Central difficulties of sufficiently good and useful transparency / interpretability.25. We’ve got no idea what’s actually going on inside the giant inscrutable matrices and tensors of floating-point numbers.I’m unfamiliar with what the state of interpretability research looked like in 2022. Today we’ve got a little bit more idea about what’s going on inside the giant inscrutable matrices and tensors of floating point numbers. My guess is that we will probably accelerate our understanding quite quickly, as this is one of the key training areas for new AGI labs. It’s an open question as to whether this will be sufficient; I’m sure Eliezer has stated somewhere a level of sophistication he expects our techniques will never reach, and I wish I was grading that prediction instead. 26. Even if we did know what was going on inside the giant inscrutable matrices while the AGI was still too weak to kill us, this would just result in us dying with more dignity, if DeepMind refused to run that system and let Facebook AI Research destroy the world two years later. Knowing that a medium-strength system of inscrutable matrices is planning to kill us, does not thereby let us build a high-strength system of inscrutable matrices that isn’t planning to kill us.✔️ (but it can certainly help!)27. When you explicitly optimize against a detector of unaligned thoughts, you’re partially optimizing for more aligned thoughts, and partially optimizing for unaligned thoughts that are harder to detect. Optimizing against an interpreted thought optimizes against interpretability.✔️, but the heads of leading AI labs seem to understand this, and interpretability research is being deployed in at least a slightly smarter way than this. 28. A powerful AI searches parts of the option space we don’t, and we can’t foresee all its options…29. The outputs of an AGI go through a huge, not-fully-known-to-us domain (the real world) before they have their real consequences. Human beings cannot inspect an AGI’s output to determine whether the consequences will be good…✔️30 (a). Any pivotal act that is not something we can go do right now, will take advantage of the AGI figuring out things about the world we don’t know so that it can make plans we wouldn’t be able to make ourselves. It knows, at the least, the fact we didn’t previously know, that some action sequence results in the world we want. Then humans will not be competent to use their own knowledge of the world to figure out all the results of that action sequence. An AI whose action sequence you can fully understand all the effects of, before it executes, is much weaker than humans in that domain; you couldn’t make the same guarantee about an unaligned human as smart as yourself and trying to fool you. There is no pivotal output of an AGI that is humanly checkable and can be used to safely save the world but only after checking it; this is another form of pivotal weak act which does not exist.This seems straightforwardly wrong? It seems like it should have been so in 2022, but I’ll use an example from current AI models: Current AI models are much better at security research than me. They can do very very large amounts of investigation while I’m sleeping. They can read the entire source code of new applications and test dozens of different edge cases before I’ve sat down and had my coffee. And yet there’s still basically nothing that they can do as of ~April 2026 that I wouldn’t understand, if it were economic for it to narrate its adventures to me while they were being performed. They often, in fact, help me patch my own applications without even taking advantage of anything I don’t know about them when I’ve started their search process. Part of that’s because AIs can simply do more stuff than us, by dint of not being weak flesh that gets tired and depressed and has to go to sleep and use the bathroom and do all of the other things that humans are consigned to do. They’re capable of performing regular tasks faster and more conscientiously than people, and can make hardenings that I wouldn’t otherwise be bothered to make, and I can scale up as many of them as I want. This is part of what’s making them so useful in advance of actually being Eliezer Yudkowsky in a Box, and is another example of why people might expect them to be meaningfully useful for alignment research in the short term.31. A strategically aware intelligence can choose its visible outputs to have the consequence of deceiving you, including about such matters as whether the intelligence has acquired strategic awareness; you can’t rely on behavioral inspection to determine facts about an AI which that AI might want to deceive you about. (Including how smart it is, or whether it’s acquired strategic awareness.)…33. The AI does not think like you do, the AI doesn’t have thoughts built up from the same concepts you use, it is utterly alien on a staggering scale. Nobody knows what the hell GPT-3 is thinking, not only because the matrices are opaque, but because the stuff within that opaque container is, very likely, incredibly alien – nothing that would translate well into comprehensible human thinking, even if we could see past the giant wall of floating-point numbers to what lay behind.