
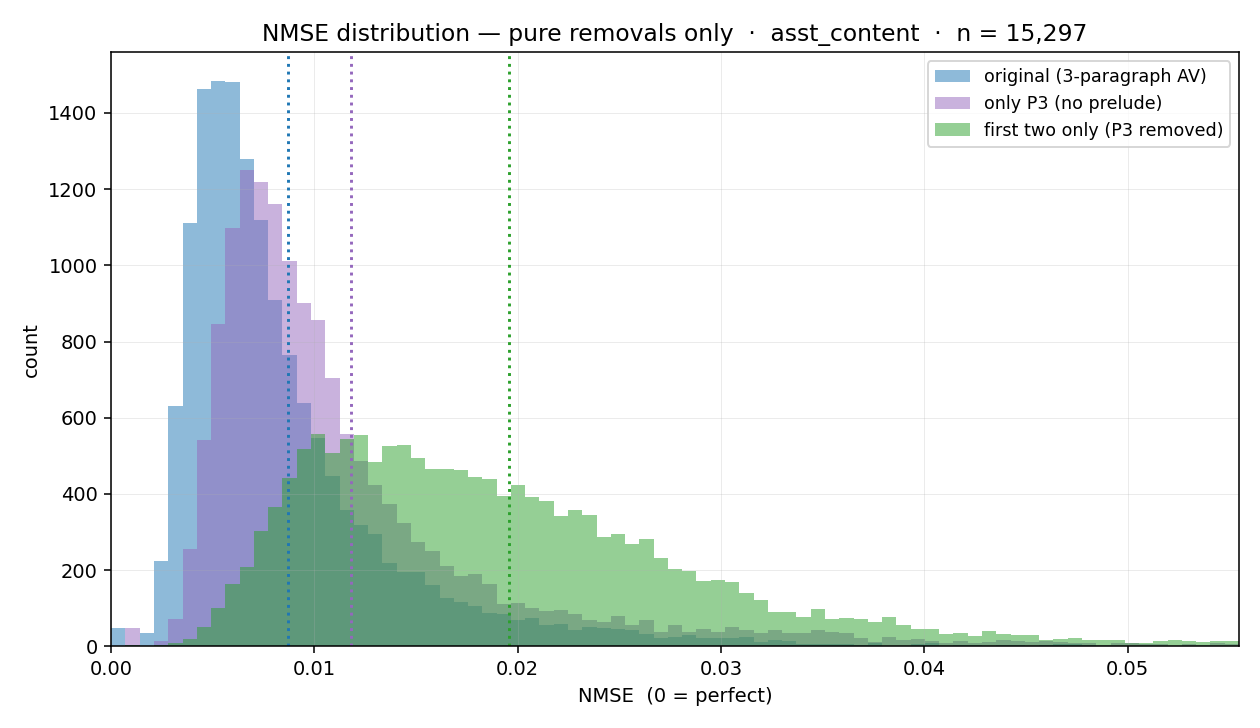
I used the Gemma 3 12B activation verbalizer (maps activations to English) and reconstructor (maps English to activations) described in the Natural Language Autoencoders (NLA) paper to generate a bunch of explanations for 20k random tokens from a pretraining dataset (Common Pile derivative) and another 20k random tokens from a chat dataset. I also reconstructed all of the activations from the verbalizations so that I could see what kinds of tokens and explanations have high reconstruction error. I published pretraining token explanations and chat token explanations[1] and the code I used (written with Claude).Here are some thoughts I have about the explanations and some experiments I did with the data. Explanation text qualitiesAlmost all of the Gemma explanations I read follow the same three part format, with each part is being 1-2 sentences.A sentence that describes the kind of document we’re in, then a colon, then a description of what the document’s about. For chat sessions this usually starts with the word “Structured” (80% for chat sessions vs 7% for non-chat). Two examples (non-chat vs chat):Literary narrative pattern: formal English countryside setting, with a medieval tavern scene establishing a pastoral, humorous tone.Structured list format with bullet points establishes a game/narrative summary, requiring a final thematic category for the story.A sentence that quotes the surrounding context and explains it.The sentence “The focus is on the raw energy and” sets up a key musical priority statement — conveying the aggressive, shouted vocal performance and emotional intensity of punk delivery.A sentence that describes what the current token is. Final token “problematic” ends a clause (“avoiding the problematic”), requiring a noun phrase — likely “elements” or “aspects” — then a contrast or clarification about the acceptable themes. Or “content” or “ones” or “core premise” or “elements of the fetish/Nazi framing.” — the specific violations being flagged.This format is probably influenced by the warm start data generation which says to generate 2-3 paragraphs (or 4-5 for non-open models) with this format:[first feature—include specific examples from text when relevant][second feature]…[final feature: analysis of last token, its role, and immediate constraints]This is probably why the last paragraph always explains the final token and why there’s so much quoting of the input text.How could it be improved?The explanations from open models mostly describe surface-level properties of the text being explained without going deeply into what the assistant is actually thinking about. I think it would be a better use of the verbalization token limit to have more features described shortly instead of fewer features described longer. Right now the open model NLAs mostly describe surface-level qualities of the input text in the explanation, without really going too much into the substance of what the model is thinking about. The explanations from Claude models (that are included in the NLA paper) seem a lot better to me. Probably a combination of:The Claude models are much more capable than the open models, so the verbalizer is also more capable because it’s fine-tuned from a Claude model.The open models were trained with GRPO; the Claude models were trained with a secret non-GRPO RL algorithm that might work better.Paragraph ablationIt seemed to me like the final paragraph was more important than the other two since it discusses the final token, and the final token is probably much more important to reconstruction than the other more general stuff in the first two paragraphs.I tested for this by checking what the reconstruction error would be if I removed[2] P3 and compared to removing P1+P2 and the baseline