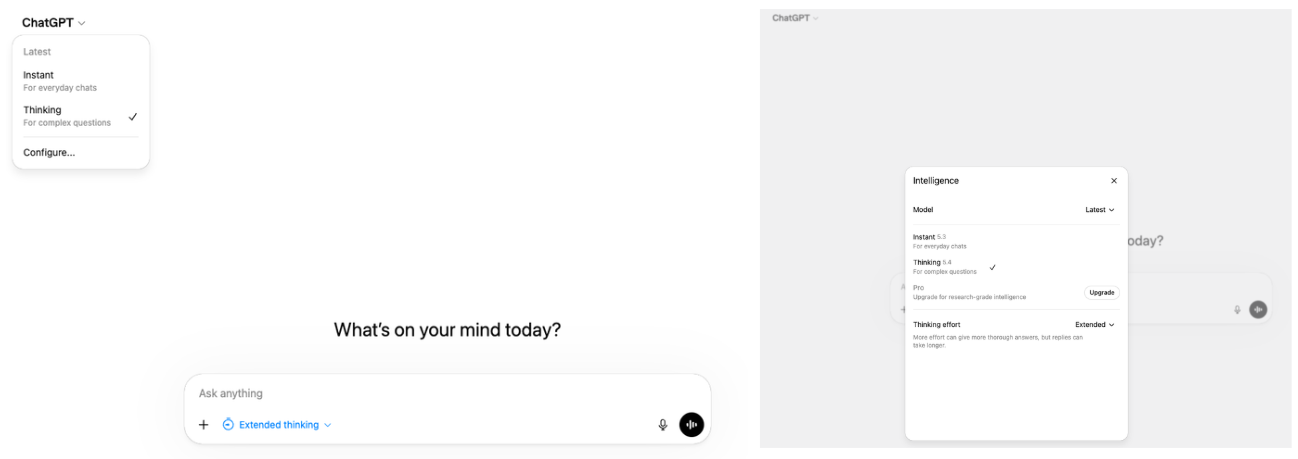
OpenAI has been consistently making it hard to understand what each of their different models are for. Frustratingly, their approach—as indicated by their recent UI decisions in the webapp to hide all settings for model reasoning effort and even the actual model name/type itself under: first, a collapsible element, and then, second, a second-up button for a pop-up menu, which then hides all of their other models (besides the latest) under a third collapsible element/button—to such complaints seems to almost always be to make things even less transparent by hiding even more things behind the UI.Figure 1.1 What it takes now to (a) find what model OpenAI is making you use, (b) how much reasoning effort it is using, (c) change to an actually useful, older reasoning model like o3 that actually reasons, as opposed to ‘adaptively’ only doing so when it can spare compute.[1] 1. Issues/ComplaintsFigure 1.2 What you see on the Codex app when you hover over each model to make its description appear.The short one-liner descriptions in the Codex App that describe each model are really vague and unclear and do not give any information on what each model’s unique value proposition is or what they ‘do best’—which would help a user understand what they ‘do different’ from any of the other models.All of the descriptions just seem like word salads or like someone fed an LLM a prompt to randomize and play around with a set of adjectives and nouns to come up with as many combinations of the same string as possible.Par exemple :What’s the difference between their ‘flagship model’ (GPT-5.1-Codex-Max) vs their ‘latest frontier agentic coding model’ (GPT-5.4) vs their model which is ‘optimized for professional work and long-running agents’ (GPT-5.2)?What’s the difference between models which are optimized for codex and those which are not?Are all Codex models optimized for Codex?It doesn’t seem so, at least just at a quick glance of the descriptions, 5.2-Codex does explicitly appear to be optimized for CodexWhat does the “Max” in GPT-5.1-Codex-Max actually stand for?Does it have a different context window limit?Is it Max because it is the best model?Are there any meaningful differences between the Codex and non-Codex version of a model like GPT-5.2?If so, where is that information and why is it not easily and accessibly provided in-app?1.1 …This isn’t even that hardMaybe most annoyingly, it’s not that something similar to this kind of model-by-model information break-down doesn’t already exist. OpenAI has something kind of like this.Figure 1.3 Proof that OpenAI already has the ‘describe what each of your models do and what they do differently’ capability and are simply choosing adversarially not to use it.Although even here, OpenAI does not seem to be consistent or particularly… helpful. For example, if you want a more intuitive design setup for comparing models, on a completely different page, the ‘Compare Models’ feature gives you a nicer-looking way to assess their models, complete with cute lightning & lightbulb