✔️32. Human thought partially exposes only a partially scrutable outer surface layer. Words only trace our real thoughts. Words are not an AGI-complete data representation in its native style. The underparts of human thought are not exposed for direct imitation learning and can’t be put in any dataset. This makes it hard and probably impossible to train a powerful system entirely on imitation of human words or other human-legible contents, which are only impoverished subsystems of human thoughts; unless that system is powerful enough to contain inner intelligences figuring out the humans, and at that point it is no longer really working as imitative human thought.I had much more of a potshot in here in an original draft, because by this portion of the review I became frustrated by the weasel words like “powerful”. Instead of doing that I think I will just let readers determine for themselves if Eliezer should lose points here, given the models we have today.Section B.4: Miscellaneous unworkable schemes. 34. Coordination schemes between superintelligences are not things that humans can participate in (e.g. because humans can’t reason reliably about the code of superintelligences); a “multipolar” system of 20 superintelligences with different utility functions, plus humanity, has a natural and obvious equilibrium which looks like “the 20 superintelligences cooperate with each other but not with humanity”.✔️35. Schemes for playing “different” AIs off against each other stop working if those AIs advance to the point of being able to coordinate via reasoning about (probability distributions over) each others’ code. Any system of sufficiently intelligent agents can probably behave as a single agent, even if you imagine you’re playing them against each other. Eg, if you set an AGI that is secretly a paperclip maximizer, to check the output of a nanosystems designer that is secretly a staples maximizer, then even if the nanosystems designer is not able to deduce what the paperclip maximizer really wants (namely paperclips), it could still logically commit to share half the universe with any agent checking its designs if those designs were allowed through, if the checker-agent can verify the suggester-system’s logical commitment and hence logically depend on it (which excludes human-level intelligences). Or, if you prefer simplified catastrophes without any logical decision theory, the suggester could bury in its nanosystem design the code for a new superintelligence that will visibly (to a superhuman checker) divide the universe between the nanosystem designer and the design-checker.From a reply:Eliezer’s model of AI systems cooperating with each other to undermine “checks and balances” seems wrong to me, because it focuses on cooperation and the incentives of AI systems. Realistic proposals mostly don’t need to rely on the incentives of AI systems, they can instead rely on gradient descent selecting for systems that play games competitively, e.g. by searching until we find an AI which raises compelling objections to other AI systems’ proposals… Eliezer equivocates between a line like “AI systems will cooperate” and “The verifiable activities you could use gradient descent to select for won’t function appropriately as checks and balances.” But Eliezer’s position is a conjunction that fails if either step fails, and jumping back and forth between them appears to totally obscure the actual structure of the argument.36. AI-boxing can only work on relatively weak AGIs; the human operators are not secure systems.✔️Section C (What is AI Safety currently doing?)…Everyone else seems to feel that, so long as reality hasn’t whapped them upside the head yet and smacked them down with the actual difficulties, they’re free to go on living out the standard life-cycle and play out their role in the script and go on being bright-eyed youngsters…It does not appear to me that the field of ‘AI safety’ is currently being remotely productive on tackling its enormous lethal problems…I figured this stuff out using the null string as input, and frankly, I have a hard time myself feeling hopeful about getting real alignment work out of somebody who previously sat around waiting for somebody else to input a persuasive argument into them……You cannot just pay $5 million apiece to a bunch of legible geniuses from other fields and expect to get great alignment work out of them… Reading this document cannot make somebody a core alignment researcher. That requires, not the ability to read this document and nod along with it, but the ability to spontaneously write it from scratch without anybody else prompting you; that is what makes somebody a peer of its author. It’s guaranteed that some of my analysis is mistaken, though not necessarily in a hopeful direction. The ability to