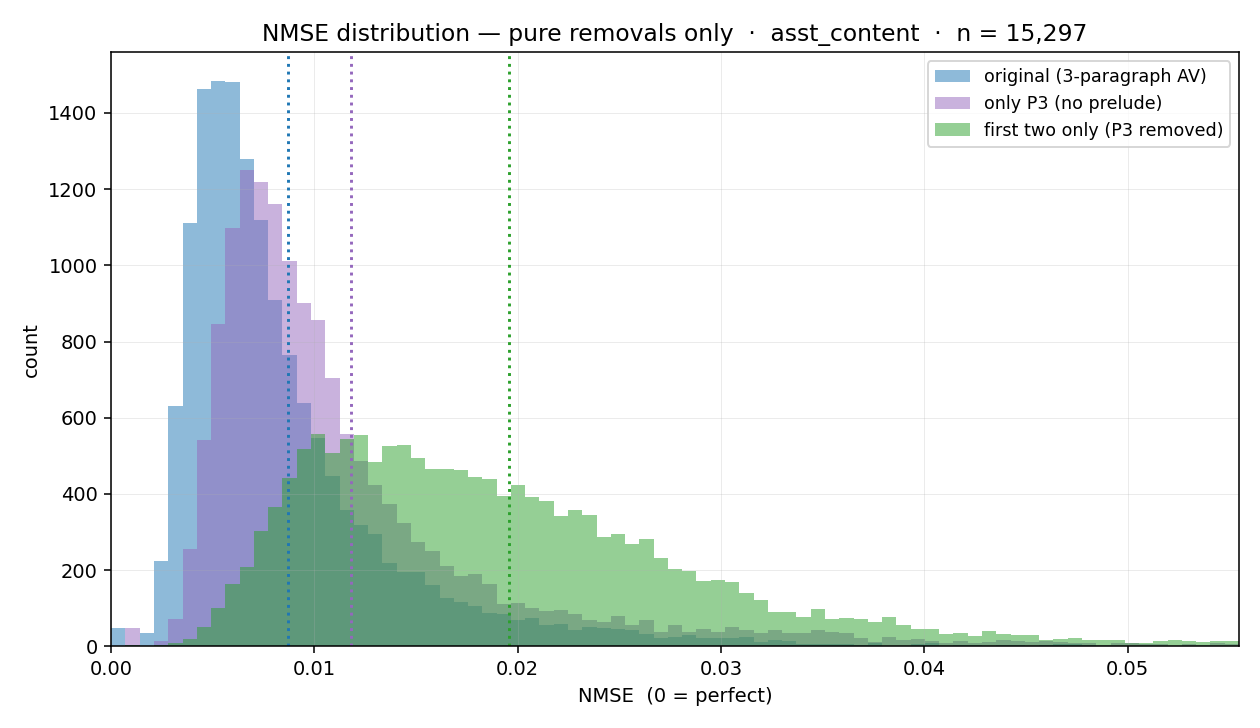
Tl;drConvergent abstraction hypothesis posits abstractions are often convergent in the sense of convergent evolution: different cognitive systems converge on the same abstraction, when facing similar selection pressures and learning in similar environments. It is a less ambitious alternative to ‘natural abstractions hypotheses’ and, in my view, more likely to be true. Convergence may be real, useful, and empirically robust, while still being contingent and fragile under changes in architecture, training pressure, or optimization regime. Convergent evolution To recapitulate some basics: notice that sharks, ichthyosaurs and dolphins look remarkably similar, despite their ancestors being wildly different.This is a case of convergent evolution: the process by which organisms with different origins develop similar features. Both sharks and dolphins needed speed and energy efficiency when moving in an environment governed by the laws of hydrodynamics, and so they converged on a pretty similar body shape.A complementary concept from biology is contingency – convergent features are themselves often contingent on some other feature. For example, the shark morphology depends on there being a central vertebral column (or spine), which only evolved once and is the defining feature of vertebrates. There are many other aquatic predators, such as squid and octopuses, which are not vertebrates and thus have evolved a completely different morphology. Convergent evolution applied to abstractions“Abstractions” are somewhat different from morphological features, but there is an analogy between evolution and learning in systems like SGD acting on neural networks, and most of the conceptual framework can be directly applied. Based on the analogy, we expect convergence when the learners face a similar data environment, similar selection pressures, try to do similar things, and the solution space is somewhat limited. Selection pressuresIn case of abstractions, some of the strongest selection pressures are highly universal:All physical systems doing some sort of cognition or computation in this universe pay for negentropy, consequently computation is not free, and is bounded. Consequently, we can learn a lot about what makes abstractions good just from information theory. A strong selection pressure for abstractions is basically “what is a good compression of data” and similar.Compression buys you a lotConcepts are clusters in thingspace. But clustering is compression: instead of remembering details about each point in the cluster, you can remember just the pointer to the cluster, and the differences. Objects are compressions. Instead of repeating the same description over and over, you remember just a few degrees of freedom. It is a very impressive compression: Consider an atomically precise representation of an apple: in some physics-grounded representation it has ~10^25 degrees of freedom, held by a comparably large number of constraints. But the world has approximate symmetries – translation invariance, rotation invariance, and so on. So one useful compression is to treat the apple as an object. A handful of variables like position and momentum often suffice. The compression ratio is enormous, and I expect basic abstractions like bodies in space to be highly convergent across world-modeling processes, including animal brains, human brains, video codecs, visual ML models.Many more mathematical abstractions are effective low-length compression algorithms. Arithmetic is a reusable compression. Once you learn that 3 + 2 = 5, you do not need separate facts for apples, oranges, sheep, coins, and photons. The same structure transfers across domains.PCA is compression, transforms to frequency domain are often useful for compression, quantization is compression, singular value decomposition is compression, random low dimensional projections are compression.Once you look for it, you see the fundamental selection pressure to save bits everywhere. [1]Shared environmentsThe second ingredient for convergence is a shared data environment. We can distinguish between different levels:- Physics: All cognitive systems embedded in our universe encounter the same fundamental regularities, like objects that persist over time, causal relationships, 4d spatial structure, Noether’s theorem induced conservation laws.- Similar scale: Human world models are “centered” around scales like 1m, 1s, 1kg. – Sensors: vision-heavy agents learn different abstractions from sonar-heavy or smell-heavy agents.