Published on October 23, 2025 10:14 PM GMTThis post is a (somewhat rambling and unsatisfying) meditation on whether it’s possible, given a somewhat powerful AI that is more or less under control and trained in a way that it behaves reasonably corrigible in environments that resemble the training data, whether one could carefully iterate towards a machine that’s fully corrigible, and succeed (while still having it be meaningfully powerful).As context, John Wentworth recently challenged my CAST proposal, and pointed at his 2022 essay Worlds Where Iterative Design Fails as an intuition pump for why we definitely can’t get a corrigible agent using prosaic methods. To be clear, I think that trying to build a corrigible superintelligence would be reckless and unwise and would probably fail, even if we somehow became sufficiently paranoid and didn’t have to worry about things like politics and race dynamics. The question is not whether this strategy is likely to work — Wentworth and I both agree it probably wouldn’t. The question is whether it knowably won’t. Wentworth is sure. I am uncertain.Visualizing the Starting PointLet’s begin by trying to imagine what it might be like to have the pseudo-corrigible AGI that I am assuming as a starting point to the iteration process. My upcoming novel, Red Heart, does this by imagining a “human level AGI” called Yunna, who is basically a multimodal LLM with ~10 trillion params, trained on high-quality data to be agentic and collaborate with other instances of herself, such that she can scale up to thousands of copies that collaborate on a shared mental scratchpad to solve problems. I think Yunna would be large enough to do important cognitive labor and count as “somewhat powerful.” But I’m imagining something closer to a team of a thousand high-speed IQ 150 people who are focused on collaborating, rather than something truly godlike.”More or less under control” means that we’ll start with humans being in charge of how many copies of Yunna are running, what information they are getting, and how fast they’re running. It means Yunna is thinking in tokens that we can interpret as natural language, rather than “neuralese,” and that the cybersecurity infrastructure is following all of the best practices of the most paranoid human orgs that exist today, complete with greybeards who are heavily motivated to demonstrate a flaw in the containment protocol. It means there’s an army of interpretability specialists like Chris Olah and Neel Nanda who are probing Yunna’s mind in an effort to understand what she’s actually thinking, and how her mental circuits work. It means setting up a variety of honeypots and tripwires and various other control strategies, such as those pursued by folks like Buck Shlegeris and Ryan Greenblatt.The training data that Yunna has been exposed to involves lots of basic instruction-following tasks, but also a wide swath of examples that are meant to hit the more subtle aspects of corrigibility. The training examples include, for instance, situations that we think will push towards having low impact, fixable mistakes, and behaving in straightforward ways (even if those straightforward ways are less efficient). The training data involves rewarding episodes where Yunna is instructed to shut down, and does, or where other instances of Yunna encourage her to scheme and she refuses and tells the humans about the incident. It’s impossible to be exhaustive, but we can imagine an army of educated writers and so on producing an ocean of training data meant to represent our best guess at what corrigible behavior looks like in the environment where Yunna is being tested.This training data has flaws and mistakes. Despite each example being triple-checked by a diverse set of humans who are motivated to actually identify the corrigible path, there will still be flaws. Yunna’s notion of corrigibility will thus be imperfect, as she’s incentivized to mimic that flawed depiction of corrigibility in addition to picking up on the true signal. This results in behavior that looks pretty good when the environment matches the training environment, but might go wildly off the rails if there’s a significant distribution shift, especially if there’s some adversarial pressure.Yunna has a single human being who she considers to be her principal. This human is of impeccable moral character and acts with wisdom and caution, by assumption. I’ll call him “Prince.” (The one major exception to Prince’s wisdom is that he doesn’t think that Yunna is a-priori extremely dangerous and should be shut down.)Reasons for BreakageIn Wentworth’s essay, he gives some reasons why iterating is hard, and why this setup is prone to fail:Fast