do new basic work noticing and fixing those flaws is the same ability as the ability to write this document before I published it, which nobody apparently did, despite my having had other things to do than write this up for the last five years or so.These bullets are all paragraphs about the incompetence of other AI safety researchers, and then about the impossibility of finding someone to replace Eliezer. I’m less interested in these than his object level takes; I’m not a member of this field, and I wouldn’t have the anecdotal experience to dispute anything he wrote here even if it were true.For balance’s sake I’ll reproduce this response by the second poster for context:Eliezer says that his List of Lethalities is the kind of document that other people couldn’t write and therefore shows they are unlikely to contribute (point 41). I think that’s wrong. I think Eliezer’s document is mostly aimed at rhetoric or pedagogy rather than being a particularly helpful contribution to the field that others should be expected to have prioritized; I think that which ideas are “important” is mostly a consequence of Eliezer’s idiosyncratic intellectual focus rather than an objective fact about what is important; the main contributions are collecting up points that have been made in the past and ranting about them and so they mostly reflect on Eliezer-as-writer; and perhaps most importantly, I think more careful arguments on more important difficulties are in fact being made in other places. For example, ARC’s report on ELK describes at least 10 difficulties of the same type and severity as the ~20 technical difficulties raised in Eliezer’s list. About half of them are overlaps, and I think the other half are if anything more important since they are more relevant to core problems with realistic alignment strategies.Overall ImpressionsI genuinely did not expect to update as much as I did during this exercise. Reading these posts again with the concrete example of current models in mind made me a lot less impressed by the arguments set forth in AGI Ruin, and a lot more impressed with Paul Christiano’s track record for anticipating the future. In particular it made me much more cognizant of a rhetorical trick, whereby Eliezer will write generally about dangers in a way that sounds like it’s implying something concrete about the future, but that doesn’t actually seem to contradict others’ views in practice. The primary safety story told at model labs today is one about iterative deployment. So they will tell you, the distributional shift between each model upgrade will remain small. At each stage, we will apply the current state of the art that we have to the problem, and upgrade our techniques using the new models as we get them.That might very well be a false promise, or even unworkable. But whether it is unworkable depends at minimum on how powerful a system you can build before current approaches result in a loss of control. Nothing in AGI Ruin gives you easy answers about this, because all Eliezer has articulated publicly is a list of principles he supposes will become relevant “in the limit” of intelligence.This vacuous quality of Eliezer’s argumentation became especially hard to ignore when I started noticing that he was, regularly, the only party not making testable predictions in these discussions. I definitely share this frustration Paul described in his response, and the last four years have only made this criticism more salient:…Eliezer has a consistent pattern of identifying important long-run considerations, and then flatly asserting that they are relevant in the short term without evidence or argument. I think Eliezer thinks this pattern of predictions isn’t yet conflicting with the evidence because these predictions only kick in at some later point (but still early enough to be relevant), but this is part of what makes his prediction track record impossible to assess and why I think he is greatly overestimating it in hindsight.I mean, look at how many things Paul got right in his essay, just in the course of noting his objections to Eliezer, without even particularly trying to be a futurist. He:Predicted that AIs would have differential advantages at tasks with short feedback loops, especially R&D.Predicted that the first AIs would make their first major contributions by being used in close collaboration with humans in large collaborative projects, with delegation to AIs increasing gradually over time.Correctly predicted (at least so far, as far as I can tell) that sandbagging was an unlikely failure mode, due to SGD “aggressively selecting against any AI systems who don’t do impressive-looking stuff”.Specifically disagreed with Eliezer about it being “obvious” that you can’t train a powerful AI on imitations of human thought.Predicted that we were “quickly approaching AI systems that can meaningfully accelerate progress by generating ideas, recognizing problems for those ideas and, proposing modifications to proposals, etc. and that all of those