- Human/linguistic environment: For systems learning from human-generated data, there’s an additional layer of shared environment. What this predictsImagine aliens landed on Earth. I would expect aliens embedded in the same physics to discover arithmetic, geometry, approximate objects, causal structure, and frame transformations. If they live at similar scales and act in similar environments, I would also expect them to use categories resembling solid objects, liquids, containers, paths, agents, tools, obstacles, boundaries, markets. If they study Earth or train on human data, I would expect more convergence: apples, chairs, money, smiles, promises.Now: alien minds actually have landed. And yes, even if you start with raw photographs and fairly universal neural network architecture, you get apples.What this does not predict, or contingency in abstraction spaceThe dual to convergence is contingency – or, what are abstractions contingent on?At one extreme, you might imagine abstractions are contingent only on physics. I don’t think that’s the case. The interesting work is mapping the interplay of convergence and contingency in detail. Case study of architectural contingency: convergent vision abstractionsOne of the best examples of how I understand both convergence and contingency in ML comes from a paper on adversarial robustness in image classification by Fort at al.Standard image classifiers learn abstractions that largely agree with human vision: show them an apple, they say “apple”, if trained on that, or learn a concept of apple, if trained in a self-supervised way. But the agreement turns out to be superficial. Put the represenational alignment under a very small amount of adversarial optimization pressure, and you get adversarial inputs: pictures where the neural net confidently sees a “toaster” where we see an apple. What we see as barely perceptible noise, the network sees as the essence of toaster-likeness.What this illustrates is that the classifier learned a somewhat different abstraction than humans; the abstractions are aligned on natural images but diverge fast under pressure. The pressure is usually conceived as adversarial, but if you optimize for an image to make it maximally apple-like, you also get divergence.Fort et deal with adversarial attacks by training classifiers on multi-resolution inputs, stacking downsampled versions of the same image at different scales, and requiring the classification stays consistent across scales. Empirically, the resulting abstractions align dramatically better with human ones. The paper result is mostly framed as massively increased adversarial robustness, but what I find more interesting is that the remaining “adversarial attacks” against these multi-resolution models produce easily human interpretable changes. To turn a “cloud” into a “mountain,” the attack adds a dark contour and repurposes the cloud’s white pixels as snow. To turn an “elephant” into a “dinosaur,” it recolors the elephant green and adds spikes. Humans recognize the changes as making the image more mountain-like or dinosaur-like.In the convergency/contingency language, it turns out the human-like visual abstractions of mountains and elephants are convergent, given the data being images on the internet, but contingent on the architecture having some sort of resolution-free/scale-invariance constraint. Architectural contingency is one kind. There’s also developmental – higher-level abstractions are likely contingent on lower-level ones, analogous to shark morphology depending on the vertebral column. I won’t develop this hereWhat’s the difference between convergent abstractions and natural abstractionsNatural-abstraction work often bundles two ideas: first, that the world supports low-dimensional summaries useful across many contexts; second, that many cognitive systems converge on those summaries. I want to separate these. CAH accepts the convergence phenomenon, but treats it as a fact about learning processes under shared pressures, not automatically as evidence that the abstraction is mostly situated in the structure of the world (abstraction correspond to low-dimensional summaries of information relevant far away from a subsystem)The canonical motivating example for natural abstractions is gas, and state variables like temperature as the abstractions. The ambition of the research program is to have a principled way to identify them. The natural abstraction hypothesis has roughly physics aesthetics. In contrast, convergent abstraction makes mostly a process claim: given similar pressures and environments, similar abstractions emerge. The ambition is to understand basins of convergence, contingencies, and the ways how the structures in the world interact with the learners. The aesthetics is way closer to biology, and assumes messiness. It is less ambitious.Most empirical evidence for natural abstractions (or its academic relative, the platonic representation hypothesis) is well explained by convergent abstraction: convergence is the weaker claim. But the reverse isn’t true – evidence that similar systems converge doesn’t tell you the abstractions are features of the world at distance rather than features of similarly-pressured learners.From the CAH perspective, natural-latent results identify one important source of convergence: cases where the world itself supplies stable, low-dimensional mediators. But they do not settle the broader question of which abstractions particular learners will use, or how robustly those abstractions survive changes in architecture, objective, or optimization pressure.Why do I careIn my view, the difference between natural and convergent abstractions is a deep crux of multiple pressing questions of AI strategy. I’ll cover the possibility and implications