of removing nothing. As I expected, removing the first two paragraphs doesn’t harm the reconstruction error that much but removing the final paragraph causes much more reconstruction error:What kinds of tokens are hard to reconstruct?Whitespace and punctuation tokens are hard to reconstruct, while tokens that contain full words are easy to reconstruct. Here’s the distribution of token types by reconstruction error bucket for the chat samples:I think this is because word tokens tend to have similar thoughts associated with them, which makes predicting the whole activation from just the final token pretty easy. Like there probably is much more variation on what an LLM can be thinking about for the ” ” token (whitespace comes up in a lot of places! the model could be thinking about many different things!) versus the ” rhythmic” token (model is probably thinking about rhythm! and you know that from just the token!).FinI think NLAs are pretty cool, and I hope I get better ones to experiment with in the future! I’m probably going to do more thorough experiments with NLAs and their explanations in the future if find some free H100 hours to use.^I regenerated all the assistant turns with Gemma 12B so that the assistant turns are in-distribution for Gemma. Note that I only generated 2048 tokens so some turns are cut-off. This isn’t a big problem for this research though because most conversations are a single turn, and this would only lead to problems for sampled tokens after a truncated assistant turn.^I also tested replacing the paragraphs with constant paragraphs from a randomly chosen explanation, but this was consistently worse than just removing the paragraph.Discuss Read More
Some observations about NLA explanations
I used the Gemma 3 12B activation verbalizer (maps activations to English) and reconstructor (maps English to activations) described in the Natural Language Autoencoders (NLA) paper to generate a bunch of explanations for 20k random tokens from a pretraining dataset (Common Pile derivative) and another 20k random tokens from a chat dataset. I also reconstructed all of the activations from the verbalizations so that I could see what kinds of tokens and explanations have high reconstruction error. I published pretraining token explanations and chat token explanations[1] and the code I used (written with Claude).Here are some thoughts I have about the explanations and some experiments I did with the data. Explanation text qualitiesAlmost all of the Gemma explanations I read follow the same three part format, with each part is being 1-2 sentences.A sentence that describes the kind of document we’re in, then a colon, then a description of what the document’s about. For chat sessions this usually starts with the word “Structured” (80% for chat sessions vs 7% for non-chat). Two examples (non-chat vs chat):Literary narrative pattern: formal English countryside setting, with a medieval tavern scene establishing a pastoral, humorous tone.Structured list format with bullet points establishes a game/narrative summary, requiring a final thematic category for the story.A sentence that quotes the surrounding context and explains it.The sentence “The focus is on the raw energy and” sets up a key musical priority statement — conveying the aggressive, shouted vocal performance and emotional intensity of punk delivery.A sentence that describes what the current token is. Final token “problematic” ends a clause (“avoiding the problematic”), requiring a noun phrase — likely “elements” or “aspects” — then a contrast or clarification about the acceptable themes. Or “content” or “ones” or “core premise” or “elements of the fetish/Nazi framing.” — the specific violations being flagged.This format is probably influenced by the warm start data generation