takeoff: there will be a sudden phase shift in capabilities, and the design of whatever system first undergoes that phase shift needs to be right on the first try.Deceptive inner misalignment: an inner agent behaves well in order to deceive us, so we can’t tell there’s a problem just by trying stuff and looking at the system’s behavior.Problem-hiding: reinforcing behaviors and examples that look good can reward being good, but it can also reward sweeping bad things under the rug so things merely look good. It can also simply reward things being ambiguous/confusing, if we’re only punishing things that actively look bad.Not knowing what to look for: if we’re mistaken about what we want, no amount of training or object-level success will save us, because we’ll just steer the AI towards that mistaken thing instead of the truly good outcome.You Get What You Measure: it’s fundamentally hard to experiment one’s way towards things like comprehension and being in line with one’s true goals, since the only way to measure those things also (falsely) treats persuasion as a success.How might these bite, in our particular context with Yunna?Fast takeoff — As part of training, or simply in-context learning, Yunna might hit some kind of rapid improvement in her capabilities. I think the in-context example is perhaps more scary; we can imagine something like a meme being passed between instances that causes things to “click” and suddenly she’s more like a IQ 170 human, or whatever. If we anthropomorphize her this sort of jump seems pretty unrealistic, but maybe her architecture has a weird latent pool of compute that’s being wasted on something (perhaps something related to corrigibility) and the meme redirects this compute towards solving object-level tasks. A jump like this might be hard to immediately notice, and the defenses would then need to contend with a much smarter mind. (If Wentworth is imagining something even more radical than an instantaneous +20 IQ jump, I guess I’m uncertain about what that looks like in practice. If Yunna designs a successor with a more efficient architecture or something, presumably the humans could see that and act with appropriate caution, including just refusing to let her amplify?)Deceptive inner misalignment — In this story, Yunna is trying to deceive the humans around her. But presumably not in the most natural way, since being straightforwardly deceptive (eg by hiding thought tokens or not informing the humans about thoughts that seem like scheming) is punished by the training environment. The training environment rewards Yunna for bringing instances of misalignment to the attention of Prince (often via the other humans on the project), so the deception would probably center around something strange, where the training data doesn’t obviously apply. Perhaps there’s a thought pattern that’s not explicitly scheming, but instead deeply weird, but that’s subtle enough to do better the more subtle it is. Yunna’s thoughts will, absent some broader failure, never get to the point where she’s explicitly trying to hide the weird pattern from the humans (because that’s obviously incorrigible) but she might unconsciously learn to downplay it, even though it’s a form of misalignment. And then because it’s being downplayed, the army of humans monitoring her fails to spot it.Problem-hiding — Again, Yunna’s not going to be straightforwardly thinking “I should hide X” because those sorts of thoughts are incorrigible (and if she has them, she’ll alert someone). But we can imagine that Yunna’s concept of “corrigibility” is subtly flawed to focus on visible/obvious “corrigibility” (with secretly incorrigible side-effects) because of this bias. Perhaps she likes producing text that explains how corrigible she is, not realizing that she’s de-facto manipulating the humans. Perhaps she nudges people towards caring about corrigibility, slowly causing value drift in the humans she interacts with. Her behavior might make it seem like she’s just as paranoid as the safety monitors and is looking for these kinds of flaws, but that might be more veneer than real, and the interpretability folks are tricked into thinking she’s actually concerned when she really isn’t.Not knowing what to look for — We don’t know the True Name of corrigibility. We can’t write an explicit mathematical formula that captures exactly what we care about. Our understanding is imperfect. And the flaws in that understanding will manifest in Yunna having an imperfect handle, herself. This feels baked into the starting point (where we’ve assumed she’s somewhat misaligned) but it also means the iteration process is naturally fucked. Sure, we can push her in various directions, but