of convergent moral abstractions in a future post, but to give one example:Models like Claude Opus 3 lead some to believe that the training process is able to find a fairly general and possibly natural abstraction of good. If this is the case, and the abstraction is truly natural, it is good news for alignment, chances that “hand over” to AIs leads to good outcomes are better, and there may be also a risk from not handing over, or human alignment efforts re-aligning the AIs away from goodness toward parochial goals.In contrast, if the abstractions AIs like Opus learn are only convergent in some narrow basin, the strategic situation is much more fragile. Similarly to the case of apples, the human and AI abstractions of goodness may overlap and even agree in a very large number of directions, and at the same time the representational alignment could be only partial and fragile. In this picture, while Opus 3 may be genuinely good, if its abstractions become load-bearing, the setup will be brittle. Adversarial optimization, or even just strong optimization, could exploit the differences. Directionally, this makes prospects of more RL in post-training scary, the success of iterated amplification / CEV of Opus less likely, and overall pushes against handovers.If the moral abstractions Opus learned are natural in a strong sense, we’re in the world where some part of alignment might basically work – pointing a smart enough learner at human data converges to abstractions close enough to goodness. If they’re convergent, we’re in the world where some part of alignment might basically work, but also there are many words where it looks like it works, but ultimately it doesn’t. When the abstractions become load-bearing and optimization strong, they diverge.I don’t know which world we’re in, and I’m worried about people not having the conceptual precision to distinguish.^Zipf’s law of brevity states that more frequently used words are shorterPredictive coding implies the brain primarily transmits prediction errors rather than raw signals, reducing bandwidthWeber-Fechner law is an observation that biological sensory systems encode magnitude logarithmically, which is near-optimal compression for the power-law statistics of natural environmentsCognitive metaphors are compression: instead of building a similar and redundant model, it’s shorter to store the isomorphism.Discuss Read More
Convergent Abstraction Hypothesis
Tl;drConvergent abstraction hypothesis posits abstractions are often convergent in the sense of convergent evolution: different cognitive systems converge on the same abstraction, when facing similar selection pressures and learning in similar environments. It is a less ambitious alternative to ‘natural abstractions hypotheses’ and, in my view, more likely to be true. Convergence may be real, useful, and empirically robust, while still being contingent and fragile under changes in architecture, training pressure, or optimization regime. Convergent evolution To recapitulate some basics: notice that sharks, ichthyosaurs and dolphins look remarkably similar, despite their ancestors being wildly different.This is a case of convergent evolution: the process by which organisms with different origins develop similar features. Both sharks and dolphins needed speed and energy efficiency when moving in an environment governed by the laws of hydrodynamics, and so they converged on a pretty similar body shape.A complementary concept from biology is contingency – convergent features are themselves often contingent on some other feature. For example, the shark morphology depends on there being a central vertebral column (or spine), which only evolved once and is the defining feature of vertebrates. There are many other aquatic predators, such as squid and octopuses, which are not vertebrates and thus have evolved a completely different morphology. Convergent evolution applied to abstractions“Abstractions” are somewhat different from morphological features, but there is an analogy between evolution and learning in systems like SGD acting on neural networks, and most of the conceptual framework can be directly applied. Based on the analogy, we expect convergence when the learners face a similar data environment, similar selection pressures, try to do similar things, and the solution space is somewhat limited. Selection pressuresIn case of abstractions, some of the strongest selection pressures are highly universal:All physical systems doing some sort of cognition or computation in this universe pay for negentropy, consequently computation is not free, and is bounded. Consequently, we can learn a lot about what makes abstractions good just from information theory. A strong selection pressure for abstractions is basically “what is a good compression of data” and similar.Compression buys you a lotConcepts are clusters in thingspace. But clustering is compression: instead of remembering details about each point in the cluster, you can remember just the pointer to the cluster, and the differences. Objects are compressions. Instead of repeating the same description over and over, you remember just a few degrees of