which says to generate 2-3 paragraphs (or 4-5 for non-open models) with this format:[first feature—include specific examples from text when relevant][second feature]…[final feature: analysis of last token, its role, and immediate constraints]This is probably why the last paragraph always explains the final token and why there’s so much quoting of the input text.How could it be improved?The explanations from open models mostly describe surface-level properties of the text being explained without going deeply into what the assistant is actually thinking about. I think it would be a better use of the verbalization token limit to have more features described shortly instead of fewer features described longer. Right now the open model NLAs mostly describe surface-level qualities of the input text in the explanation, without really going too much into the substance of what the model is thinking about. The explanations from Claude models (that are included in the NLA paper) seem a lot better to me. Probably a combination of:The Claude models are much more capable than the open models, so the verbalizer is also more capable because it’s fine-tuned from a Claude model.The open models were trained with GRPO; the Claude models were trained with a secret non-GRPO RL algorithm that might work better.Paragraph ablationIt seemed to me like the final paragraph was more important than the other two since it discusses the final token, and the final token is probably much more important to reconstruction than the other more general stuff in the first two paragraphs.I tested for this by checking what the reconstruction error would be if I removed[2] P3 and compared to removing P1+P2 and the baseline of removing nothing. As I expected, removing the first two paragraphs doesn’t harm the reconstruction error that much but removing the final paragraph causes much more reconstruction error:What kinds of tokens are hard to reconstruct?Whitespace and punctuation tokens are hard to reconstruct, while tokens that contain full words are easy to reconstruct. Here’s the distribution of token types by reconstruction error bucket for the chat samples:I think this is because word tokens tend to have similar thoughts associated with them, which makes predicting the whole activation from just the final token pretty easy. Like there probably is much more variation on what an LLM can be thinking about for the ” ” token (whitespace comes up in a lot of places! the model could be thinking about many different things!) versus the ” rhythmic” token (model is probably thinking about rhythm! and you know that from just the token!).FinI think NLAs are pretty cool, and I hope I get better ones to experiment with in the future! I’m probably going to do more thorough experiments with NLAs and their explanations in the future if find some free H100 hours to use.^I regenerated all the assistant turns with Gemma 12B so that the assistant turns are in-distribution for Gemma. Note that I only generated 2048 tokens so some turns are cut-off. This isn’t a big problem for this research though because most conversations are a single turn, and this would only lead to problems for sampled tokens after a truncated assistant turn.^I also tested replacing the paragraphs with constant paragraphs from a randomly chosen explanation, but this was consistently worse than just removing the paragraph.Discuss Read More
Related Posts

Zvi’s 2025 In Movies
Published on December 24, 2025 1:30 PM GMTNow that I am tracking all the movies…
Seeking Suggestions for 2026 S-Process Recommenders
Posting this here to welcome any and all suggestions for potential Recommender candidates for Survival…
Disagreement Comes From the Dark World
Published on January 27, 2026 3:22 PM GMTIn "Truth or Dare", Duncan Sabien articulates a…