Acknowledgments: Thanks to Aditya Adiga for leading this project and trusting his ideas to me. Thanks to Matt Farr for comments on this draft. Thanks to Kuil Schoneveld for organizing the project. And thanks to the several friends who tested the MFC. This work was done as part of Groundless’ Autostructures project in the AI Safety Camp.In most security systems the biggest vulnerability is the people involved. A secure password doesn’t help if you leave your computer unlocked in public. Encryption in transit doesn’t protect a file if the key is attached to the same e-mail.The same logic applies to AI alignment. The best theories of human value won’t help a user who chooses (or is pushed) to surround themself with sycophancy and addictive slop. Alignment techniques that work on paper, applied through interfaces that systematically undermine human judgment, will produce bad outcomes regardless of the underlying model’s values. A core requirement of building healthy relationships between humans and AI is therefore the shape each interaction takes. And the standard chatbot format does not meaningfully constrain or scaffold positive interactions.This isn’t a novel observation, but it’s one that has seen limited engineering attention from major labs or the safety community (with some exceptions). Most safety-oriented AI work involves either the AI model directly (alignment and interpretability work) or regulating the deployment of new models (liability frameworks, AI pauses). Even IDE-integration interfaces like Cursor or Claude Code are thin wrappers around chat interfaces, leaving users the task of decomposing their intent into commands. This ignores an important direction for improving AI outcomes: building tools and interfaces that make good use of AI structurally easier than bad use. Not behavioral nudges, but lower level architectural choices that bring meaningful engagement to the forefront and remove the opportunity to stop thinking about your work.If we want to have interactions between humans and future superintelligences that preserve human values and agency, we need interactions with present-day LLMs that do the same.The Problem with Chatbot InteractionsChatbot interfaces aren’t optimized for human interaction. The “assistant” framing came from a safety research framing, not from a user study or the field of HCI. In fact: [The first people to describe “The Assistant”] don’t make any kind of argument to the effect that this is “the right way” to interact with a language model. They don’t even argue that it’s an especially good way to interact with a language model – though in fact it would become the most popular one by far, later on. The foundational description of the model through which everyone interacts with AI has zero instances of the terms “UXR”, “HCI”, “user study”, or even “UI”, and cites zero references on interface design. Nor does the paper for the release of GPT-2.[1]The Honest, Helpful, Harmless assistant has taken over without any alternative interfaces apparently considered. And in order to scale RLHF training even serious assessments of these factors is sacrificed for surface characteristics like agreeableness, causing problems like sycophancy. In addition, the presentation as a chat interface mimics interactions with humans, leading to more anthropomorphism and completely burying the gap between capabilities a model has and doesn’t have. Rather than mimicking a social connection, what would it look like for an LLM-powered app to be an environment that keeps you focused on your chosen priorities?One necessary characteristic is that the correspondence between your goals and the AI’s actions and produced artifacts would need to be central in every moment. It’s incoherent for an LLM to assess whether its output corresponds to what you “actually meant.” Chatbots can attempt to rebuild this purpose discovery process, but that relies on the model to have the correct kind of conversation–and the chat log text being imitated doesn’t select for the kind of deep purpose matching that’s necessary for complex projects. Even machine-verified software, without detailed human engagement, is no guarantee. LLM-generated Lean4 code without line-by-line oversight may simply be verifying that 2+2=4. Absolutely valid and true, but completely irrelevant to your original idea. Since this criterion is both necessary and absent, it is a natural starting place for designing a different kind of AI interaction.One Structured WorkflowThe Metaformalism Copilot[2] is an attempt to build an interface that keeps human understanding and human choices central in AI-assisted project work.We started by designing around a specific workflow for mathematical and logical claims that fit our needs. This established some constraints on design rather than aiming for an “everything app” that works