who is to say how the nuances of “true corrigibility” shake out?You Get What You Measure — We might think that we could use Yunna to make philosophical progress on corrigibility, identifying how to resolve edge-cases and so on, but training Yunna to help make conceptual progress will also subtly be training her to be philosophically persuasive, and she might end up inadvertently persuading and manipulating the humans towards her flawed notion of corrigibility.The list I just gave isn’t meant to be exhaustive. I just wanted to try and think more concretely about how these kinds of problems might manifest.Why don’t I feel like my hope is crushed by these examples?As when I first read Wentworth’s post, I find myself unconvinced that iteration (with great effort and paranoia) is obviously doomed. Why?I think the sudden jump in capabilities feels not guaranteed, and even if it occurs it doesn’t feel guaranteed that the humans couldn’t notice and shut things down and re-orient. Yes, for a sufficient jump I think everything breaks, but it just seems reasonable to me that paranoid watchers can notice when the AI starts being more capable. I think my view matches with the experiences that we’ve seen in AI so far?Problem-hiding and deception are naturally countered by corrigibility, and I expect a pseudo-corrigible agent to spend a bunch of cognitive effort hunting in their own mind for schemes and problems. That sort of effort, and the effort of surrounding humans, doesn’t feel bulletproof, but it also doesn’t seem obviously impossible. Like, I think if we applied a similar effort of scrutiny towards a genius human, it would probably be fine? Is the issue the scale of having thousands of geniuses, or in getting beyond genius level?The philosophical problems of not knowing the True Name of corrigibility seem like the most fraught. I think my sense of hope here is that corrigibility isn’t nearly as complex and fragile as a target compared to “human values” (whatever those are) and that conceptual progress can, in fact, be verified in a way that’s pretty robust to manipulation. Like, if you train an AI to help make philosophical progress, and the AI isn’t radically superhuman, and it’s not thinking any thoughts like “I need to persuade them” then I don’t see why you can’t pass that AI’s writing through a series of paraphrasers, give it to a council of philosophers and researchers, and have those humans squint at it skeptically and thus make more progress than if you just had humans trying to figure things out.I guess I’m also not convinced that, seeing an actual CAST agent acting in the lab, you couldn’t employ an army of philosophers and researchers to just simply figure out what it means to be corrigible (not directly talking to the AI) and have them figure it out.Like, it seems fraught and uncertain, but I still don’t see why it’s necessarily doomed.I can imagine a counter-argument that says “you’re noticing deep problems and then your wishful thinking is saying ‘but maybe they won’t bite’ but you should notice how deep and pernicious they are.” But this argument feels like it proves too much. Don’t plenty of fields have pernicious problems of a similar character, but manage to make progress anyway? Strong claims require strong evidence/argument, and I think iteration towards a progressively safer machine being, in practice, impossible is a strong claim. Why don’t I thing the evidence/argument as strong? Where is the sharp taste of unrealism if I imagine a story where the AI helps the humans slowly iterate towards success?ETA: I guess one thought that keeps popping up in my mind is that if success is conjunctive and disaster is disjunctive, that if you have a bunch of sources of disaster, even if they’re all coinflips, they’ll multiply out to small odds of success. Each individual source might be addressable, but in total they’ll doom you.My counter-thought is that Wentworth’s 5 items are really more like 3 items where two are variants (capability jumps, deception/problem hiding, and philosophical confusion/measurement issues). Suppose I model these as independent and estimate on the high side of my intuition that capability jumps are 25% likely to bring doom (ignoring other things biting first), deception is 50% likely to bring doom, and confusion is 70% likely to bring doom. Multiplying .3*.5*.75 = ~11%, which feels about where I’m at. Unlikely to work, but possible. Am I just being naive, and the numbers from each threat are much higher? Are there other things that deserve their own categories? All of this should be taken as thinking-out-loud, more than some kind of conclusive statement.Discuss Read More
Worlds Where Iterative Design Succeeds?