icons.Figure 1.4 Comparison of 3 OpenAI models using the “Compare Models” part of their site.1.2 How to Write Bad DescriptionsBut this still isn’t really what I’m looking for. Notice how absolutely inconsistent, vague, and useless the descriptions even here on their own website (above) are:(Descriptions that contradict the serial/temporal order of their models) Why is GPT-5.2 the “previous frontier model” while GPT-5.2-Codex the “most intelligent coding model” despite 5.3-Codex already also existing? Is the implication that 5.2-Codex is actually still the best coding model for agentic tasks?Or did they just forget?(Descriptions for one model that really apply to all models)Why is GPT-5.2 described as having “configurable reasoning effort” when all 3 of the models have configurable reasoning effort?(Naming schemes that may or may not indicate some special quality or difference)Should one take it, from the name/suffix “Max”, that GPT-5.1-Codex-Max remains their best coding model for long-running tasks?2. Proposed FixWhat none of us want: OpenAI NOT to further reduce the range of model options/offerings to the end user or implement another model auto-router into Codex.What I’d like: for the simple one-sentence model descriptions in Codex to actually be useful by describing what makes a specific model distinct from the others—beyond just the obvious fact that newer models are probably ‘better’ at coding.e.g. A short 1-2 line sentence that answers the obvious question: why have they kept some of the other older models around? Is GPT-5.1-Codex-Max better at long context coding tasks, but GPT-5.2 Codex is better at coding in general (or for short tasks)?Is GPT-5.2 the better model at planning, abstract reasoning, and math and hence the model you should use when first drafting up a plan for a large project? Whereas GPT-5.2-Codex is better at agentic coding tasks, general SWE, and visual reasoning so that it is better at frontend/UI design but not [something else]?Is GPT-5.3-Codex slightly better at debugging that 5.2-Codex, but 5.2-Codex remains the superior model for writing code?In Short: Don’t just describe the models—and don’t even bother if you’re going to do them this badly—but describe what makes each model different.[2](Request)Does anyone actually know what the differences between all of these models are? Also can someone with a lot of diverse experience using these models maybe chime in and provide some thoughts and opinions on ‘what each model is like’ and how the models differ from each other?In particular, I’m curious to know if anyone has had experiences using GPT-5.1-Codex-Max and whether it differs in ability, speed, efficiency, or personality from any of the other models, given that it stands out as the only model that has been blessed with the ‘Max’ prefix.^Does anyone remember when this literally used to be one single click for a drop-down menu?^Come on guys, this isn’t really that hard.Discuss Read More
What Are with All the Different GPT-5 Variants in Codex and How Are They Actually Different? (or are they even?)