for anyone. I’ll discuss those constraints and how the design adapts to this workflow next, but if you don’t work with mathematical proofs skip ahead to the section “Casual use”.Source -> DecompositionThe input, whether it’s a paper, a blog post, a conversation transcript, or a dashed off thought, is decomposed into a dependency graph of propositions. This includes definitions, supporting lemmas, and claims as theorems. This step forces the overall structure to be visible, and editable, as well as breaking down deeper verification into smaller chunks which can be handled in a single sitting.Proposition -> Semiformal proofEach node in the graph is a proposition which can be written as formal mathematics. Definitions should be made precise, their exact limits and inputs made explicit, while retaining human-readable formatting such as LaTeX math rendering. This is both a checkpoint at which the human retains the connection between the proposition as a piece of the decomposed argument, and a prompt generator for improving the next step. This argument can be refined both manually and via inline AI edits.Semiformal proof -> Lean4 Code & VerificationThe semiformal proof is then translated into machine-verifiable Lean4 code, which can be compiled and verified via a Docker service. The verification can either succeed, or return failure messages for both user and AI re-writes. By progressing through the decomposed dependency tree in a topological order, dependencies can be written as code and compiled separately, making both the process of reading and understanding the proof-code correspondence easier, and giving targeted feedback on problems when verification fails. The interface has specific affordances for (1) focusing on individual sections of argument, (2) grounding and justifying those sections, rather than forcing a tool switch for following hyperlinks or running programs outside of the chat interface, (3) tracking overall progress in a serialized object. These are all possible with a chat interface, but doing so requires additional layers of user choice and model trust.This workflow accommodates not only mathematical/logical claims and proofs, but also empirical and statistical claims–grounding in verification by running statistical tests on evidence rather than Lean4 code verification. Dependency in empirical claims is generally less tightly coupled than in mathematical claims, but tracking both the strength of relationships and the confidence level of evidence for each point means the decomposition provides commensurate value, appropriate to the type of the claim.Lean Verification as a Trust Chain LinkI wrote a more complete argument about compiled trust chains previously, but in brief:Lean verification gives one of the most reliable guarantees of correctness we can access as a society. But what it guarantees is correct is very narrow: just the code that is written. It doesn’t, and can’t, tell you whether the written code corresponds to your intended idea. It doesn’t, and can’t, tell you whether the required axioms are appropriate. And it doesn’t, and can’t, tell you whether the idea being verified corresponds to any claim about the real world.This interface clearly communicates to you the bounds on every piece of AI generated text or code. It keeps you focused on work only you can do. And it attempts to support isolating each step of that work to make you as effective as possible, whether that step is in translating the idea faithfully, the broad structure of the argument, or the correctness of individual claims.Evidence GroundingFor empirical claims, Lean verification can be replaced by structured integration of evidence. Chatbot-assisted research can make confident claims, but has no structure for grounding those claims in evidence. Chatbots can cite evidence, but whether the cited evidence matches the claim, and whether it is a representative survey of possible evidence, and even whether the citation exists at all, must be verified without tools from the chatbot interface.Standard RAG can improve results, but it doesn’t create a clean chain of trust to make clear why claims are made or how confident we should be in them.In the metaformalism co-agent, the workflow is:Generate statistical models or potential counterexamples to written ideas. This process generates specific hypotheses marked as such, which can be edited and expanded to match what the user intends to test.Conduct a specific search of the OpenAlex academic archive for relevant papers, using a transparent and editable query.In upcoming features, the LLM will automatically generate separate scores for the reliability of these studies–highlighting the specific methodology, the effect sizes and p-values, and common red flags–and for the relatedness of the study. Both of these scores will be presented as editable