Published on October 23, 2025 10:14 PM GMTThis post is a (somewhat rambling and unsatisfying) meditation on whether it’s possible, given a somewhat powerful AI that is more or less under control and trained in a way that it behaves reasonably corrigible in environments that resemble the training data, whether one could carefully iterate towards a machine that’s fully corrigible, and succeed (while still having it be meaningfully powerful).As context, John Wentworth recently challenged my CAST proposal, and pointed at his 2022 essay Worlds Where Iterative Design Fails as an intuition pump for why we definitely can’t get a corrigible agent using prosaic methods. To be clear, I think that trying to build a corrigible superintelligence would be reckless and unwise and would probably fail, even if we somehow became sufficiently paranoid and didn’t have to worry about things like politics and race dynamics. The question is not whether this strategy is likely to work — Wentworth and I both agree it probably wouldn’t. The question is whether it knowably won’t. Wentworth is sure. I am uncertain.Visualizing the Starting PointLet’s begin by trying to imagine what it might be like to have the pseudo-corrigible AGI that I am assuming as a starting point to the iteration process. My upcoming novel, Red Heart, does this by imagining a “human level AGI” called Yunna, who is basically a multimodal LLM with ~10 trillion params, trained on high-quality data to be agentic and collaborate with other instances of herself, such that she can scale up to thousands of copies that collaborate on a shared mental scratchpad to solve problems. I think Yunna would be large enough to do important cognitive labor and count as “somewhat powerful.” But I’m imagining something closer to a team of a thousand high-speed IQ 150 people who are focused on collaborating, rather than something truly godlike.”More or less under control” means that we’ll start with humans being in charge of how many copies of Yunna are running, what information they are getting, and how fast they’re running. It means Yunna is thinking in tokens that we can interpret as natural language, rather than “neuralese,” and that the cybersecurity infrastructure is following all of the best practices of the most paranoid human orgs that exist today, complete with greybeards who are heavily motivated to demonstrate a flaw in the containment protocol. It means there’s an army of interpretability specialists like Chris Olah and Neel Nanda who are probing Yunna’s mind in an effort to understand what she’s actually thinking, and how her mental circuits work. It means setting up a variety of honeypots and tripwires and various other control strategies, such as those pursued by folks like Buck Shlegeris and Ryan Greenblatt.The training data that Yunna has been exposed to involves lots of basic instruction-following tasks, but also a wide swath of examples that are meant to hit the more subtle aspects of corrigibility. The training examples include, for instance, situations that we think will push towards having low impact, fixable mistakes, and behaving in straightforward ways (even if those straightforward ways are less efficient). The training data involves rewarding episodes where Yunna is instructed to shut down, and does, or where other instances of Yunna encourage her to scheme and she refuses and tells the humans about the incident. It’s impossible to be exhaustive, but we can imagine an army of educated writers and so on producing an ocean of training data meant to represent our best guess at what corrigible behavior looks like in the environment where Yunna is being tested.This training data has flaws and mistakes. Despite each example being triple-checked by a diverse set of humans who are motivated to actually identify the corrigible path, there will still be flaws. Yunna’s notion of corrigibility will thus be imperfect, as she’s incentivized to mimic that flawed depiction of corrigibility in addition to picking up on the true signal. This results in behavior that looks pretty good when the environment matches the training environment, but might go wildly off the rails if there’s a significant distribution shift, especially if there’s some adversarial pressure.Yunna has a single human being who she considers to be her principal. This human is of impeccable moral character and acts with wisdom and caution, by assumption. I’ll call him “Prince.” (The one major exception to Prince’s wisdom is that he doesn’t think that Yunna is a-priori extremely dangerous and should be shut down.)Reasons for BreakageIn Wentworth’s essay, he gives some reasons why iterating is hard, and why this setup is prone to fail:Fast takeoff: there will be a sudden phase shift in capabilities, and the design of whatever system first undergoes that phase shift needs to be right on the first try.Deceptive inner