freedom. It is a very impressive compression: Consider an atomically precise representation of an apple: in some physics-grounded representation it has ~10^25 degrees of freedom, held by a comparably large number of constraints. But the world has approximate symmetries – translation invariance, rotation invariance, and so on. So one useful compression is to treat the apple as an object. A handful of variables like position and momentum often suffice. The compression ratio is enormous, and I expect basic abstractions like bodies in space to be highly convergent across world-modeling processes, including animal brains, human brains, video codecs, visual ML models.Many more mathematical abstractions are effective low-length compression algorithms. Arithmetic is a reusable compression. Once you learn that 3 + 2 = 5, you do not need separate facts for apples, oranges, sheep, coins, and photons. The same structure transfers across domains.PCA is compression, transforms to frequency domain are often useful for compression, quantization is compression, singular value decomposition is compression, random low dimensional projections are compression.Once you look for it, you see the fundamental selection pressure to save bits everywhere. [1]Shared environmentsThe second ingredient for convergence is a shared data environment. We can distinguish between different levels:- Physics: All cognitive systems embedded in our universe encounter the same fundamental regularities, like objects that persist over time, causal relationships, 4d spatial structure, Noether’s theorem induced conservation laws.- Similar scale: Human world models are “centered” around scales like 1m, 1s, 1kg. – Sensors: vision-heavy agents learn different abstractions from sonar-heavy or smell-heavy agents.- Human/linguistic environment: For systems learning from human-generated data, there’s an additional layer of shared environment. What this predictsImagine aliens landed on Earth. I would expect aliens embedded in the same physics to discover arithmetic, geometry, approximate objects, causal structure, and frame transformations. If they live at similar scales and act in similar environments, I would also expect them to use categories resembling solid objects, liquids, containers, paths, agents, tools, obstacles, boundaries, markets. If they study Earth or train on human data, I would expect more convergence: apples, chairs, money, smiles, promises.Now: alien minds actually have landed. And yes, even if you start with raw photographs and fairly universal neural network architecture, you get apples.What this does not predict, or contingency in abstraction spaceThe dual to convergence is contingency – or, what are abstractions contingent on?At one extreme, you might imagine abstractions are contingent only on physics. I don’t think that’s the case. The interesting work is mapping the interplay of convergence and contingency in detail. Case study of architectural contingency: convergent vision abstractionsOne of the best examples of how I understand both convergence and contingency in ML comes from a paper on adversarial robustness in image classification by Fort at al.Standard image classifiers learn abstractions that largely agree with human vision: show them an apple, they say “apple”, if trained on that, or learn a concept of apple, if trained in a self-supervised way. But the agreement turns out to be superficial. Put the represenational alignment under a very small amount of adversarial optimization pressure, and you get adversarial inputs: pictures where the neural net confidently sees a “toaster” where we see an apple. What we see as barely perceptible noise, the network sees as the essence of toaster-likeness.What this illustrates is that the classifier learned a somewhat different abstraction than humans; the abstractions are aligned on natural images but diverge fast under pressure. The pressure is usually conceived as adversarial, but if you optimize for an image to make it maximally apple-like, you also get divergence.Fort et deal with adversarial attacks by training classifiers on multi-resolution inputs, stacking downsampled versions of the same image at different scales, and requiring the classification stays consistent across scales. Empirically, the resulting abstractions align dramatically better with human ones. The paper result is mostly framed as massively increased adversarial robustness, but what I find more interesting is that the remaining “adversarial attacks” against these multi-resolution models produce easily human interpretable changes. To turn a “cloud” into a “mountain,” the attack adds a dark contour and repurposes the cloud’s white pixels as snow. To turn an “elephant” into a “dinosaur,” it recolors the elephant green and adds spikes. Humans recognize the changes as making the image more mountain-like or dinosaur-like.In the convergency/contingency language, it turns out the human-like visual abstractions of mountains and elephants are convergent, given the data being images on the internet, but contingent on the architecture having some sort of resolution-free/scale-invariance constraint. Architectural