suggestions, so that the user’s judgment is centered and supported, providing visibility only into real results in a transparently replicable way.The AI can then generate structured diff proposals for the hypotheses to validate, invalidate, or specify numerical values–but each diff is presented for specific user-approval so that the user remains aware and in control of every claim being analyzed.Casual UseNot every argument is appropriate for machine-verified mathematical proof. Not all work relies on having methodologically vetted scientific studies behind it. I’ve highlighted these features because the meaning and correctness of chains of trust are legible for these uses, and clear boundaries between work that can or should be automated and work that cannot makes structured implementation satisfying.But the actual moment-to-moment usage of this tool isn’t about technical details. It’s about changing the “default settings” of chat to avoid failure modes. Things like:Presenting generated text as an unexamined result of the user’s actions rather than as the output of a fictional personaAutomatically scoping context for text generation to the current, directly relevant taskStructured critiques available as single button presses, rather than copy-pastes of large text blocks; evaluation of generated text as a tooling-supported expectation rather than as an afterthoughtBuilding citations from literature searches to enforce existence of the link destinationI have found this interface to be helpful many times without verifying my text. I have also adapted some of the pieces as skills and tools for my claude code usage, and I encourage others to take small steps like this even if you don’t want to use the interface.The key design choice is that AI generates drafts of content and fills in details, so that human time is spent entirely on trust. That includes both the faithfulness of how the idea has been written to the user’s conception, and the accuracy or validity of the idea. As opposed to a coding agent, which replaces or minimizes human work to create an end state artifact, the objective is to focus human attention on both the most important and the most interesting parts of a task. The most interesting in that it is only blocked on what the user chooses to correct, and the most important in that Lean4 code generated by an LLM without this level of inspection has no relationship to the user’s intent. Learning on the RoadLean generation often fails–adjusting prompts fixes some common failures but surfacing the specific errors and being able to iterate is important.Decomposition of arguments is tricky–the current setup doesn’t consistently decompose as finely as I’d like, especially because the initial input may need to be expanded considerably before every piece of the breakdown is visible.Making tons of API calls can get expensive–especially if decomposition fails and some of the calls have 100k token inputs. This is now explicitly tracked with tooltips showing estimated costs of each button press and warnings for calls past a certain threshold.Using multiple formalization lenses and recursing is often helpful, but making the interface track the various types of versioning and comparison that came up is a non trivial challenge.Open ProblemsThe tool is open source, available for use here. While the tool has matured enough to be useful for me in some circumstances, there are still many improvements to be made, such as:Professional UX designBetter session and artifact management for side-by-side views and trackingImprovements to OpenAlex search query generation and study assessment promptsBetter matching UI between Lean4 code and semiformal proof stepsMore convenient methods for exporting work–especially suggested edits to papers and test suites for starting software projectsIf you’re interested in the design-and-infrastructure layer of AI safety and alignment, check out other posts on Live Theory and Groundless’ other AISC projects.CodaI hope that experiencing specific alternatives to the chat interface can help guide us toward options that are even better in the future. If you build tools with LLMs, consider what the intended workflow is for an actual user, and build an interface that directly supports that workflow rather than just tacking on chat.^Or InstructGPT. Sparrow cites a handful of HCI papers, though none of them directly engage with the chat framing. Askell does reference HCI in the 2019 call for social scientists in AI safety.^Planned to rename to Metaformalism Co-Agent, but we haven’t updated the docsDiscuss Read More
Sculpted Interaction: a Design-First Approach to AI Alignment
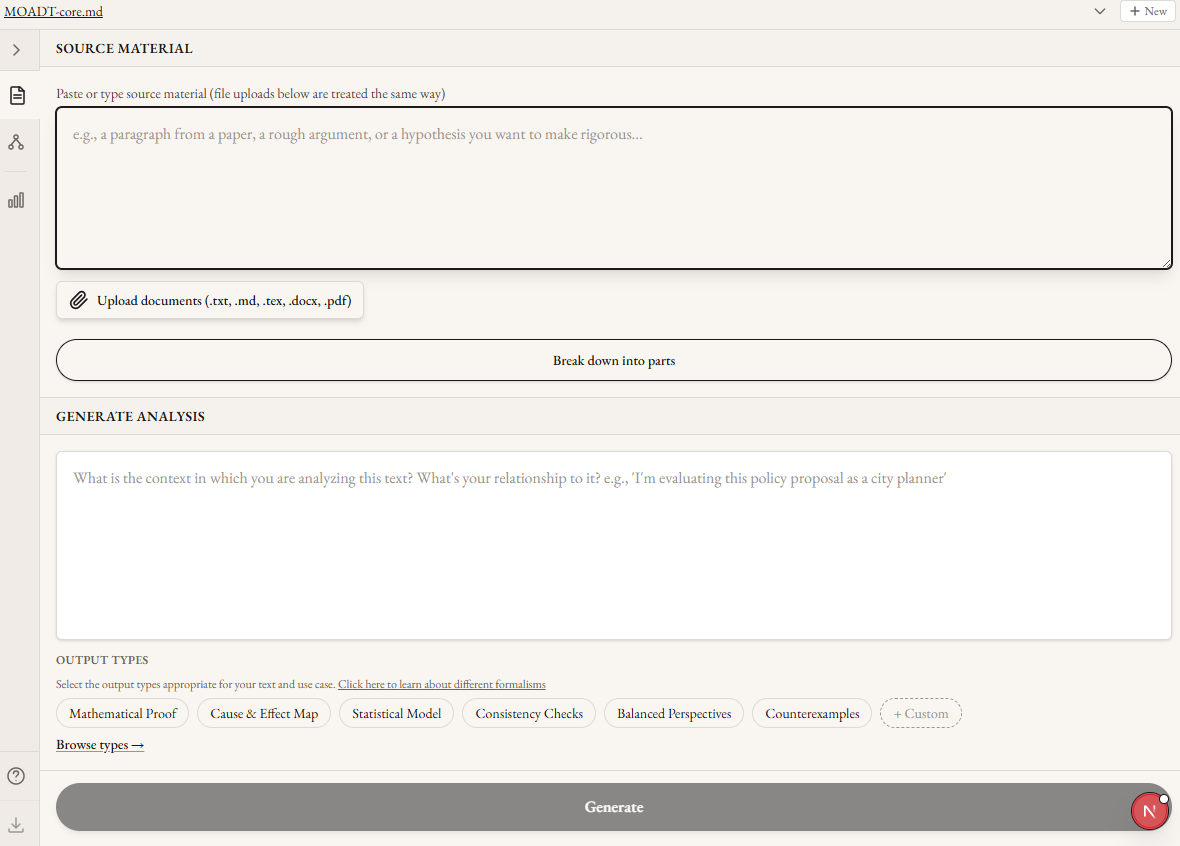