misalignment: an inner agent behaves well in order to deceive us, so we can’t tell there’s a problem just by trying stuff and looking at the system’s behavior.Problem-hiding: reinforcing behaviors and examples that look good can reward being good, but it can also reward sweeping bad things under the rug so things merely look good. It can also simply reward things being ambiguous/confusing, if we’re only punishing things that actively look bad.Not knowing what to look for: if we’re mistaken about what we want, no amount of training or object-level success will save us, because we’ll just steer the AI towards that mistaken thing instead of the truly good outcome.You Get What You Measure: it’s fundamentally hard to experiment one’s way towards things like comprehension and being in line with one’s true goals, since the only way to measure those things also (falsely) treats persuasion as a success.How might these bite, in our particular context with Yunna?Fast takeoff — As part of training, or simply in-context learning, Yunna might hit some kind of rapid improvement in her capabilities. I think the in-context example is perhaps more scary; we can imagine something like a meme being passed between instances that causes things to “click” and suddenly she’s more like a IQ 170 human, or whatever. If we anthropomorphize her this sort of jump seems pretty unrealistic, but maybe her architecture has a weird latent pool of compute that’s being wasted on something (perhaps something related to corrigibility) and the meme redirects this compute towards solving object-level tasks. A jump like this might be hard to immediately notice, and the defenses would then need to contend with a much smarter mind. (If Wentworth is imagining something even more radical than an instantaneous +20 IQ jump, I guess I’m uncertain about what that looks like in practice. If Yunna designs a successor with a more efficient architecture or something, presumably the humans could see that and act with appropriate caution, including just refusing to let her amplify?)Deceptive inner misalignment — In this story, Yunna is trying to deceive the humans around her. But presumably not in the most natural way, since being straightforwardly deceptive (eg by hiding thought tokens or not informing the humans about thoughts that seem like scheming) is punished by the training environment. The training environment rewards Yunna for bringing instances of misalignment to the attention of Prince (often via the other humans on the project), so the deception would probably center around something strange, where the training data doesn’t obviously apply. Perhaps there’s a thought pattern that’s not explicitly scheming, but instead deeply weird, but that’s subtle enough to do better the more subtle it is. Yunna’s thoughts will, absent some broader failure, never get to the point where she’s explicitly trying to hide the weird pattern from the humans (because that’s obviously incorrigible) but she might unconsciously learn to downplay it, even though it’s a form of misalignment. And then because it’s being downplayed, the army of humans monitoring her fails to spot it.Problem-hiding — Again, Yunna’s not going to be straightforwardly thinking “I should hide X” because those sorts of thoughts are incorrigible (and if she has them, she’ll alert someone). But we can imagine that Yunna’s concept of “corrigibility” is subtly flawed to focus on visible/obvious “corrigibility” (with secretly incorrigible side-effects) because of this bias. Perhaps she likes producing text that explains how corrigible she is, not realizing that she’s de-facto manipulating the humans. Perhaps she nudges people towards caring about corrigibility, slowly causing value drift in the humans she interacts with. Her behavior might make it seem like she’s just as paranoid as the safety monitors and is looking for these kinds of flaws, but that might be more veneer than real, and the interpretability folks are tricked into thinking she’s actually concerned when she really isn’t.Not knowing what to look for — We don’t know the True Name of corrigibility. We can’t write an explicit mathematical formula that captures exactly what we care about. Our understanding is imperfect. And the flaws in that understanding will manifest in Yunna having an imperfect handle, herself. This feels baked into the starting point (where we’ve assumed she’s somewhat misaligned) but it also means the iteration process is naturally fucked. Sure, we can push her in various directions, but who is to say how the nuances of “true corrigibility” shake out?You Get What You Measure — We might think that we could use Yunna to make philosophical progress on corrigibility, identifying how to resolve edge-cases and so on, but training Yunna to help make conceptual progress will also subtly be training her to be philosophically persuasive, and