contingency is one kind. There’s also developmental – higher-level abstractions are likely contingent on lower-level ones, analogous to shark morphology depending on the vertebral column. I won’t develop this hereWhat’s the difference between convergent abstractions and natural abstractionsNatural-abstraction work often bundles two ideas: first, that the world supports low-dimensional summaries useful across many contexts; second, that many cognitive systems converge on those summaries. I want to separate these. CAH accepts the convergence phenomenon, but treats it as a fact about learning processes under shared pressures, not automatically as evidence that the abstraction is mostly situated in the structure of the world (abstraction correspond to low-dimensional summaries of information relevant far away from a subsystem)The canonical motivating example for natural abstractions is gas, and state variables like temperature as the abstractions. The ambition of the research program is to have a principled way to identify them. The natural abstraction hypothesis has roughly physics aesthetics. In contrast, convergent abstraction makes mostly a process claim: given similar pressures and environments, similar abstractions emerge. The ambition is to understand basins of convergence, contingencies, and the ways how the structures in the world interact with the learners. The aesthetics is way closer to biology, and assumes messiness. It is less ambitious.Most empirical evidence for natural abstractions (or its academic relative, the platonic representation hypothesis) is well explained by convergent abstraction: convergence is the weaker claim. But the reverse isn’t true – evidence that similar systems converge doesn’t tell you the abstractions are features of the world at distance rather than features of similarly-pressured learners.From the CAH perspective, natural-latent results identify one important source of convergence: cases where the world itself supplies stable, low-dimensional mediators. But they do not settle the broader question of which abstractions particular learners will use, or how robustly those abstractions survive changes in architecture, objective, or optimization pressure.Why do I careIn my view, the difference between natural and convergent abstractions is a deep crux of multiple pressing questions of AI strategy. I’ll cover the possibility and implications of convergent moral abstractions in a future post, but to give one example:Models like Claude Opus 3 lead some to believe that the training process is able to find a fairly general and possibly natural abstraction of good. If this is the case, and the abstraction is truly natural, it is good news for alignment, chances that “hand over” to AIs leads to good outcomes are better, and there may be also a risk from not handing over, or human alignment efforts re-aligning the AIs away from goodness toward parochial goals.In contrast, if the abstractions AIs like Opus learn are only convergent in some narrow basin, the strategic situation is much more fragile. Similarly to the case of apples, the human and AI abstractions of goodness may overlap and even agree in a very large number of directions, and at the same time the representational alignment could be only partial and fragile. In this picture, while Opus 3 may be genuinely good, if its abstractions become load-bearing, the setup will be brittle. Adversarial optimization, or even just strong optimization, could exploit the differences. Directionally, this makes prospects of more RL in post-training scary, the success of iterated amplification / CEV of Opus less likely, and overall pushes against handovers.If the moral abstractions Opus learned are natural in a strong sense, we’re in the world where some part of alignment might basically work – pointing a smart enough learner at human data converges to abstractions close enough to goodness. If they’re convergent, we’re in the world where some part of alignment might basically work, but also there are many words where it looks like it works, but ultimately it doesn’t. When the abstractions become load-bearing and optimization strong, they diverge.I don’t know which world we’re in, and I’m worried about people not having the conceptual precision to distinguish.^Zipf’s law of brevity states that more frequently used words are shorterPredictive coding implies the brain primarily transmits prediction errors rather than raw signals, reducing bandwidthWeber-Fechner law is an observation that biological sensory systems encode magnitude logarithmically, which is near-optimal compression for the power-law statistics of natural environmentsCognitive metaphors are compression: instead of building a similar and redundant model, it’s shorter to store the isomorphism.Discuss Read More

Related Posts

Leo in me
Published on January 9, 2026 3:55 PM GMTDo you ever wanna be Leonardo Da Vinci…
Status In A Tribe Of One
Published on January 14, 2026 8:44 PM GMTI saw a tweet thread the other day,…

[GDPval] Models Could Automate the U.S. Economy by 2027
Published on September 30, 2025 11:53 AM GMTOpenAI's new GDPval benchmark measures AI capabilities on…