Acknowledgments: Thanks to Aditya Adiga for leading this project and trusting his ideas to me. Thanks to Matt Farr for comments on this draft. Thanks to Kuil Schoneveld for organizing the project. And thanks to the several friends who tested the MFC. This work was done as part of Groundless’ Autostructures project in the AI Safety Camp.In most security systems the biggest vulnerability is the people involved. A secure password doesn’t help if you leave your computer unlocked in public. Encryption in transit doesn’t protect a file if the key is attached to the same e-mail.The same logic applies to AI alignment. The best theories of human value won’t help a user who chooses (or is pushed) to surround themself with sycophancy and addictive slop. Alignment techniques that work on paper, applied through interfaces that systematically undermine human judgment, will produce bad outcomes regardless of the underlying model’s values. A core requirement of building healthy relationships between humans and AI is therefore the shape each interaction takes. And the standard chatbot format does not meaningfully constrain or scaffold positive interactions.This isn’t a novel observation, but it’s one that has seen limited engineering attention from major labs or the safety community (with some exceptions). Most safety-oriented AI work involves either the AI model directly (alignment and interpretability work) or regulating the deployment of new models (liability frameworks, AI pauses). Even IDE-integration interfaces like Cursor or Claude Code are thin wrappers around chat interfaces, leaving users the task of decomposing their intent into commands. This ignores an important direction for improving AI outcomes: building tools and interfaces that make good use of AI structurally easier than bad use. Not behavioral nudges, but lower level architectural choices that bring meaningful engagement to the forefront and remove the opportunity to stop thinking about your work.If we want to have interactions between humans and future superintelligences that preserve human values and agency, we need interactions with present-day LLMs that do the same.The Problem with Chatbot InteractionsChatbot interfaces aren’t optimized for human interaction. The “assistant” framing came from a safety research framing, not from a user study or the field of HCI. In fact: [The first people to describe “The Assistant”] don’t make any kind of argument to the effect that this is “the right way” to interact with a language model. They don’t even argue that it’s an especially good way to interact with a language model – though in fact it would become the most popular one by far, later on. The foundational description of the model through which everyone interacts with AI has zero instances of the terms “UXR”, “HCI”, “user study”, or even “UI”, and cites zero references on interface design. Nor does the paper for the release of GPT-2.[1]The Honest, Helpful, Harmless assistant has taken over without any alternative interfaces apparently considered. And in order to scale RLHF training even serious assessments of these factors is sacrificed for surface characteristics like agreeableness, causing problems like sycophancy. In addition, the presentation as a chat interface mimics interactions with humans, leading to more anthropomorphism and completely burying the gap between capabilities a model has and doesn’t have. Rather than mimicking a social connection, what would it look like for an LLM-powered app to be an environment that keeps you focused on your chosen priorities?One necessary characteristic is that the correspondence between your goals and the AI’s actions and produced artifacts would need to be central in every moment. It’s incoherent for an LLM to assess whether its output corresponds to what you “actually meant.” Chatbots can attempt to rebuild this purpose discovery process, but that relies on the model to have the correct kind of conversation–and the chat log text being imitated doesn’t select for the kind of deep purpose matching that’s necessary for complex projects. Even machine-verified software, without detailed human engagement, is no guarantee. LLM-generated Lean4 code without line-by-line oversight may simply be verifying that 2+2=4. Absolutely valid and true, but completely irrelevant to your original idea. Since this criterion is both necessary and absent, it is a natural starting place for designing a different kind of AI interaction.One Structured WorkflowThe Metaformalism Copilot[2] is an attempt to build an interface that keeps human understanding and human choices central in AI-assisted project work.We started by designing around a specific workflow for mathematical and logical claims that fit our needs. This established some constraints on design rather than aiming for an “everything app” that works for anyone. I’ll discuss those constraints and how the design adapts to this workflow next, but if you don’t work with mathematical proofs skip ahead to