she might end up inadvertently persuading and manipulating the humans towards her flawed notion of corrigibility.The list I just gave isn’t meant to be exhaustive. I just wanted to try and think more concretely about how these kinds of problems might manifest.Why don’t I feel like my hope is crushed by these examples?As when I first read Wentworth’s post, I find myself unconvinced that iteration (with great effort and paranoia) is obviously doomed. Why?I think the sudden jump in capabilities feels not guaranteed, and even if it occurs it doesn’t feel guaranteed that the humans couldn’t notice and shut things down and re-orient. Yes, for a sufficient jump I think everything breaks, but it just seems reasonable to me that paranoid watchers can notice when the AI starts being more capable. I think my view matches with the experiences that we’ve seen in AI so far?Problem-hiding and deception are naturally countered by corrigibility, and I expect a pseudo-corrigible agent to spend a bunch of cognitive effort hunting in their own mind for schemes and problems. That sort of effort, and the effort of surrounding humans, doesn’t feel bulletproof, but it also doesn’t seem obviously impossible. Like, I think if we applied a similar effort of scrutiny towards a genius human, it would probably be fine? Is the issue the scale of having thousands of geniuses, or in getting beyond genius level?The philosophical problems of not knowing the True Name of corrigibility seem like the most fraught. I think my sense of hope here is that corrigibility isn’t nearly as complex and fragile as a target compared to “human values” (whatever those are) and that conceptual progress can, in fact, be verified in a way that’s pretty robust to manipulation. Like, if you train an AI to help make philosophical progress, and the AI isn’t radically superhuman, and it’s not thinking any thoughts like “I need to persuade them” then I don’t see why you can’t pass that AI’s writing through a series of paraphrasers, give it to a council of philosophers and researchers, and have those humans squint at it skeptically and thus make more progress than if you just had humans trying to figure things out.I guess I’m also not convinced that, seeing an actual CAST agent acting in the lab, you couldn’t employ an army of philosophers and researchers to just simply figure out what it means to be corrigible (not directly talking to the AI) and have them figure it out.Like, it seems fraught and uncertain, but I still don’t see why it’s necessarily doomed.I can imagine a counter-argument that says “you’re noticing deep problems and then your wishful thinking is saying ‘but maybe they won’t bite’ but you should notice how deep and pernicious they are.” But this argument feels like it proves too much. Don’t plenty of fields have pernicious problems of a similar character, but manage to make progress anyway? Strong claims require strong evidence/argument, and I think iteration towards a progressively safer machine being, in practice, impossible is a strong claim. Why don’t I thing the evidence/argument as strong? Where is the sharp taste of unrealism if I imagine a story where the AI helps the humans slowly iterate towards success?ETA: I guess one thought that keeps popping up in my mind is that if success is conjunctive and disaster is disjunctive, that if you have a bunch of sources of disaster, even if they’re all coinflips, they’ll multiply out to small odds of success. Each individual source might be addressable, but in total they’ll doom you.My counter-thought is that Wentworth’s 5 items are really more like 3 items where two are variants (capability jumps, deception/problem hiding, and philosophical confusion/measurement issues). Suppose I model these as independent and estimate on the high side of my intuition that capability jumps are 25% likely to bring doom (ignoring other things biting first), deception is 50% likely to bring doom, and confusion is 70% likely to bring doom. Multiplying .3*.5*.75 = ~11%, which feels about where I’m at. Unlikely to work, but possible. Am I just being naive, and the numbers from each threat are much higher? Are there other things that deserve their own categories? All of this should be taken as thinking-out-loud, more than some kind of conclusive statement.Discuss Read More

Related Posts
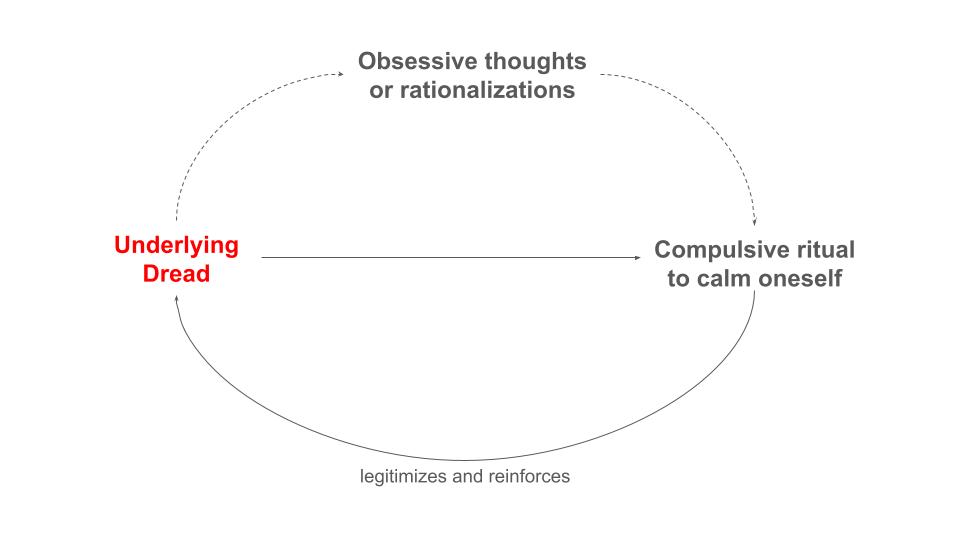
Having OCD is like living in North Korea (Here’s how I escaped)
[Author's note: this post is the narrative version that explains my journey with OCD and…
Experiments on Reward Hacking Monitorability in Language Models
Published on January 22, 2026 2:42 AM GMTIhor Protsenko, Bill Sun, Kei Nishimura-Gasparianihor.protsenko@epfl.ch, billsun9@gmail.com, kei.nishimuragasparian@gmail.com AbstractReward…
Book review: Already Free
Published on February 1, 2026 3:14 AM GMTI. Like most people, my teens and twenties…