OpenAI has been consistently making it hard to understand what each of their different models are for. Frustratingly, their approach—as indicated by their recent UI decisions in the webapp to hide all settings for model reasoning effort and even the actual model name/type itself under: first, a collapsible element, and then, second, a second-up button for a pop-up menu, which then hides all of their other models (besides the latest) under a third collapsible element/button—to such complaints seems to almost always be to make things even less transparent by hiding even more things behind the UI.Figure 1.1 What it takes now to (a) find what model OpenAI is making you use, (b) how much reasoning effort it is using, (c) change to an actually useful, older reasoning model like o3 that actually reasons, as opposed to ‘adaptively’ only doing so when it can spare compute.[1] 1. Issues/ComplaintsFigure 1.2 What you see on the Codex app when you hover over each model to make its description appear.The short one-liner descriptions in the Codex App that describe each model are really vague and unclear and do not give any information on what each model’s unique value proposition is or what they ‘do best’—which would help a user understand what they ‘do different’ from any of the other models.All of the descriptions just seem like word salads or like someone fed an LLM a prompt to randomize and play around with a set of adjectives and nouns to come up with as many combinations of the same string as possible.Par exemple :What’s the difference between their ‘flagship model’ (GPT-5.1-Codex-Max) vs their ‘latest frontier agentic coding model’ (GPT-5.4) vs their model which is ‘optimized for professional work and long-running agents’ (GPT-5.2)?What’s the difference between models which are optimized for codex and those which are not?Are all Codex models optimized for Codex?It doesn’t seem so, at least just at a quick glance of the descriptions, 5.2-Codex does explicitly appear to be optimized for CodexWhat does the “Max” in GPT-5.1-Codex-Max actually stand for?Does it have a different context window limit?Is it Max because it is the best model?Are there any meaningful differences between the Codex and non-Codex version of a model like GPT-5.2?If so, where is that information and why is it not easily and accessibly provided in-app?1.1 …This isn’t even that hardMaybe most annoyingly, it’s not that something similar to this kind of model-by-model information break-down doesn’t already exist. OpenAI has something kind of like this.Figure 1.3 Proof that OpenAI already has the ‘describe what each of your models do and what they do differently’ capability and are simply choosing adversarially not to use it.Although even here, OpenAI does not seem to be consistent or particularly… helpful. For example, if you want a more intuitive design setup for comparing models, on a completely different page, the ‘Compare Models’ feature gives you a nicer-looking way to assess their models, complete with cute lightning & lightbulb icons.Figure 1.4 Comparison of 3 OpenAI models using the “Compare Models” part of their site.1.2 How to Write Bad DescriptionsBut this still isn’t really what I’m looking for. Notice how absolutely inconsistent, vague, and useless the descriptions even here on their own website (above) are:(Descriptions that contradict the serial/temporal order of their models) Why is GPT-5.2 the “previous frontier model” while GPT-5.2-Codex the “most intelligent coding model” despite 5.3-Codex already also existing? Is the implication that 5.2-Codex is actually still the best coding model for agentic tasks?Or did they just forget?(Descriptions for one model that really apply to all models)Why is GPT-5.2 described as having “configurable reasoning effort” when all 3 of the models have configurable reasoning effort?(Naming schemes that may or may not indicate some special quality or difference)Should one take it, from the name/suffix “Max”, that GPT-5.1-Codex-Max remains their best coding model for long-running tasks?2. Proposed FixWhat none of us want: OpenAI NOT to further reduce the range of model options/offerings to the end user or implement another model auto-router into Codex.What I’d like: for the simple one-sentence model descriptions in Codex to actually be useful by describing what makes a specific model distinct from the others—beyond just the obvious fact that newer models are probably ‘better’ at coding.e.g. A short 1-2 line sentence that answers the obvious question: why have they kept some of the other older models around? Is GPT-5.1-Codex-Max better at long context coding tasks, but GPT-5.2 Codex is better at coding in general (or for short tasks)?Is GPT-5.2 the better model at planning, abstract reasoning, and math and hence the model you should use when first drafting up a plan for a large project? Whereas GPT-5.2-Codex is better at agentic coding tasks, general SWE, and visual reasoning so that it is better at frontend/UI design but not [something else]?Is GPT-5.3-Codex slightly better at debugging that 5.2-Codex, but 5.2-Codex remains the superior model for writing code?In Short: Don’t just describe the models—and don’t even bother if you’re going to do them this badly—but describe what makes each model different.[2](Request)Does anyone actually know what the differences between all of these models are? Also can someone with a lot of diverse experience using these models maybe chime in and provide some thoughts and opinions on ‘what each model is like’ and how the models differ from each other?In particular, I’m curious to know if anyone has had experiences using GPT-5.1-Codex-Max and whether it differs in ability, speed, efficiency, or personality from any of the other models, given that it stands out as the only model that has been blessed with the ‘Max’ prefix.^Does anyone remember when this literally used to be one single click for a drop-down menu?^Come on guys, this isn’t really that hard.Discuss Read More
Related Posts

Give Skepticism a Try
Published on January 3, 2026 8:57 AM GMTPhilosophy has a weird relationships with skepticism. On…
Myopia Mythology
Published on November 8, 2025 10:22 PM GMTIt's been a while since I wrote about…
An introduction to modular induction and some attempts to solve it
Published on December 23, 2025 10:35 PM GMTThe current crop of AI systems appears to…