the section “Casual use”.Source -> DecompositionThe input, whether it’s a paper, a blog post, a conversation transcript, or a dashed off thought, is decomposed into a dependency graph of propositions. This includes definitions, supporting lemmas, and claims as theorems. This step forces the overall structure to be visible, and editable, as well as breaking down deeper verification into smaller chunks which can be handled in a single sitting.Proposition -> Semiformal proofEach node in the graph is a proposition which can be written as formal mathematics. Definitions should be made precise, their exact limits and inputs made explicit, while retaining human-readable formatting such as LaTeX math rendering. This is both a checkpoint at which the human retains the connection between the proposition as a piece of the decomposed argument, and a prompt generator for improving the next step. This argument can be refined both manually and via inline AI edits.Semiformal proof -> Lean4 Code & VerificationThe semiformal proof is then translated into machine-verifiable Lean4 code, which can be compiled and verified via a Docker service. The verification can either succeed, or return failure messages for both user and AI re-writes. By progressing through the decomposed dependency tree in a topological order, dependencies can be written as code and compiled separately, making both the process of reading and understanding the proof-code correspondence easier, and giving targeted feedback on problems when verification fails. The interface has specific affordances for (1) focusing on individual sections of argument, (2) grounding and justifying those sections, rather than forcing a tool switch for following hyperlinks or running programs outside of the chat interface, (3) tracking overall progress in a serialized object. These are all possible with a chat interface, but doing so requires additional layers of user choice and model trust.This workflow accommodates not only mathematical/logical claims and proofs, but also empirical and statistical claims–grounding in verification by running statistical tests on evidence rather than Lean4 code verification. Dependency in empirical claims is generally less tightly coupled than in mathematical claims, but tracking both the strength of relationships and the confidence level of evidence for each point means the decomposition provides commensurate value, appropriate to the type of the claim.Lean Verification as a Trust Chain LinkI wrote a more complete argument about compiled trust chains previously, but in brief:Lean verification gives one of the most reliable guarantees of correctness we can access as a society. But what it guarantees is correct is very narrow: just the code that is written. It doesn’t, and can’t, tell you whether the written code corresponds to your intended idea. It doesn’t, and can’t, tell you whether the required axioms are appropriate. And it doesn’t, and can’t, tell you whether the idea being verified corresponds to any claim about the real world.This interface clearly communicates to you the bounds on every piece of AI generated text or code. It keeps you focused on work only you can do. And it attempts to support isolating each step of that work to make you as effective as possible, whether that step is in translating the idea faithfully, the broad structure of the argument, or the correctness of individual claims.Evidence GroundingFor empirical claims, Lean verification can be replaced by structured integration of evidence. Chatbot-assisted research can make confident claims, but has no structure for grounding those claims in evidence. Chatbots can cite evidence, but whether the cited evidence matches the claim, and whether it is a representative survey of possible evidence, and even whether the citation exists at all, must be verified without tools from the chatbot interface.Standard RAG can improve results, but it doesn’t create a clean chain of trust to make clear why claims are made or how confident we should be in them.In the metaformalism co-agent, the workflow is:Generate statistical models or potential counterexamples to written ideas. This process generates specific hypotheses marked as such, which can be edited and expanded to match what the user intends to test.Conduct a specific search of the OpenAlex academic archive for relevant papers, using a transparent and editable query.In upcoming features, the LLM will automatically generate separate scores for the reliability of these studies–highlighting the specific methodology, the effect sizes and p-values, and common red flags–and for the relatedness of the study. Both of these scores will be presented as editable suggestions, so that the user’s judgment is centered and supported, providing visibility only into real results in a transparently replicable way.The AI