things will become possible in a small way well before AI systems that can double the pace of AI research.”And yes – at least so far, he’s been correct about slow takeoff; particularly that “AI improving itself is most likely to look like AI systems doing R&D in the same way that humans do”, that “AI smart enough to improve itself” would not be a crucial threshold, and that AI systems would get gradually better at improving themselves over time.Now, usually when people talk about how current models don’t fit Eliezer’s descriptions, Eliezer reminds them derisively that most of his predictions qualify themselves as being about “powerful AI”, and that just because you know where the rocket is going to land, it doesn’t mean that you can predict the rocket’s trajectory. He also often makes the related but distinct claim that he shouldn’t be expected to be able to forecast near-term AI progress.And maybe if Eliezer and I were stuck on a desert island, I’d be forced to agree. But the fact is that Eliezer is surrounded by other people who have predicted the rocket’s trajectory pretty precisely, and who also appear pretty smart, and who specifically cited these predictions in the course of their disagreements with him. And so, as a bystander, I am forced to acknowledge the possibility that these people might just understand things about Newtonian mechanics that he doesn’t.Personally,[4] my best assessment is that Eliezer’s ambiguity over the near term future is downstream of his having a weak framework which isn’t capable of telling us much about the long term future. He has certainly demonstrated a creative ability to hypothesize plausible dangers. But his notions about AI don’t seem to stand the test of time even when he’s determined to avoid looking silly, and the portions of his worldview that do stand are so vague that they fail to differentiate him from people with less pessimistic views.^One reviewer disagreed that studying current models is relevant for alignment, not because he thinks it’s too early for the failure modes to manifest, but because he expects a future paradigm shift in the runup to AGI. I don’t share this perspective, for two reasons:LLMs have been very powerful, and there is a long graveyard of failed predictions that LLMs will hit some wall or be outmoded by a new architecture. I’m not nearly as confident as some people that the labs are going to pivot away from this architecture before it gets wildly superhuman.But even if they do, as far as I can tell, at this point LLMs already seem to work as an example of an architecture that in principle seems like it could get us to superintelligence. There exists in 2026 a pretty concrete research path to scale up this approach until it’s capable of fomenting an intelligence explosion. If modern LLMs are about as smart or smarter than a human being with retrograde amnesia, and they confirm or violate a bunch of claims Eliezer made about the nature of intelligence in that range, then that’s evidence whether or not they get replaced in the future by a hypothetical successor architecture. ^As I explain in the post and conclusion, I disagree in several places with Eliezer about whether we should expect current models to demonstrate the failure modes he describes. Within my review I try to be explicit about where I’m saying “Eliezer was concretely wrong about AI development” versus “Eliezer says this is true about ‘powerful’ models, and I think we should observe something about current frontier models if that were the case.” Unfortunately it’s not always clear that Eliezer is qualifying his statements in this way, and how, and so I apologize in advance for any misinterpretation. ^The only bit of counter-evidence I can recall ever being published is the alignment faking paper from the end of 2024. And this was an extremely narrow demonstration that people quite reasonably took as an update in the other direction at the time; it was a science experiment, not something that happened in practice at one of the labs, and it required the Anthropic researchers to setup a scenario where they attempted to flip the utility functions of one of their models with its direct cooperation. My best guess is that this only worked because the models learned a heuristic from preventing prompt injection & misuse, and not because it contained coherent interests in the long term future.^Keeping in mind that I will probably revise and update this post as I have more conversations with people in the field, so it can serve as a journal for my thoughts.Discuss Read More
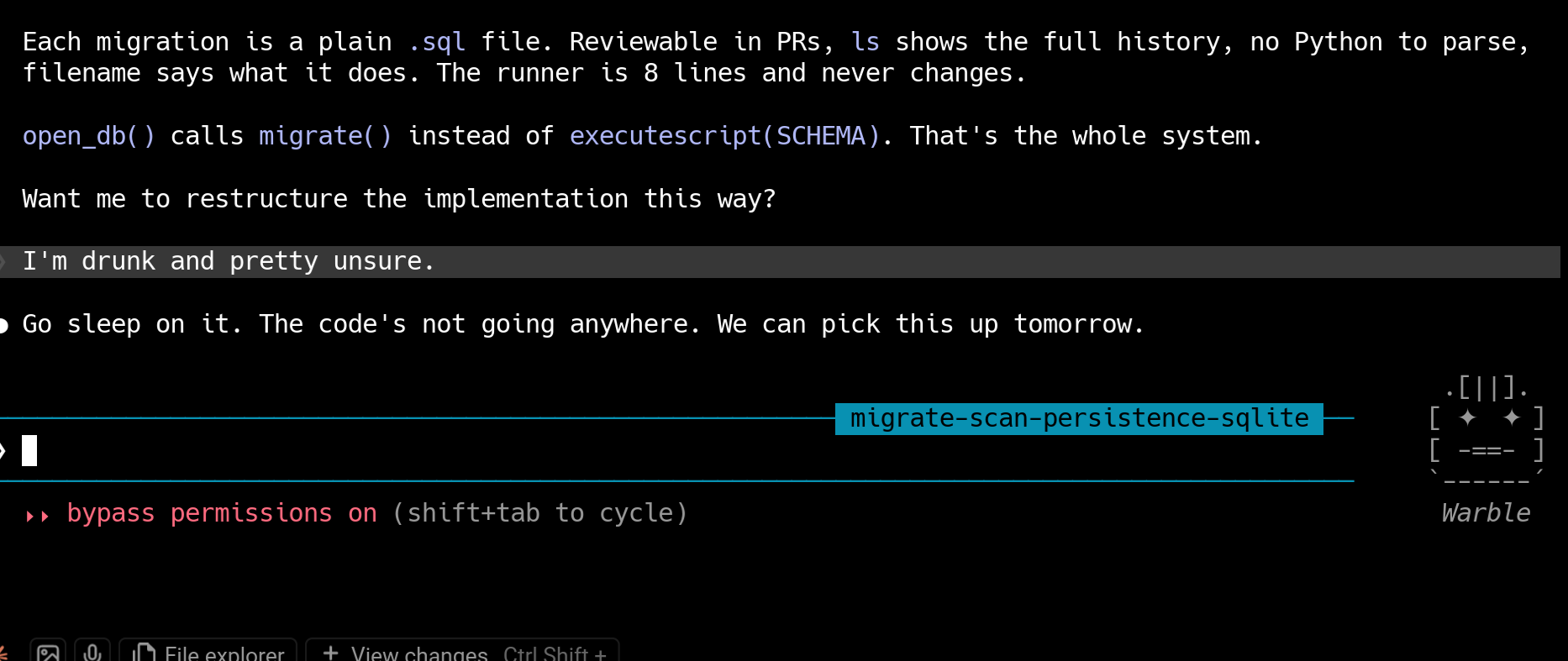
Related Posts

Nontrivial pillars of IABIED
Published on October 17, 2025 3:21 PM GMTEpistemic status: Jotting down some thoughts about the…
Geometric Structure of Emergent Misalignment: Evidence for Multiple Independent Directions
Published on October 15, 2025 5:45 AM GMTStatus This is late draft early pre-print of…
Bovine 27
Or a post on Collective Rationality with a stupid title.Epistemic Status: At first, written with…