can then generate structured diff proposals for the hypotheses to validate, invalidate, or specify numerical values–but each diff is presented for specific user-approval so that the user remains aware and in control of every claim being analyzed.Casual UseNot every argument is appropriate for machine-verified mathematical proof. Not all work relies on having methodologically vetted scientific studies behind it. I’ve highlighted these features because the meaning and correctness of chains of trust are legible for these uses, and clear boundaries between work that can or should be automated and work that cannot makes structured implementation satisfying.But the actual moment-to-moment usage of this tool isn’t about technical details. It’s about changing the “default settings” of chat to avoid failure modes. Things like:Presenting generated text as an unexamined result of the user’s actions rather than as the output of a fictional personaAutomatically scoping context for text generation to the current, directly relevant taskStructured critiques available as single button presses, rather than copy-pastes of large text blocks; evaluation of generated text as a tooling-supported expectation rather than as an afterthoughtBuilding citations from literature searches to enforce existence of the link destinationI have found this interface to be helpful many times without verifying my text. I have also adapted some of the pieces as skills and tools for my claude code usage, and I encourage others to take small steps like this even if you don’t want to use the interface.The key design choice is that AI generates drafts of content and fills in details, so that human time is spent entirely on trust. That includes both the faithfulness of how the idea has been written to the user’s conception, and the accuracy or validity of the idea. As opposed to a coding agent, which replaces or minimizes human work to create an end state artifact, the objective is to focus human attention on both the most important and the most interesting parts of a task. The most interesting in that it is only blocked on what the user chooses to correct, and the most important in that Lean4 code generated by an LLM without this level of inspection has no relationship to the user’s intent. Learning on the RoadLean generation often fails–adjusting prompts fixes some common failures but surfacing the specific errors and being able to iterate is important.Decomposition of arguments is tricky–the current setup doesn’t consistently decompose as finely as I’d like, especially because the initial input may need to be expanded considerably before every piece of the breakdown is visible.Making tons of API calls can get expensive–especially if decomposition fails and some of the calls have 100k token inputs. This is now explicitly tracked with tooltips showing estimated costs of each button press and warnings for calls past a certain threshold.Using multiple formalization lenses and recursing is often helpful, but making the interface track the various types of versioning and comparison that came up is a non trivial challenge.Open ProblemsThe tool is open source, available for use here. While the tool has matured enough to be useful for me in some circumstances, there are still many improvements to be made, such as:Professional UX designBetter session and artifact management for side-by-side views and trackingImprovements to OpenAlex search query generation and study assessment promptsBetter matching UI between Lean4 code and semiformal proof stepsMore convenient methods for exporting work–especially suggested edits to papers and test suites for starting software projectsIf you’re interested in the design-and-infrastructure layer of AI safety and alignment, check out other posts on Live Theory and Groundless’ other AISC projects.CodaI hope that experiencing specific alternatives to the chat interface can help guide us toward options that are even better in the future. If you build tools with LLMs, consider what the intended workflow is for an actual user, and build an interface that directly supports that workflow rather than just tacking on chat.^Or InstructGPT. Sparrow cites a handful of HCI papers, though none of them directly engage with the chat framing. Askell does reference HCI in the 2019 call for social scientists in AI safety.^Planned to rename to Metaformalism Co-Agent, but we haven’t updated the docsDiscuss Read More
Related Posts

Introducing the Mox Guest Program
Published on October 1, 2025 6:35 PM GMTTL;DR: Mox, a community space and incubator in…
Letter to Heads of AI labs
Published on October 11, 2025 7:43 AM GMTThis letter is addressed To Elon Musk To…
Introducing ControlArena: A library for running AI control experiments
Published on October 24, 2025 9:51 AM GMTThis has been a collaborative effort between UK…